




こんにちは、石川です。
今回はWorkSpacesの削除についての記事を執筆いたします。
はじめに
AWS WorkSpacesの運用を担当していると、環境整理やリプレース時に「WorkSpacesを大量に効率よく削除したい」というニーズがあるかと思います。
本記事では、CloudShellとAWS CLIを活用し、ws-idさえあれば一瞬でWorkSpacesを削除できる仕組みをご紹介します。
第1章:手動削除の限界
AWS WorkSpacesを大量に運用していると、削除作業の煩雑さに直面します。
コンソールから1台ずつ削除していては、時間も手間もかかり、ヒューマンエラーのリスクも避けられません。
特に、検証環境やリプレース対応などで一度に数十〜数百台を削除する場面では、自動化の重要性を痛感します。
そのような状況を解決するために、今回は効率化を目的とした削除スクリプトを準備しました。
第2章:CloudShellで一括削除する仕組み
今回紹介するスクリプトのポイントは、「リージョンごとに安全に処理を行う設計」です。
WorkSpacesはリージョン単位で管理されているため、削除コマンドを一括実行する際には、誤って他リージョンの環境に影響を与えないよう制御する必要があります。
(※他リージョンをまたいだ削除も可能ですが、本記事ではシンプルな構成を優先し、リージョン単位のスクリプトとしています。)
スクリプトの構成は以下の通りです:
REGION 変数を指定し、リージョン単位で削除を実行
ws_ids.txt に削除対象の WorkSpaces ID(例:ws-xxxxxxxx)を記載
CloudShell上でスクリプトを実行するだけで一括削除が完了
CloudShellはAWS CLIが標準で利用できるため、ローカル環境の構築は不要です。
IAM権限さえあれば、どの環境でもすぐに実行できます。
削除対象のIDさえ揃っていれば、100台規模でも数分で処理が完了します!
ただし、いきなり削除するのではなく、次のような配慮も入れたのでやや長めのスクリプトになりました。
- IDファイルからWorkSpaces IDを読み込む
- 不正なIDや存在しないIDを除外する
- 一定件数ずつ分割して削除リクエストを送る
- APIの一時エラーやスロットリング時はリトライする
- すぐ削除できない状態なら、削除可能になるまで待つ
- 最後にTERMINATEDになるまで監視する
- 存在しなかったIDを最後に一覧表示する
第3章:スクリプト例(ログ出力付きで安全に実行)
では早速手順を紹介します。
手順1. 対象WorkSpacesIDを記載
CloudShellを開き以下ファイルを作成し、該当のWorkSpacesIDを記述する。
nano ws_ids.txt
手順2. 削除スクリプトの作成
以下のコマンドを実行します。
nano terminate_by_ids.sh
#!/usr/bin/env bash
set -euo pipefail
REGION="${REGION:-ap-northeast-1}"
PROFILE="${PROFILE:-}"
IDS_FILE="${IDS_FILE:-ws_ids.txt}"
BATCH_SIZE="${BATCH_SIZE:-25}"
MAX_RETRY="${MAX_RETRY:-8}"
RETRY_SLEEP_BASE="${RETRY_SLEEP_BASE:-3}"
WATCH_INTERVAL="${WATCH_INTERVAL:-30}"
aws_opts=(--region "$REGION"); [[ -n "$PROFILE" ]] && aws_opts+=(--profile "$PROFILE")
[[ -s "$IDS_FILE" ]] || { echo "IDリストが空/不存在: $IDS_FILE"; exit 1; }
# IDを整形して読み込み(CR削除、ws-行のみ、前後空白除去、重複排除)
mapfile -t ALL_IDS < <(tr -d '\r' < "$IDS_FILE" | grep -E '^\s*ws-[a-z0-9]+' | sed 's/^\s*//;s/\s*$//' | sort -u)
((${#ALL_IDS[@]})) || { echo "有効なIDがありません"; exit 1; }
echo "対象 ${#ALL_IDS[@]} 台 / REGION=$REGION PROFILE=${PROFILE:-<none>}"
printf ' %s\n' "${ALL_IDS[@]:0:5}"; ((${#ALL_IDS[@]} > 5)) && echo " ...(省略)"
# ===== ここを強化:存在チェック(配列長で判定)=====
declare -a VALID_IDS=()
declare -a INVALID_IDS=()
for id in "${ALL_IDS[@]}"; do
count=$(aws "${aws_opts[@]}" workspaces describe-workspaces \
--workspace-ids "$id" \
--query 'length(Workspaces)' --output text 2>/dev/null || echo 0)
if [[ "$count" -ge 1 ]]; then
VALID_IDS+=("$id")
else
INVALID_IDS+=("$id")
fi
done
if ((${#VALID_IDS[@]}==0)); then
echo "有効な WorkSpaces ID が見つかりません。終了します。"
# 存在しなかったIDがあれば一覧化しておく
if ((${#INVALID_IDS[@]})); then
echo; echo "⚠️ 存在しなかった WorkSpaces ID:"
printf ' - %s\n' "${INVALID_IDS[@]}"
fi
exit 0
fi
terminate_with_retry() {
local ids=("$@") attempt=1 sleep_s=$RETRY_SLEEP_BASE
while :; do
local req='['; for id in "${ids[@]}"; do req+='{"WorkspaceId":"'"$id"'"},'; done; req="${req%,}]"
set +e
local out rc
out=$(aws "${aws_opts[@]}" workspaces terminate-workspaces \
--terminate-workspace-requests "$req" --output json 2>&1)
rc=$?
set -e
if (( rc == 0 )); then
mapfile -t failed_ids < <(printf '%s' "$out" | awk '/FailedRequests/{f=1} f' \
| grep -o '"WorkspaceId":"ws-[^"]*"' | cut -d: -f2 | tr -d '"')
((${#failed_ids[@]}==0)) && { echo "OK (${#ids[@]} 件)"; return 0; }
declare -a retry_ids=()
for fid in "${failed_ids[@]}"; do
ec=$(printf '%s' "$out" | awk -v id="$fid" '$0 ~ /FailedRequests/ {f=1} f && $0 ~ id {p=1} p && /ErrorCode/ {gsub(/[",]/,""); print $2; exit}')
[[ "$ec" == "InvalidWorkspaceState" ]] && retry_ids+=("$fid") || echo "FAILED $fid : $ec"
done
((${#retry_ids[@]}==0)) && return 0
echo "待機: 削除可能状態になるまで (${#retry_ids[@]} 件)"
while :; do
still=()
local j=0
while (( j < ${#retry_ids[@]} )); do
part=( "${retry_ids[@]:j:25}" )
desc=$(aws "${aws_opts[@]}" workspaces describe-workspaces \
--workspace-ids "${part[@]}" \
--query 'Workspaces[].{Id:WorkspaceId,St:State}' --output text 2>/dev/null || true)
while read -r wid st; do
[[ -z "$wid" ]] && continue
case "$st" in
AVAILABLE|STOPPED|ERROR|UNHEALTHY|TERMINATED) : ;;
*) still+=("$wid") ;;
esac
done <<< "$desc"
j=$(( j + ${#part[@]} ))
done
((${#still[@]}==0)) && break
sleep 10
retry_ids=( "${still[@]}" )
done
ids=( "${retry_ids[@]}" ); continue
fi
if grep -qiE 'Throttl|TooMany|Rate|Timeout|ServiceUnavailable|RequestLimit' <<<"$out" \
&& (( attempt < MAX_RETRY )); then
echo "Retry ${attempt}/${MAX_RETRY} … ${sleep_s}s"; sleep "$sleep_s"
attempt=$((attempt+1)); sleep_s=$((sleep_s*2)); continue
fi
echo "ERROR: $out"; return 1
done
}
# ===== 削除実行(有効IDのみ)=====
i=0
while (( i < ${#VALID_IDS[@]} )); do
chunk=( "${VALID_IDS[@]:i:BATCH_SIZE}" )
echo "送信: ${#chunk[@]} 台 ($((i+1))..$((i+${#chunk[@]})))"
terminate_with_retry "${chunk[@]}"
i=$(( i + ${#chunk[@]} ))
done
# ===== 監視 =====
echo "監視開始 (interval=${WATCH_INTERVAL}s)"
remain=( "${VALID_IDS[@]}" )
while ((${#remain[@]})); do
sleep "$WATCH_INTERVAL"
next=()
j=0
while (( j < ${#remain[@]} )); do
part=( "${remain[@]:j:25}" )
if desc=$(aws "${aws_opts[@]}" workspaces describe-workspaces \
--workspace-ids "${part[@]}" \
--query 'Workspaces[].{Id:WorkspaceId,St:State}' --output text 2>/dev/null); then
while read -r wid st; do
[[ -z "$wid" ]] && continue
[[ "$st" == "TERMINATED" ]] && echo " $wid: TERMINATED" || { echo " $wid: $st"; next+=("$wid"); }
done <<< "$desc"
fi
j=$(( j + ${#part[@]} ))
done
remain=( "${next[@]}" )
echo "残り: ${#remain[@]}"
done
echo "すべて完了"
# ===== 最後に「存在しなかったID」をまとめて表示 =====
if ((${#INVALID_IDS[@]})); then
echo
echo "⚠️ 存在しなかった WorkSpaces ID:"
printf ' - %s\n' "${INVALID_IDS[@]}"
fi
手順3. 下記で権限付与
以下のコマンドで実行権限を付与します。
chmod +x terminate_by_ids.sh
手順4. 実行スクリプトの実行
以下のコマンドを実行します。
./terminate_by_ids.sh
※以下の画像のような手順です。
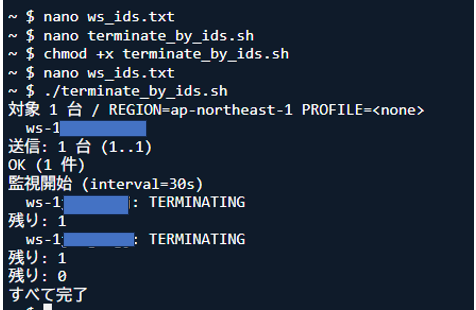
以上。
削除作業は数百台でも数分で完了します!
最後に
以上、CloudShellでのWorkSpaces一括削除スクリプトの紹介でした。
シンプルですが非常に強力な方法ですので、ぜひ参考いただければ幸いです。