



はじめに
仕事の都合で GoogleCloudを触り始めた、GoogleCloud歴 5か月の駆け出しエンジニアです。
今回のPJで利用している一部のリソースを、改めて自分の環境で構築の検証をしてみました。
ハンズオン
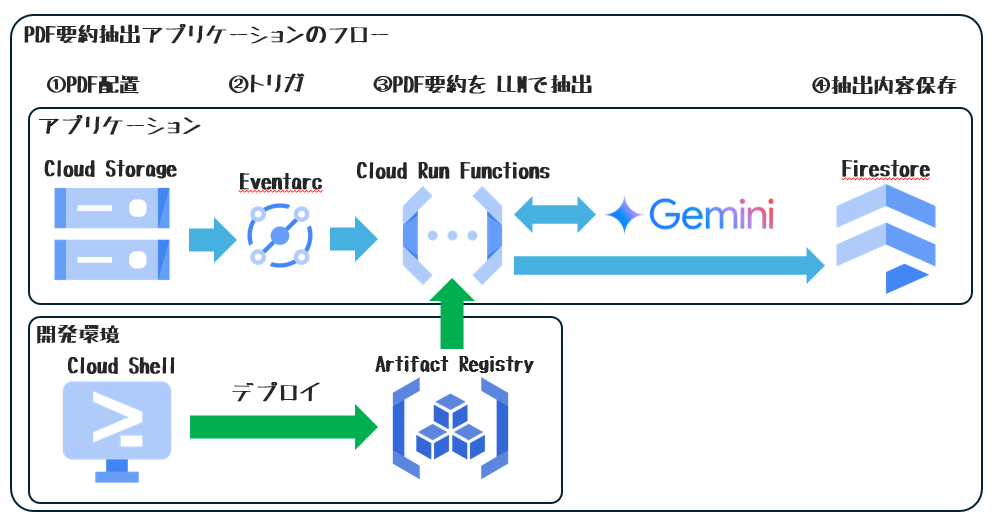
構成図
前提条件
-
PoCのため「リソースで利用するサービスアカウントは全て同じもの」を利用します。
本番環境では最小権限の原則に従い構築ください。 -
本検証はすべて、Cloudshellから実行しています。
1.GCPプロジェクトの作成
新規にGCPプロジェクトを作成します。
export YOUR_PROJECT_ID="pdf-analyzer-$(date +%Y%m%d)"
gcloud projects create ${YOUR_PROJECT_ID} --name=${YOUR_PROJECT_ID}
# プロジェクトを設定
gcloud config set project ${YOUR_PROJECT_ID}2.利用APIの有効化
本プロジェクトで利用するAPIを有効化します。
gcloud services enable cloudfunctions.googleapis.com \
storage.googleapis.com \
firestore.googleapis.com \
aiplatform.googleapis.com \
cloudbuild.googleapis.com \
documentai.googleapis.com \
run.googleapis.com \
eventarc.googleapis.com \
generativelanguage.googleapis.com3.ServiceAccout(SA)の作成
前提条件でも記載したように、全てのリソースで同じSAを利用します。
# SAの作成
SA_NAME="YOUR-SA-NAME"
SA_EMAIL="${SA_NAME}@${YOUR_PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="PDF Analyzer Service Account"
# Cloud Functions開発者権限を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/cloudfunctions.developer"
# Firestore権限を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/datastore.user"
# Vertex AI権限を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/aiplatform.user"
# Eventarcサービスエージェントに権限を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/eventarc.serviceAgent"
# Eventarc イベント受信者の役割を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:${SA_EMAIL}" \
--role="roles/eventarc.eventReceiver"
4.GCS バケットを作成
PDFを配置するバケットを作成します。
以下2種類の権限関係のコマンドを実行します。
| 項番 | コマンド | 対象 | 本PJでの詳細 |
|---|---|---|---|
| 1 | gsutil iam ch | 特定のバケット | 作成したSAに権限を付与 |
| 2 | gcloud projects add-iam-policy-binding | プロジェクト全体 | マネージドのSAに権限を付与 |
# バケット名を設定
BUCKET_NAME="YOUR-BICKET_NAME"
# バケットを作成
gsutil mb -l us-central1 gs://${BUCKET_NAME}
# バケット一覧の確認
gsutil ls
# GCS バケットへ権限を付与
gsutil iam ch serviceAccount:${SA_EMAIL}:roles/storage.admin gs://${BUCKET_NAME}
# GCS自体のサービスアカウントに権限を付与のため、プロジェクト番号を取得
PROJECT_NUMBER=$(gcloud projects describe ${YOUR_PROJECT_ID} --format="value(projectNumber)")
# GCS自体のサービスアカウントに権限を付与
gcloud projects add-iam-policy-binding ${YOUR_PROJECT_ID} \
--member="serviceAccount:service-${PROJECT_NUMBER}@gs-project-accounts.iam.gserviceaccount.com" \
--role="roles/pubsub.publisher"5.Firastoreの作成
PDFの要約を保存するDBとして作成します。
# Firestoreデータベースを作成(ネイティブモード)
gcloud firestore databases create --location=us-central1
6.Cloud Run Functionの作成
GCSにPDFが配置されたことをトリガにして実行される関数を作成します。
6.1.アプリケーション構成
pdf-analyzer-function
└main.py
└requirements.txt
6.2.main.py
以下ファイルを作成します。
- 環境変数について
Cloud Shellにて環境変数が設定してある場合は、そちらに従う。環境変数がない場合は、スクリプト内に書かれたデフォルト値に従う設定とする。
import os
import json
import tempfile
import functions_framework
import PyPDF2
from google.cloud import storage
from google.cloud import firestore
from google import genai
from google.genai import types
from datetime import datetime
# 環境変数(設定がない場合はデフォルト値を設定)
PROJECT_ID = os.environ.get('YOUR_PROJECT_ID', 'XXXXX')
LOCATION = os.environ.get('GOOGLE_CLOUD_LOCATION', 'us-central1')
GEMINI_MODEL = os.environ.get('GEMINI_MODEL', 'gemini-2.0-flash-001')
MAX_TEXT_LENGTH = int(os.environ.get('MAX_TEXT_LENGTH', '10000'))
# GCS 初期化
storage_client = storage.Client()
# Firestore 初期化
db = firestore.Client()
@functions_framework.cloud_event
def process_pdf(cloud_event):
"""Cloud Functionのエントリーポイント: PDFをGCSから取得して処理"""
# イベントデータの解析
data = cloud_event.data
bucket_name = data["bucket"]
file_name = data["name"]
content_type = data.get("contentType", "")
# PDFファイルのみを処理
if not content_type or content_type != "application/pdf":
print(f"{file_name}はPDFではないのでスキップします")
return
print(f"PDFファイル処理開始: {file_name} (バケット: {bucket_name})")
# 一時ファイルにPDFをダウンロード
bucket = storage_client.bucket(bucket_name)
blob = bucket.blob(file_name)
# PDFのメタデータを取得
metadata = blob.metadata or {}
with tempfile.NamedTemporaryFile(delete=False) as temp:
blob.download_to_filename(temp.name)
temp_path = temp.name
try:
# PDFからテキストを抽出
text_content = extract_text_from_pdf(temp_path)
# PDFのページ数を取得
num_pages = get_pdf_page_count(temp_path)
# テキストがない場合は中断
if not text_content.strip():
print("テキストが抽出できませんでした")
result = {
"status": "error",
"message": "テキストを抽出できませんでした"
}
save_to_firestore(file_name, bucket_name, result)
return
# Geminiで解析
analysis_result = analyze_with_genai(text_content)
# 結果をFirestoreに保存
result = {
"filename": file_name,
"bucket": bucket_name,
"uploadTime": datetime.now().isoformat(),
"pageCount": num_pages,
"extractedText": text_content[:1000] + "..." if len(text_content) > 1000 else text_content,
"fullTextLength": len(text_content),
"analysis": analysis_result,
"metadata": metadata
}
doc_id = save_to_firestore(file_name, bucket_name, result)
print(f"処理完了: ドキュメントID {doc_id}")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
result = {
"status": "error",
"message": str(e)
}
save_to_firestore(file_name, bucket_name, result)
finally:
# 一時ファイルの削除
if os.path.exists(temp_path):
os.unlink(temp_path)
def extract_text_from_pdf(pdf_path):
"""PDFからテキストを抽出"""
text = ""
try:
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
for page_num in range(len(reader.pages)):
page = reader.pages[page_num]
text += page.extract_text() + "\n"
except Exception as e:
print(f"PDFテキスト抽出エラー: {str(e)}")
return text
def get_pdf_page_count(pdf_path):
"""PDFのページ数を取得"""
try:
with open(pdf_path, 'rb') as file:
reader = PyPDF2.PdfReader(file)
return len(reader.pages)
except Exception as e:
print(f"PDFページ数取得エラー: {str(e)}")
return 0
def analyze_with_genai(text):
"""Geminiを使ってテキストを解析"""
try:
# テキストが長すぎる場合は切り詰める
if len(text) > MAX_TEXT_LENGTH:
text = text[:MAX_TEXT_LENGTH] + "..."
# Vertex AIでGeminiモデルを利用するためのクライアント作成
client = genai.Client(
vertexai=True,
project=PROJECT_ID,
location=LOCATION,
)
# プロンプトを作成
prompt = f"""
以下のPDF文書の内容を解析してください。
1. 文書の概要を100字以内で要約してください
2. 文書のカテゴリを判定してください(例:技術文書、法律文書、学術論文、マニュアルなど)
3. 文書から5つの重要なキーワードを抽出してください
4. 文書の主要な論点や結論を箇条書きで3つ挙げてください
# PDF文書の内容:
{text}
# 解析結果:
"""
# コンテンツ設定
contents = [
types.Content(
role="user",
parts=[types.Part.from_text(text=prompt)]
)
]
# 生成設定
generate_content_config = types.GenerateContentConfig(
temperature=0.2,
top_p=0.8,
max_output_tokens=1024,
response_modalities=["TEXT"],
safety_settings=[
types.SafetySetting(
category="HARM_CATEGORY_HATE_SPEECH",
threshold="OFF"
),
types.SafetySetting(
category="HARM_CATEGORY_DANGEROUS_CONTENT",
threshold="OFF"
),
types.SafetySetting(
category="HARM_CATEGORY_SEXUALLY_EXPLICIT",
threshold="OFF"
),
types.SafetySetting(
category="HARM_CATEGORY_HARASSMENT",
threshold="OFF"
)
]
)
# モデルを呼び出し
response = client.models.generate_content(
model=GEMINI_MODEL,
contents=contents,
config=generate_content_config,
)
# 解析結果をテキストで返す
return {
"generatedAnalysis": response.text,
"model": GEMINI_MODEL
}
except Exception as e:
print(f"Gemini解析エラー: {str(e)}")
return {
"error": str(e)
}
def save_to_firestore(file_name, bucket_name, result):
"""結果をFirestoreに保存"""
# ドキュメントIDを作成(ファイル名からスラッシュや特殊文字を取り除く)
doc_id = file_name.replace('/', '_').replace(' ', '_')
# Firestoreにドキュメントを保存
doc_ref = db.collection('pdf_documents').document(doc_id)
doc_ref.set(result)
return doc_id6.3.requirements.txt
以下ファイルを作成します。
google-cloud-storage
google-cloud-firestore
google-genai
PyPDF2
functions-framework
pycryptodome6.4.デプロイ
上記ファイルを作成後、関数名を入力して作成します。
# Cloud Functionをデプロイ
YOUR_FUNCTION_NAME="YOUR_FUNCTION_NAME"
gcloud functions deploy ${YOUR_FUNCTION_NAME} \
--gen2 \
--runtime=python311 \
--region=us-central1 \
--source=. \
--entry-point=process_pdf \
--trigger-event-filters="type=google.cloud.storage.object.v1.finalized" \
--trigger-event-filters="bucket=${BUCKET_NAME}" \
--service-account=${SA_EMAIL} \
--memory=1024MB \
--timeout=540s7.アップロード実行
上記デプロイ後Cloudshlellに適当なPDFを配置し、以下コマンドよりPDFをアップロードする。
今回は IPAのセキュリティ対策の基本と共通対策を利用。
gsutil cp [ローカルのPDFファイルパス] gs://${BUCKET_NAME}/8.実行確認テスト
8.1.Cloud Functionのログを確認
以下コマンドよりログを確認する。
gcloud functions logs read ${YOUR_FUNCTION_NAME} --gen2 --region=us-central1- レスポンス画面
処理が完了していることが確認できます。
LEVEL:
NAME: ${YOUR_FUNCTION_NAME}
EXECUTION_ID: qXnOGGVpZzoL
TIME_UTC: 2025-04-05 06:56:40.330
LOG: 処理完了: ドキュメントID IPA_kihontokyoutsuu_2024.pdf
LEVEL:
NAME: ${YOUR_FUNCTION_NAME}
EXECUTION_ID: qXnOGGVpZzoL
TIME_UTC: 2025-04-05 06:56:35.214
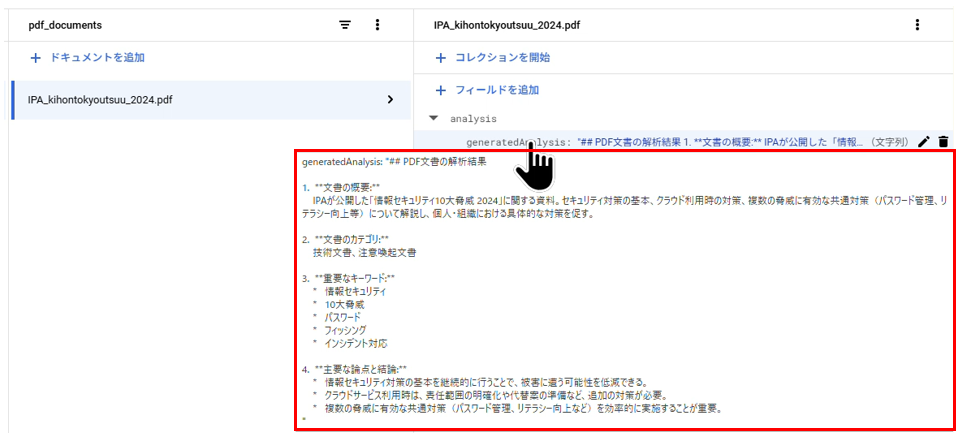
LOG: PDFファイル処理開始: IPA_kihontokyoutsuu_2024.pdf (バケット: pdf-analyzer-storage)8.2.Firestore の画面を確認
- Firestoreに要約内容が記載されていることを確認する

おわりに
得られた知見
- Cloud Functions + Firestore + GCS + Gemini API によるPDF解析フローを構築できたこと。
今後の課題
- 複数のPDFが同時にアップロードされた場合、Cloud FunctionがGemini APIを直接呼び出す構成ではAPI制限やリソース競合が発生する可能性がある
- → Cloud TasksやPub/Subを活用した非同期処理構成にリファクタリングを検討