



はじめに
先日、RAG(Retrieval Augmented Generation)に関する勉強会で、LangChainを利用したRAGの回答精度を評価するツール「Ragas」の話を聞きました。
生成AIが作成する結果を一つずつユーザーが評価できれば理想的だとは思いますが、回答結果が膨大な場合、すべてを評価するのは現実的ではありません。
そこで、RAGの性能を計測するフレームワークである「Ragas」を用いてハンズオンを行い、回答精度を評価する方法を理解することを試みました。
Ragasとは?
Ragasとは、Pythonで利用できるRAG(Retrieval Augmented Generation)の性能計測を実現するフレームワークです。
検索と生成の性能を評価するための専用メトリクスを提供しており、RAGアプリケーションの開発および改善に役立てることができます。
Ragas v0.2.0では、大幅なアップデートが行われ、RAGだけでなく、エージェントによる生成内容や会話型システムの評価にも対応しました。
これにより、Ragasは、RAGからエージェントまで幅広い生成AIアプリケーションの性能を測定することが可能となりました。
GitHubリポジトリ:ragas
Ragasの評価指標に関する概要
目的
生成AIアプリケーションの品質を評価するためのフレームワークで、信頼性の高い結果を提供するために設計されている。
利用されるメトリクス
メトリクスは大きく2つのカテゴリに分類され、生成AIの性能を評価する。
以下の図は、Ragasのメトリクスを大別した図である。
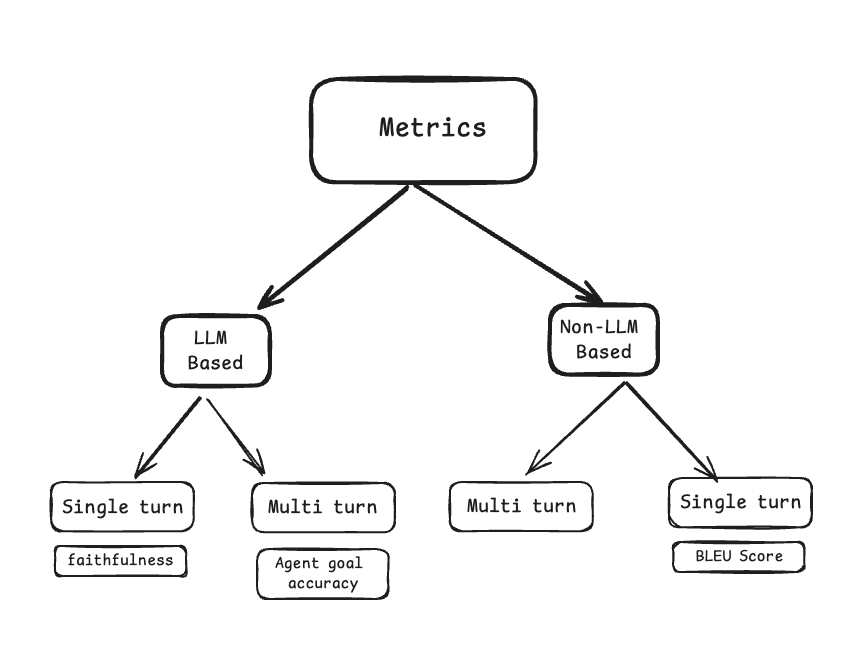

| 分類 | サブ分類 | 説明 |
|---|---|---|
| LLMベース | 評価を行うために LLMを使用するメトリクス。常に同じ結果を返すとは限らないが、人間の評価との相関性が高い傾向にある。 | |
| シングルターン | ユーザーとAI間の1回のやり取り(1ターン)に基づいてAIアプリケーションのパフォーマンスを評価 | |
| マルチターン | ユーザーとAI間の複数回のやり取り(複数ターン)に基づいてAIアプリケーションのパフォーマンスを評価 | |
| 非LLMベース | 評価を行うために LLMを使用しないメトリクス。常に同じ結果を返すが、人間の評価との相関性は低い傾向にある。 | |
| シングルターン | 文字列比較や統計的手法などを利用して評価 | |
| マルチターン | – |
Ragasが提供する評価指数(2025/01/26時点)
評価したい対象に対して、以下メトリクスを利用することで、生成AIの性能を定量的に評価することが可能となる。
| 項番 | 分類 | 指標 | 説明 |
|---|---|---|---|
| 1 | RAG 検索 (Retrieval) | Context Precision | 検索によって取得された文脈情報が、質問に対してどれだけ関連性が高く、ノイズ(不要な情報)が少ないかを評価します。 |
| 2 | Context Recall | 質問に答えるために必要な情報が、検索によって漏れなく取得できているかを評価します。 | |
| 3 | Context Entities Recall | 取得された文脈情報に含まれる重要なエンティティが、質問に関連するものが正確に取得されているかを評価します。 | |
| 4 | Noise Sensitivity | 検索結果に含まれる不要な情報(ノイズ)が、最終的な結果(回答)にどれだけ影響を与えるかを評価します。 | |
| 5 | RAG 生成 (Generation) | Response Relevancy | 質問に対して生成された回答が、どれだけ適切に関連しているかを評価します。 |
| 6 | Faithfulness | 生成された回答が、どれだけ事実に基づいており、誤解や誤情報を含まないかを評価します。 | |
| 7 | マルチモーダル (Multimodal) | Multimodal Faithfulness | マルチモーダルを用いた生成結果が、提示された情報に対してどれだけ忠実であるかを評価します。 |
| 8 | Multimodal Relevance | マルチモーダル情報を用いて生成された結果が、元の質問に対してどれだけ適切に関連しているかを評価します。 | |
| 9 | エージェント/ツール利用 | Topic adherence | エージェントやツールが、与えられたトピックやタスクにどれだけ忠実に従っているかを評価します。 |
| 10 | Tool call Accuracy | エージェントが適切なツールを正確に呼び出せているかを評価します。 | |
| 11 | Agent Goal Accuracy | エージェントが設定された目標をどれだけ正確に達成できているかを評価します。 | |
| 12 | 自然言語比較 | Factual Correctness | 生成されたテキストが事実として正しいかどうかを評価します。 |
| 13 | Semantic Similarity | 2つのテキストの意味的な類似性を評価します。 | |
| 14 | Non LLM String Similarity | LLMを使用しない文字列ベースの類似性評価(例:編集距離、Jaccard係数など)。 | |
| 15 | BLEU Score | 機械翻訳の評価でよく用いられる、生成されたテキストと正解テキストのn-gramの一致度に基づくスコア。 | |
| 16 | ROUGE Score | 要約の評価でよく用いられる、生成されたテキストと正解テキストの単語やフレーズの重複度に基づくスコア。 | |
| 17 | String Presence | 特定の文字列が生成されたテキストに存在するかどうかを評価します。 | |
| 18 | Exact Match | 生成されたテキストが正解テキストと完全に一致するかどうかを評価します。 | |
| 19 | SQL | Execution based Datacompy Score | SQLクエリの実行結果を比較し、データの一致度を評価します。Datacompyなどのツールを使用。 |
| 20 | SQL query Equivalence | 2つのSQLクエリが論理的に等価であるかどうかを評価します。 | |
| 21 | 汎用評価 | Aspect critic | 特定の側面(例:流暢さ、正確さ、簡潔さ)に基づいてテキストを評価します。 |
| 22 | Simple Criteria Scoring | 事前に定義された簡単な基準に基づいてスコアリングを行います。 | |
| 23 | Rubrics based scoring | 評価ルーブリック(評価基準表)に基づいてスコアリングを行います。 | |
| 24 | Instance specific rubrics scoring | 特定のインスタンス(事例)に合わせてカスタマイズされたルーブリックに基づいてスコアリングを行います。 | |
| 25 | その他のタスク | Summarization | 要約の品質を評価するための指標(ROUGEなど)。 |
ハンズオン
処理フロー
以下の順番で処理が実行される。
| 項番 | 処理項目 | 処理内容 |
|---|---|---|
| 1 | WEBクローラ(文脈取得) | 指定されたURL(私のブログ)からテキスト部分を抽出(=文脈テキスト) |
| 2 | 要約生成 | 取得した文脈テキストをBedrockのLLM(Nova micro)で、要約を生成。要約だけでなく、ポジティブなフィードバックを50文字以内で記述するように指示。 |
| 3 | Ragasによる評価 | 生成された要約と文脈テキストをRagasで評価 |
1.構築手順
1-1.環境構築
Amazon SageMaker Studio Code Editor での 検証環境構築手順でAmazon SageMaker Studio Code Editorの準備
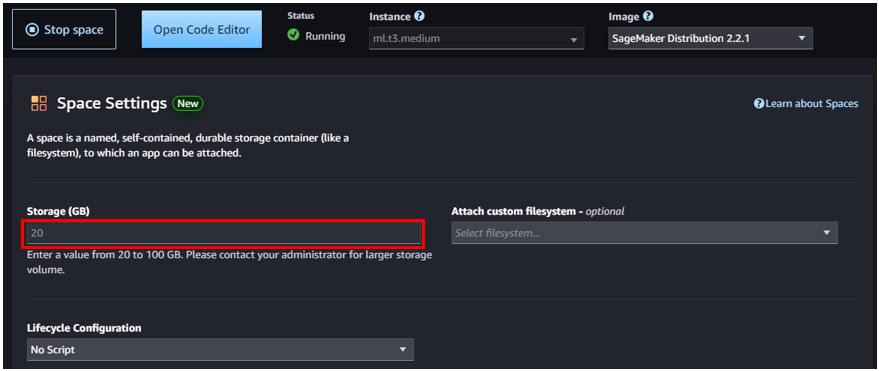
※「Ragas」等のインストールの都合で、デフォルトの5GBでは容量が足りなくなるため、下記赤枠部分のStorage(GB)を20GBに変更して起動する。

1-2.IAMロールに「AmazonBedrockFullAccess」アタッチ
デフォルトの SageMaker Domain に Bedrockのフル権限をアタッチ
※本検証ではPoCのためフル権限を付与していますが、本番環境では必要最小限の権限を持つIAMポリシーを作成し、アタッチすることを推奨。


1-3.モデルアクセスの許可
1.Bedrock 左ペインの「Bedrock configurations」移動
2.利用モデルごとに「アクセス」を許可
利用リージョン
| No. | リージョン名 | リージョンID |
|---|---|---|
| 1 | 米国東部 (バージニア北部) | us-east-1 |
利用モデル
| No. | 役割 | 利用ベースモデル | 目的 |
|---|---|---|---|
| 1 | 要約LLM | amazon.nova-micro-v1:0 | WEBサイトの要約 |
| 2 | 評価LLM | amazon.nova-pro-v1:0 | Ragasによる評価(特にfaithfulness、answer_relevancyなどのLLMベースの指標の算出) |
| 3 | 埋め込み | Titan Text Embeddings V2 | Ragasによる評価(文脈と要約の意味的な比較。faithfulness、answer_relevancyなどのLLMベースの指標の算出に利用) |
2.Code Editorでの準備
ターミナルを利用して事前準備実施
2-1.仮想環境作成
mkdir ${ProjectName}
cd ${ProjectName}
python3 -m venv .venv
source .venv/bin/activate 2-2.requirements.txt の作成
beautifulsoup4
requests
boto3
langchain
ragas
datasets
langchain-aws2-3.ライブラリの準備
pip install -r requirements.txt3.アプリケーションコード
以下にアプリケーションコードを示します。
3-1.アプリケーションコード全量
import requests
from bs4 import BeautifulSoup
import boto3
import json
from langchain_aws import ChatBedrock, BedrockEmbeddings
from ragas import evaluate
from ragas.metrics import RougeScore, faithfulness, answer_relevancy
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from datasets import Dataset
import time
from botocore.exceptions import ClientError
# IAM ロールを使用しているため、認証情報の明示的な記述は不要
bedrock = boto3.client('bedrock-runtime', region_name="us-east-1")
# ragas評価用のLLM (amazon.nova-pro) と Embeddings
ragas_llm = ChatBedrock(model_id="amazon.nova-pro-v1:0", client=bedrock)
ragas_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v2:0", client=bedrock)
# ウェブサイトのクローリング
def crawl_website(url):
try:
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, "html.parser")
website_text = soup.get_text(strip=True)
print(f"取得したウェブサイトの文字数: {len(website_text)}")
return website_text
except requests.exceptions.RequestException as e:
print(f"ウェブサイトの取得に失敗しました: {e}")
return None
# Bedrockによる要約生成(リトライロジックを追加)
def generate_summary(text: str, model_id: str, client) -> str:
prompt_text = (
"あなたはブログのコメンテーターです。\n"
"ブログの内容を要約し、読者が読みたくなるようにポイントを簡潔に説明し、"
"ポジティブなフィードバックを50文字以内で記載してください。\n"
"文章は全体的に親しみやすいトーンを心がけ、絵文字を活用して柔らかい雰囲気にしてください。\n\n"
f"ブログ内容:\n{text}"
)
messages = [{"role": "user", "content": [{"text": prompt_text}]}]
request_body = {
"messages": messages,
}
max_retries = 5
retry_delay = 10
for attempt in range(max_retries):
try:
response = client.invoke_model(
modelId=model_id,
body=json.dumps(request_body),
accept="application/json",
contentType="application/json"
)
response_body = json.loads(response['body'].read().decode('utf-8'))
# 正しいレスポンス処理
output = response_body.get("output", {})
message = output.get("message", {})
content = message.get("content", [])
if content and len(content) > 0:
summary_text = content[0].get("text", "回答が取得できませんでした")
return summary_text.strip()
else:
return "回答が取得できませんでした (contentキーの形式が不正)"
except ClientError as e:
if e.response['Error']['Code'] == 'ThrottlingException':
print(f"スロットリング発生。{retry_delay}秒待機してリトライします... (試行回数 {attempt + 1}/{max_retries})")
time.sleep(retry_delay)
else:
print(f"Bedrock呼び出しでエラーが発生しました: {e}")
break
return "Bedrock呼び出しでエラーが発生しました"
# ragasによる評価
def evaluate_summary(website_text, summary):
dataset = Dataset.from_dict({
"question": ["ウェブサイトの要約"],
"answer": [summary],
"contexts": [[website_text]],
"ground_truths": [""],
"reference": [website_text],
})
try:
results = evaluate(
dataset,
metrics=[RougeScore(), faithfulness, answer_relevancy],
llm=LangchainLLMWrapper(ragas_llm),
embeddings=LangchainEmbeddingsWrapper(ragas_embeddings)
)
# 評価中の連続呼び出しを回避する目的で適宜スリープ
time.sleep(3)
return results
except Exception as e:
print(f"ragas評価でエラーが発生しました: {e}")
return None
if __name__ == "__main__":
url = "https://cloud5.jp/send-summary-to-line-novamicro/"
website_text = crawl_website(url)
if website_text:
# 要約生成に amazon.nova-micro-v1:0 を指定
summary = generate_summary(website_text, "amazon.nova-micro-v1:0", bedrock)
if summary:
print(f"生成された要約:\n{summary}")
results = evaluate_summary(website_text, summary)
if results:
print("ragasの評価結果:\n", results)
4.実行
4.1.実行画面
$ python app.py
取得したウェブサイトの文字数: 9123
生成された要約:
📢 ブログ要約通知のハンズオン体験!🌟 Amazon Nova MicroとLINEで、重要なブログポイントを効率的に手に入れよう!AIモデル活用で、新着情報がスマートに通知される仕組みを紹介。AWSの生成AIで読み応えのあるポイントを素早く掴める!✨
ポジティブなフィードバック: 素晴らしいハンズオン!ブログの情報共有がさらにスムーズになりそう!
Evaluating: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:08<00:00, 2.67s/it]
ragasの評価結果:
{'rouge_score': 0.0175, 'faithfulness': 0.8000, 'answer_relevancy': 0.0984}4.2.Ragasスコアの意味
| 指標 | 説明 | メトリクスの意味 |
|---|---|---|
| rouge_score | 生成された要約と参照テキスト(この場合は原文)の間の単語やフレーズの重複度を測る指標。 | 1に近いほど、重複度が高い |
| faithfulness | 回答がソースに忠実か、誤った補完(ハルシネーション)を含んでいないかを評価 | 1に近いほど、ハルシネーションがない |
| answer_relevancy | 回答が元の質問や文脈に対して適切かを評価 | 1に近いほど、回答に対して適切な回答ができている |
4.3.スコアからの洞察
| 指標 | 洞察 |
|---|---|
| rouge_score | 要約が短かく、本文にない表現が多いため、原文との重複が少なくなりスコアが低い。今回の要約には、絵文字や感想表現も含まれているため、オリジナルとの重複がさらに少なくなり低スコアにつながっている。 |
| faithfulness | 元テキストにはない情報(今回だとポジティブフィードバックや感想など)が混ざっているため、完全に事実ベースとはいえないと判断され、スコアが下がる。0.8程度のため、元テキストを大幅に歪めてはいないが、追加要素がスコアに影響したと考えられる。 |
| answer_relevancy | 要約が短い場合、元のウェブサイトの詳細な情報を十分拾っていないとされスコアが低い。感想や絵文字という「要約」という質問とは無関係な要素もあり、スコアを下げる要因となっている。 |
おわりに
得られた知見
- WEBページの文章取得でもRagasを利用することが可能であること
今後の課題
| 課題 | 詳細 |
|---|---|
| 要約生成と感情表現生成の分離 | 要約の中で、ポジティブなワードを使ってほめたりもしているため、スコアのポイントが低い。そのため段階的に「要約」をしてスコアを出して、次に「装飾(ポジティブなワード)」を実行する。 |
| 要約生成の手法 | 一度にすべての「要約」を生成させる前に、「チャンク分割」して生成AIに判断させる量を制御して、次に「部分要約」を行い、最終的に「統合要約」する方法をとることで、全体的な文脈を見失わないように「要約」を生成させる。 |