




はじめに
先日 RAG(Retrieval Augmented Generation)に関するLTで「チャンクごとにベクトルDBに埋め込まれる」という話を聞いたので、Streamlitを使って可視化をしてみました。
RAGとは?
RAG(Retrieval Augmented Generation)とは、大規模言語モデル(LLM)と外部の知識ベースを組み合わせて回答精度を高める技術を指します。
その際テキストデータは意味を持つ小さな単位(チャンク)に分割され、ベクトルデータベースに格納されます。
目的
今回、ベクトルデータベースに格納されたチャンクの分布を可視化することで、データ分布を視覚的に確認し理解を深めることを目指します。
これにより、意味的に近い言葉(例えば動物の名前や略称など)がグラフ上でどのように集まっているかを確認することができます。
方法
ただし本来文章をベクトル化すると、その文章の意味を表すために多次元の数値データとして表現されます。ただし多次元のデータを人間が理解するのは難しいため、PCA(主成分分析)という方法を使って2次元に圧縮して可視化を実施していきます。
手順
1.事前準備
1-1.環境構築
Amazon SageMaker Studio Code Editor での 検証環境構築手順でAmazon SageMaker Studio Code Editorの準備
1-2.IAMロールに「AmazonBedrockFullAccess」アタッチ
デフォルトの SageMaker Domain に Bedrockのフル権限をアタッチ
※本検証ではPoCのためフル権限を付与していますが、本番環境では必要最小限の権限を持つIAMポリシーを作成し、アタッチすることを推奨。

1-3.モデルアクセスの許可
Bedrock 左ペインの「Bedrock configurations」で以下モデルの「アクセス」を許可
| 利用ベースモデル |
|---|
| Titan Text Embeddings V2 |
2.Code Editorでの準備
ターミナルを利用して事前準備実施
2-1.仮想環境作成
python3 -m venv .venv
source .venv/bin/activate 2-2.requirements.txt の作成
boto3
numpy
pandas
plotly
scikit-learn
streamlit2-3.ライブラリの準備
pip install -r requirements.txt3.アプリケーションコード
3-1.アプリケーションコード全量
「初期文言サンプルデータ」の文言を、ベクトルDBに配置をしていきます。
import boto3
import json
import numpy as np
import pandas as pd
import plotly.express as px
from sklearn.decomposition import PCA
import streamlit as st
# Bedrockクライアントの初期化
bedrock_client = boto3.client('bedrock-runtime')
# Bedrock埋め込みモデルのID
model_id = "amazon.titan-embed-text-v2:0"
# 初期文言サンプルデータ
documents = [
"CPIとは協栄情報の略称です",
"AWSはAmazon Web Servicesの略称です",
"RAGはRetrieval-Augmented Generationの略称です",
"うさぎ",
"ねこ",
"きつね",
"人にとって水は大事",
"人にとって価値観は大事",
"人にとって尊厳は大事"
]
# 文言データの埋込を取得
def get_embeddings_from_bedrock(texts):
embeddings = []
for text in texts:
try:
# モデルにテキストを送信し、埋込を取得
request_body = {"inputText": text}
response = bedrock_client.invoke_model(
modelId=model_id,
body=json.dumps(request_body),
contentType="application/json",
)
response_body = json.loads(response["body"].read().decode('utf-8'))
embedding = np.array(response_body["embedding"])
embeddings.append(embedding)
except Exception as e:
# エラーが発生した場合はstreamlitに表示
st.error(f"埋め込み生成中にエラーが発生しました: {e}")
return None
return np.vstack(embeddings) if embeddings else None
# Streamlitセッション状態の初期化
if "documents" not in st.session_state:
st.session_state["documents"] = documents
st.session_state["embeddings"] = get_embeddings_from_bedrock(documents)
# PCAモデルの初期化
if "pca_model" not in st.session_state:
st.session_state["pca_model"] = PCA(n_components=2)
# Streamlit UI
st.title("ベクトル分布可視化")
# 新しい文言の追加ブロック
new_text = st.text_input("新しい文言を追加してください", "")
if st.button("追加"):
if new_text:
new_embedding = get_embeddings_from_bedrock([new_text])
if new_embedding is not None:
st.session_state["documents"].append(new_text)
st.session_state["embeddings"] = np.vstack([st.session_state["embeddings"], new_embedding])
st.success(f"文言 '{new_text}' を追加しました!")
else:
st.error("文言の追加に失敗しました。")
# 不要な文言の削除ブロック
st.write("不要な文言を選択して削除できます。")
selected_for_deletion = st.multiselect(
"削除したい文言を選択してください",
options=st.session_state["documents"]
)
if st.button("選択した文言を削除"):
if selected_for_deletion:
# 削除対象のインデックスを特定
indices_to_delete = [st.session_state["documents"].index(doc) for doc in selected_for_deletion]
# 文言と埋め込みデータを削除
st.session_state["documents"] = [
doc for doc in st.session_state["documents"] if doc not in selected_for_deletion
]
st.session_state["embeddings"] = np.delete(st.session_state["embeddings"], indices_to_delete, axis=0)
st.success("選択した文言を削除しました!")
else:
st.warning("削除する文言が選択されていません。")
# 次元削減 (PCA) または直接プロット
if st.session_state["embeddings"] is not None and len(st.session_state["embeddings"]) > 0:
if len(st.session_state["embeddings"]) > 1:
# データが複数ある場合、PCAを適用
reduced_embeddings = st.session_state["pca_model"].fit_transform(st.session_state["embeddings"])
# DataFrame作成
df = pd.DataFrame(reduced_embeddings, columns=["x", "y"])
df["文言"] = st.session_state["documents"]
# ベクトル分布の可視化
fig = px.scatter(
df, x="x", y="y", text="文言",
title="文言データの意味的な分布",
labels={"x": "文言の特徴軸1", "y": "文言の特徴軸2"}
)
fig.update_traces(textposition='top center')
st.plotly_chart(fig)
# 図の説明
st.write("""この図は、モデルが各文言の意味的な関係をどのように捉えているかを示しています。
「文言の特徴軸1」と「文言の特徴軸2」は、モデルが各文言を特徴づけるための指標です。
近くに配置されている文言は、モデルにとって意味が似ていることを表しています。""")
else:
# データが1つだけの場合
st.warning("PCAはサンプルが2つ以上必要です。現在のデータでは次元削減を実行できません。")
df = pd.DataFrame(st.session_state["embeddings"], columns=["x"])
df["文言"] = st.session_state["documents"]
st.write("単一データの分布:")
st.write(df)
else:
st.warning("埋め込みデータが空です。文言を追加してください。")4.実行
4-1.Streamlit実行
streamlit run app.py --server.port 85014-2.Pinggy(外部サービス)の実行
Pinggyとは?
Pinggyはローカルで動作しているアプリケーションをインターネット上からアクセス可能にするサービスです。
これにより、ローカル環境で開発したStreamlitアプリケーションを、インターネットを通じて他の人と共有したり、外部からアクセスしたりすることが可能になります。
※ Pinggyの公開URLは第三者がアクセス可能となるため、セキュリティに注意してください。また、ハンズオンの動作確認後は、早めに「Ctrl + c」でターミナルからPinggyを動作停止ください。
コマンド内容
ブラウザの新しいタブで開き以下コマンド実施。
途中「Are you sure you want to continue connecting (yes/no/[fingerprint])?
」と聞かれた際「yes」と入力
ssh -p 443 -R0:localhost:8501 a.pinggy.io4-3.URL画面で「Enter site」を押下
「4-2」コマンドで表示されるURL(https:// で始まる方)をコピーして、ブラウザタブで開き「Enter site」をクリック
5.WEB画面
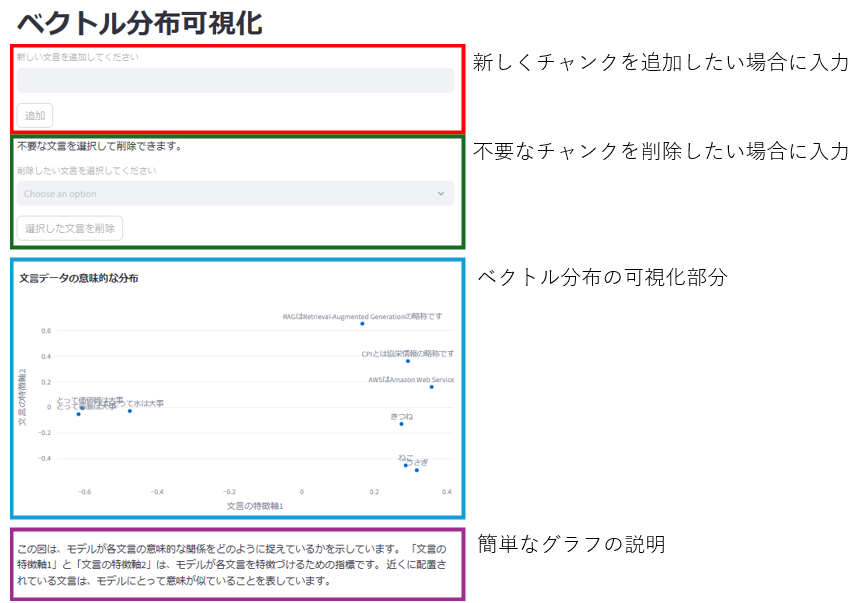
5-1.画面説明
「文言の特徴軸1」と「文言の特徴軸2」は、PCAで次元削減された結果で、文言ベクトルの最も重要な特徴を表しています。
これにより、類似する文言が近くにプロットされます。
5-2.今回の分布例
今回はサンプルのキーワードとして「略称」と「動物」と「大事なもの」の3つを与えました。
それぞれ意味的に関連する文言が近くに配置され、関連性が薄い文言は離れた位置にプロットされていることがグラフよりわかります。
おわりに
得られた知見
PCA(主成分分析)を利用した可視化により、具体的な分布を視覚的に確認することができました。
今後の課題
- 他の次元削減手法(例:t-SNE、UMAP)をとりいれ、さらに深い理解を深める。
- 他の埋め込みモデルでの分布、およびモデル間の相違を可視化。
- より大規模なデータセットでの検証し、最適なチャンク分割方法を検討。