




はじめに
会社の人数が増えるに従い、ブログ投稿数も増加して見落としが多くなってきました。
そのため毎朝自分のスマートフォンのLINEに、AIモデルを活用して、ブログの重要なポイントを効率よく通知する仕組みをつくってしまおうと思いまして、本ハンズオン記事を作成しました。
本記事の注意点
本記事ではwebスクレイピング(Python)で情報を取得していますが、サイトによってはスクレイピングの使用を禁止されている場合もありますので利用の際は各規約を確認ください。
構成
構成役割
| リソース名 | 役割 |
|---|---|
| Lambda | ブログ記事のスクレイピング、DynamoDBとのデータ比較、新しい記事の通知処理を実行 |
| DynamoDB | 「前回取得リスト」を保存し、新しいブログ記事を検出するためのデータベースとして使用 |
| Bedrock(モデル:Amazon Nova Micro) | ブログ記事内容を基に、要約コメントを生成 |
Amazon Nova Micro について
2024年「AWS re:Invent 2024」にて発表された、Amazon製の新しいモデルの1つ。
同時に発表された6つの種類の中で最もレイテンシーが低く、低コストかつ高速なレスポンスが特徴もモデルです。
構成イメージ図
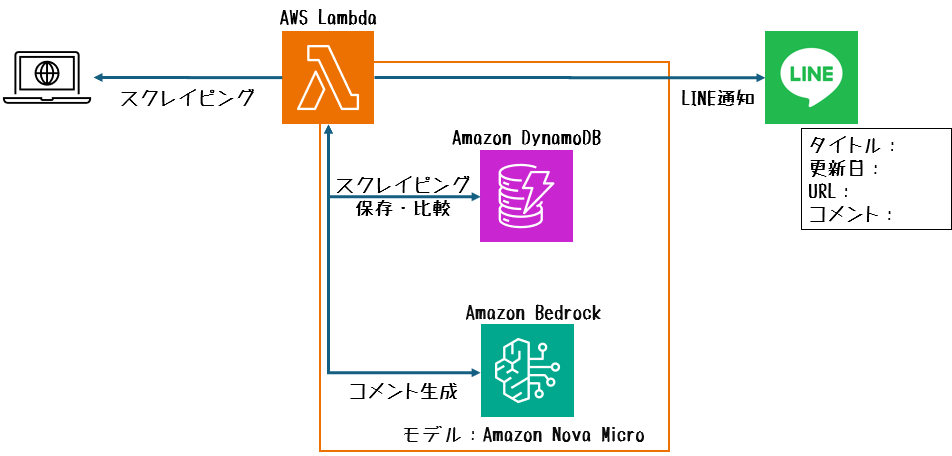
手順
1.LINE 準備
1-1.LINE Developersログイン
1-2.Messaging APIを始めように従い、[2-3.チャンネルを確認する]まで実施。
1-3.チャネルアクセストークンに従い、[長期のチャネルアクセストークン]を実施し、アクセストークを作成
2.DynamoDB準備
2-1.テーブル作成
| 項目 | 値 |
|---|---|
| テーブル名 | BlogTitleLog |
| パーティションキー | id(N) |
AWS環境 CloudShell にて以下コマンド実施
aws dynamodb create-table \
--table-name BlogTitleLog \
--attribute-definitions AttributeName=id,AttributeType=N \
--key-schema AttributeName=id,KeyType=HASH \
--billing-mode PAY_PER_REQUEST3.Bedrock準備
3-1.利用モデルアクセスの付与
1.Bedrock 左ペインの「Bedrock configurations」移動
2.利用モデルの「アクセス」を許可
| 項目 | 値 |
|---|---|
| リージョン | us-east-1 |
| モデル名 | Amazon Nova Micro |
4.Lambda準備
4-1.利用ライブラリ
Lambdaレイヤーで導入
※Lambdaレイヤーの設定は、本編からそれるため今回割愛。
| 項目 | 値 |
|---|---|
| requests | HTTPリクエストを送信(Webスクレイピングで使用) |
| beautifulsoup4 | WebページのHTMLを解析 |
参考URL:関数へのレイヤーの追加
4-2.Lambda構築
サービス「Lambda」より「関数の作成」から構築
| 項目 | 値 |
|---|---|
| 関数名 | ${ユーザごとに命名} |
| ランタイム | python 3.12 |
4-3.Lambda構築後の設定変更
4-3-1.一般設定
生成AIの回答を待機する必要があるため、時間を変更する。
| 項目 | 値 |
|---|---|
| タイムアウト | 1分 |
4-3-2.アクセス権限
Bedrock及び、DynamoDBを利用するため、権限を追加する。
| 項目 | 値 |
|---|---|
| 実行ロール追加 | AmazonBedrockFullAccess |
| 実行ロール追加 | AmazonDynamoDBFullAccess |
※本検証ではPoCのためフル権限を付与していますが、本番環境では必要最小限の権限を持つIAMポリシーを作成し、アタッチすることを推奨。
4-3-3.環境変数
| キー | 値 |
|---|---|
| DYNAMODB_TABLE | BlogTitleLog |
| MY_AWS_REGION | us-east-1 |
| LINE_CHANNEL_ACCESS_TOKEN | ${LINEアクセストークン} |
| LINE_USER_ID | ${LINEユーザID} |
4-3-4.Lambdaコード
import boto3
import json
import requests
from bs4 import BeautifulSoup
import os
# DynamoDBクライアント
dynamodb = boto3.client('dynamodb')
# Amazon Bedrockクライアント
bedrock = boto3.client('bedrock-runtime', region_name=os.getenv('MY_AWS_REGION'))
# LINE通知関数
def send_line_message(title, url, updated_date, comment):
"""
LINE Notify APIを使用して通知を送信します。
"""
LINE_CHANNEL_ACCESS_TOKEN = os.getenv('LINE_CHANNEL_ACCESS_TOKEN')
REQUEST_HEADERS = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + LINE_CHANNEL_ACCESS_TOKEN
}
REQUEST_URL = 'https://api.line.me/v2/bot/message/push'
message = {
'type': 'text',
'text': (
f"【タイトル】\n{title}\n"
f"【更新日】\n{updated_date}\n"
f"【URL】\n{url}\n"
f"【コメント】\n{comment}"
)
}
params = {
'to': os.getenv('LINE_USER_ID'),
'messages': [message]
}
response = requests.post(REQUEST_URL, headers=REQUEST_HEADERS, json=params)
if response.status_code == 200:
print(f"Message sent successfully for {title}")
else:
print(f"Failed to send message for {title}: {response.status_code}")
# ブログ本文取得関数
def fetch_blog_content(url):
"""
ブログの本文を取得します。
"""
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# 例: <article>タグ内のテキストを取得
content_section = soup.find("article")
if content_section:
return content_section.get_text(strip=True)
else:
return "本文を取得できませんでした。"
# コメント生成関数
def generate_comment_with_bedrock(content):
"""
Amazon Bedrockを使用してブログのコメントを生成します。
"""
prompt_text = (
"あなたはブログのコメンテーターです。\n"
"ブログの内容を要約し、読者が読みたくなるようにポイントを簡潔に説明し、"
"ポジティブなフィードバックを50文字以内で記載してください。\n"
"文章は全体的に親しみやすいトーンを心がけ、絵文字を活用して柔らかい雰囲気にしてください。\n\n"
f"ブログ内容:\n{content}"
)
try:
body = {
"system": [
{
"text": "以下のブログ内容に基づいて魅力的なコメントを生成してください。"
}
],
"messages": [
{
"role": "user",
"content": [
{
"text": prompt_text
}
]
}
],
"inferenceConfig": {
"temperature": 0.7,
"top_p": 0.9,
"max_new_tokens": 200,
"stopSequences": []
}
}
response = bedrock.invoke_model(
modelId="amazon.nova-micro-v1:0",
body=json.dumps(body),
contentType="application/json"
)
# レスポンス解析
result = json.loads(response['body'].read())
messages = result.get('output', {}).get('message', {}).get('content', [])
if messages:
comment = messages[0].get('text', '').strip()
# コメントが途中で切れている場合
if result.get("stopReason") == "max_tokens":
comment += "(続きが切れています。完全な内容はブログを直接ご覧ください。)"
# トークン使用量をログ出力
usage_info = result.get('usage', {})
print(f"トークン使用量: {usage_info}")
return comment
else:
return "コメントを生成できませんでした。"
except Exception as e:
print(f"Bedrockによるコメント生成中にエラーが発生しました: {e}")
return "ブログの内容をぜひチェックしてください!読み応えがありますよ!📚✨"
# DynamoDBから保存済みタイトル一覧を取得
def get_saved_titles():
table_name = os.getenv('DYNAMODB_TABLE')
try:
response = dynamodb.get_item(
TableName=table_name,
Key={"id": {"N": "1"}}
)
if 'Item' in response and 'titles' in response['Item']:
return [item['S'] for item in response['Item']['titles']['L']]
return []
except Exception as e:
print(f"DynamoDBエラー: {e}")
return []
# DynamoDBにタイトル一覧を保存
def save_titles(titles):
table_name = os.getenv('DYNAMODB_TABLE')
try:
dynamodb.put_item(
TableName=table_name,
Item={
"id": {"N": "1"},
"titles": {"L": [{"S": title} for title in titles]}
}
)
print("タイトル一覧を保存しました。")
except Exception as e:
print(f"DynamoDBエラー: {e}")
# ブログタイトル、URL、更新日を取得
def extract_blog_titles_and_metadata():
url = 'https://cloud5.jp/'
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
cards = soup.find_all("h5", class_="card-title")
titles_metadata = []
for card in cards:
link = card.find("a")
if link and 'href' in link.attrs:
title = link.text.strip()
article_url = link['href']
# 更新日を取得
article_response = requests.get(article_url)
article_soup = BeautifulSoup(article_response.content, "html.parser")
modified_section = article_soup.find("section", class_="modified-date")
if modified_section:
updated_date = modified_section.text.strip().replace("Last modified: ", "").strip()
else:
updated_date = "更新日が見つかりません"
titles_metadata.append({
"title": title,
"url": article_url,
"updated_date": updated_date
})
return titles_metadata
# メイン処理
def lambda_handler(event, context):
latest_titles_and_metadata = extract_blog_titles_and_metadata()
latest_titles = [item['title'] for item in latest_titles_and_metadata]
saved_titles = get_saved_titles()
new_articles = [
item for item in latest_titles_and_metadata if item['title'] not in saved_titles
]
if new_articles:
for article in new_articles:
title = article['title']
url = article['url']
updated_date = article['updated_date']
content = fetch_blog_content(url)
comment = generate_comment_with_bedrock(content)
send_line_message(title, url, updated_date, comment)
save_titles(latest_titles)
else:
print("新しい記事はありません。")
挙動
通知フォーマット
コードより抜粋
'text': (
f"【タイトル】\n{title}\n"
f"【更新日\n{updated_date}\n"
f"【URL】\n{url}\n"
f"【コメント】\n{comment}"
)実際の通知画面

おわりに
感想
- Amazon Novaを日常的な通知サービスに応用することで、日々の生活の中で活用することができるようになりました。LINE通知の連携については改めて、使い勝手の良さを感じました。
- 部門内でリリースすることで、さらにブログの情報共有が捗りそうだと家事ました。
得られた知見
- 単なる更新記事だけでなく、生成AIで要約した通知システムの構築方法を学べました。
今後の課題
- 日本語生成精度の比較のため、Claudeや他のモデルとも比較検討(例: 生成精度、応答速度、コストなど)していく。
- 内容をさらにリッチにし、社内情報共有のチャットでも利用できるようにしていく。