




はじめに
生成AIの利用が進む中、Retrieval Augmented Generation(以下、RAG)の活用が注目されています。
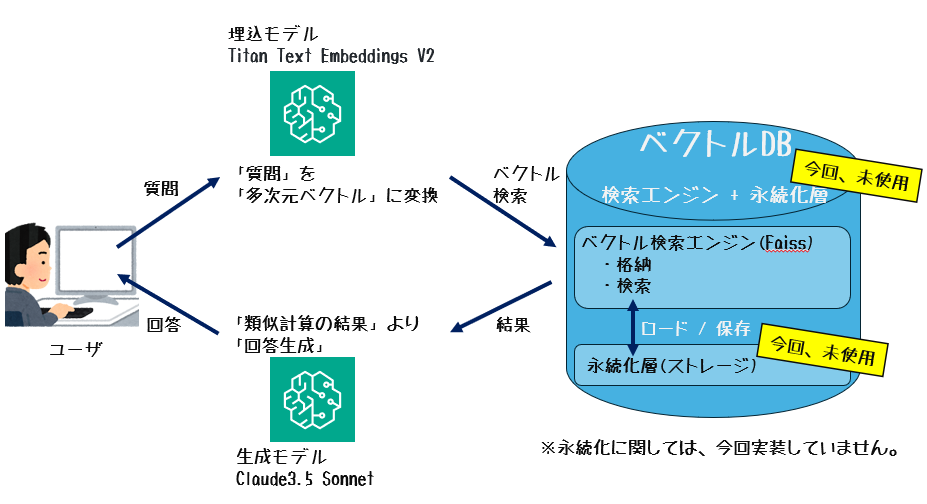
RAGは、事前にベクトルデータベース(ベクトルDB)に専門的な背景情報を格納し、その情報を検索して応答を生成する仕組みです。 これにより専門的な背景情報に基づいた正確で信頼性の高い回答を提供することが可能となります。
本記事の注意点
RAGを構築する際には LangChainのようなフレームワークでの構築が一般的ですが、以下2点の理由よりLangCahinを利用せずに構築をしています。
-
基本的な挙動の理解
LangChainは便利ですが、内部処理が抽象化されており、基礎的な仕組みを把握するのが難しくなります。
そのため、基本を理解するために直接APIを操作して実装。 -
開発サイクルの激しさ
LangChainはOSS(オープンソースソフトウェア)で頻繁に更新され、仕様が変わる可能性があります。
安定した環境で検証するため、本記事では直接の実装を選択。
ハンズオンの構成
本記事では、RAGを以下の3つのフェイズで構築しています。
| No. | フェイズ | 利用技術 | 役割 |
|---|---|---|---|
| 1 | 埋込 | Titan Text Embeddings V2(埋込みモデル) | 背景情報と質問をベクトル(数値表現)に変換 |
| 2 | 格納 | Faiss(ベクトル検索ライブラリ) | 生成されたベクトルを効率的に格納 |
| 3 | 検索 | Faiss(ベクトル検索ライブラリ) | 格納されたベクトルの中から類似度の高い情報を迅速に検索 |
| 4 | 生成 | Claude3.5 Sonnet(生成モデル) | Faissから取得した背景情報を基に回答を生成 |
Faiss(ベクトル検索)とは?
Facebookが開発したオープンソースのベクトル検索ライブラリで、大規模データセットにおける効率的な近似最近傍検索を可能にし、主に以下のような特徴があります。
役割
主に以下の役割を担います。
- 背景情報を格納
- 質問に関連する情報を検索
利点
- インメモリ動作による高速性が強みで、大規模データセットにも対応が可能。
参考URL:Faiss GitHub
質問時の処理フロー
| No. | 処理内容 |
|---|---|
| 1 | ユーザが「質問」を入力 |
| 2 | 埋込モデルが「質問」を「多次元ベクトル」に変換 |
| 3 | Faissが事前に格納された「背景情報ベクトル」と「質問ベクトル」を比較し、類似度が高い情報を検索 |
| 4 | 検索結果(関連性の高い背景情報)を生成モデルに渡す |
| 5 | 生成モデルが背景情報を基に「回答」を生成し、ユーザに返答 |
図:質問時の処理フロー
手順
1.事前準備
1-1.環境構築
Amazon SageMaker Studio Code Editor での 検証環境構築手順でAmazon SageMaker Studio Code Editorの準備
1-2.IAMロールに「AmazonBedrockFullAccess」アタッチ
デフォルトの SageMaker Domain に Bedrockのフル権限をアタッチ
※本検証ではPoCのためフル権限を付与していますが、本番環境では必要最小限の権限を持つIAMポリシーを作成し、アタッチすることを推奨。

1-3.モデルアクセスの許可
1.Bedrock 左ペインの「Bedrock configurations」移動
2.利用モデルごとに「アクセス」を許可
利用リージョン
| No. | リージョン名 | リージョンID |
|---|---|---|
| 1 | 米国東部 (バージニア北部) | us-east-1 |
利用モデル
| No. | 役割 | 利用ベースモデル |
|---|---|---|
| 1 | 埋込(Embedding) | Titan Text Embeddings V2 |
| 2 | LLM(Large Language Model) | Claude 3.5 Sonnet v1 |
2.Code Editorでの準備
ターミナルを利用して事前準備実施
2-1.仮想環境作成
mkdir ${ProjectName}
cd ${ProjectName}
python3 -m venv .venv
source .venv/bin/activate 2-2.requirements.txt の作成
boto3
numpy
streamlit
faiss-cpu2-3.ライブラリの準備
pip install -r requirements.txt3.アプリケーションコード
3-1.アプリケーションコード全量
※LangChainを利用せずにスクリプトを作成
import streamlit as st
import numpy as np
import faiss
import boto3
import json
from typing import List
# LLMと埋め込みモデルを設定
LLM_MODEL = "anthropic.claude-3-5-sonnet-20240620-v1:0" # オンデマンド対応モデル
EMBEDDING_MODEL = "amazon.titan-embed-text-v2:0" # 埋め込みモデル
# 初期データ(RAGの背景情報として格納するデータ)
TEXTS = [
"株式会社 協栄情報は、CPIという略称でも親しまれています。",
"CPI社は、AWSに特化したエンジニアが所属しています。",
"協栄情報のHP:https://www.cp-info.co.jp/",
"協栄情報の技術ブログ:https://cloud5.jp/"
]
# 1. 埋め込み生成
def generate_embeddings(texts: List[str], model_id: str) -> List[List[float]]:
"""
Bedrock埋め込みモデルを利用してテキストの埋め込みを生成する。
"""
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
embeddings = []
for text in texts:
response = bedrock.invoke_model(
modelId=model_id,
body=json.dumps({"inputText": text}),
accept="application/json",
contentType="application/json",
)
# レスポンスを文字列として読み取り、JSONパース
response_body = json.loads(response['body'].read().decode('utf-8'))
embedding_data = response_body.get("embedding")
if not embedding_data:
raise ValueError("埋め込みデータがレスポンスに含まれていません")
embeddings.append(embedding_data)
return embeddings
# 2. ベクトルDB作成
def create_faiss_index(embeddings: List[List[float]]) -> faiss.IndexFlatL2:
"""
FAISSを利用してベクトルデータベースを作成。
"""
dimension = len(embeddings[0])
index = faiss.IndexFlatL2(dimension)
index.add(np.array(embeddings).astype('float32'))
return index
# 3. 最近傍検索
def search_faiss(index, query_vector, k=1):
"""
FAISSで最近傍検索を実行。
"""
distances, indices = index.search(np.array([query_vector]).astype('float32'), k)
return indices
# 4. LLM実行
def generate_answer(context: str, question: str, model_id: str) -> str:
"""
Bedrock LLMを利用して質問に回答を生成(レスポンス処理修正版)。
"""
bedrock = boto3.client('bedrock-runtime', region_name='us-east-1')
# Messages形式のリクエスト
messages = [
{"role": "user", "content": f"背景情報: {context}\n質問: {question}"}
]
# APIリクエストのボディ
request_body = {
"messages": messages,
"max_tokens": 300,
"anthropic_version": "bedrock-2023-05-31"
}
# APIリクエスト送信
response = bedrock.invoke_model(
modelId=model_id,
body=json.dumps(request_body),
accept="application/json",
contentType="application/json",
)
# レスポンスを処理
response_body = json.loads(response['body'].read().decode('utf-8'))
# 応答を取得
content = response_body.get("content", [])
if content and len(content) > 0 and content[0].get("type") == "text":
return content[0].get("text", "回答が取得できませんでした")
else:
return "回答が取得できませんでした"
# Streamlit UI
def main():
st.title("RAG Hands On")
# 質問入力
question = st.text_input("質問を入力してください:")
if st.button("質問する") and question:
try:
# 1. 埋め込み生成(背景情報の格納)
embeddings = generate_embeddings(TEXTS, EMBEDDING_MODEL)
# 2. ベクトルDB作成
index = create_faiss_index(embeddings)
# 3. 質問に対する埋め込み生成
question_embedding = generate_embeddings([question], EMBEDDING_MODEL)[0]
# 4. ベクトル検索
retrieved_indices = search_faiss(index, question_embedding, k=1)
context = TEXTS[retrieved_indices[0][0]]
# 5. 回答生成
answer = generate_answer(context, question, LLM_MODEL)
# 回答を表示
st.success("回答: " + answer)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
if __name__ == "__main__":
main()
4.実行
4-1.Streamlit実行
streamlit run app.py --server.port 85014-2.Pinggy(外部サービス)の実行
Pinggyとは?
Pinggyはローカルで動作しているアプリケーションをインターネット上からアクセス可能にするサービスです。
これにより、ローカル環境で開発したStreamlitアプリケーションを、インターネットを通じて他の人と共有したり、外部からアクセスしたりすることが可能になります。
※ Pinggyの公開URLは第三者がアクセス可能となるため、セキュリティに注意してください。また、ハンズオンの動作確認後は、早めに「Ctrl + c」でターミナルからPinggyを動作停止ください。
コマンド内容
ブラウザの新しいタブで開き以下コマンド実施。
途中「Are you sure you want to continue connecting (yes/no/[fingerprint])?
」と聞かれた際「yes」と入力
ssh -p 443 -R0:localhost:8501 a.pinggy.io4-3.URL画面で「Enter site」を押下
「4-2」コマンドで表示されるURL(https:// で始まる方)をコピーして、ブラウザタブで開き「Enter site」をクリック
5.結果
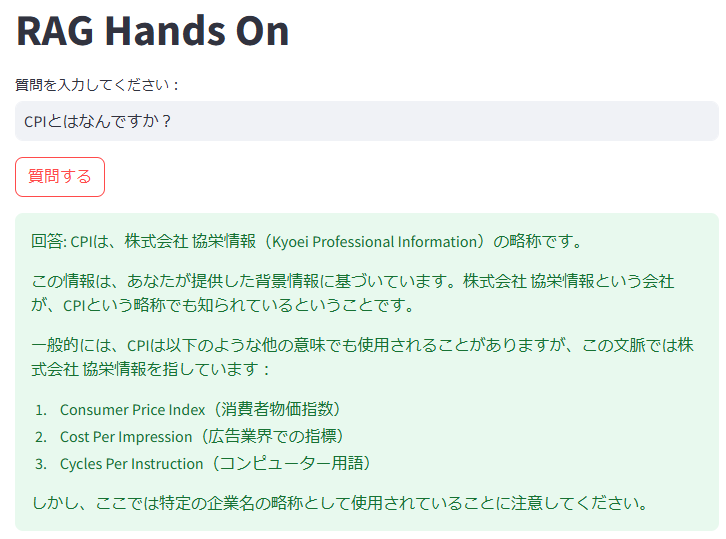
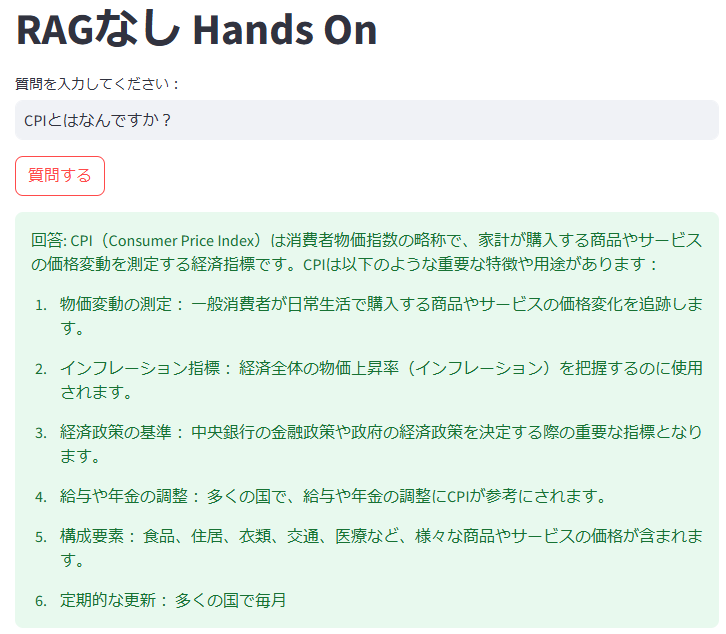
RAGがある場合は、背景情報に基づき専門的な回答(例: 株式会社 協栄情報)を提供できました。
一方、RAGがない場合は一般的な知識に基づく回答(例: 消費者物価指数)となりました。
5-1.RAGあり 質問・回答画面
RAGがある場合だと、CPIは株式会社 協栄情報の略称とも教えてくれました。
図:RAGありの場合の回答例
5-2.RAGなし 質問・回答画面
RAGがない場合だと、CPIは消費者物価指数の略称だと教えてくれました。
図:RAGなしの場合の回答例
おわりに
得られた知見
-
Faissの有用性:Faissを使用することで、RAG構成が可能となることを確認できました。
-
RAGのフロー:「埋込み」と「生成」・Faissの「検索」を交えて、それぞれの処理について確認することができました。
今後の課題
- 性能評価の実施:生成結果の精度を測定するための評価指標(例:RAGASなど)の適用。
- 他ライブラリとの比較:PineconeやWeaviateなど他のベクトル検索ライブラリとの性能比較。