



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
マッタクと言っていいほど英語の文章が理解できないので、英文(.png,.jpg)の記載されている画像ファイルから文章を抽出し、APIを利用することで日本語訳に変換してみよと思い立ちました。
これがあれば英字新聞を写真で撮影して、こちらの構築に渡すだけで何が書いてあるか分かるようになるという他力本願まっしぐらでハンズオンをしていきます。
こんな挙動をする
1:英文を読み込むための画像を選択する

2:ターミナルでAPIのレスポンス(日本語訳)を表示して確認することができる
参考資料
参考リンクには今回利用にしたAPIと各種参考にしたURLです
API
参考記事
DeepL APIを利用した翻訳ハンズオン
Pythonでpng画像をテキストに変換する方法【初心者向け】
Python でファイル選択画面を表示する
Catalinaでtkinterを使用して、非推奨の警告を回避する方法は?
サンプル記事のスクリーンショット
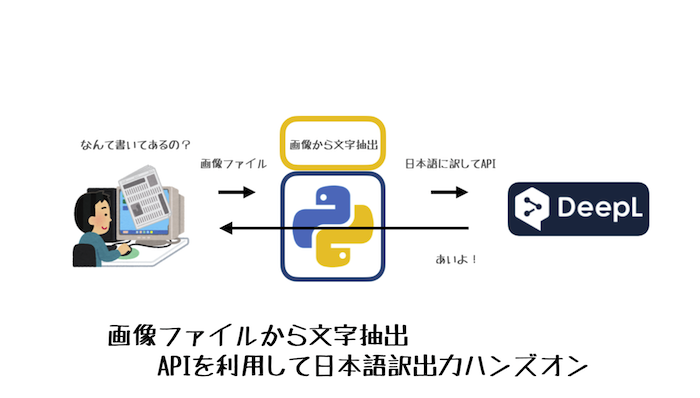
構成図

ハンズオン
1:コードの記述
ディレクトリの構成
/Users/tetutetu214/projects/0_Qiita_hanson
├── .env
| ※環境変数の保存
├── application_form.py
| ※画像から英文を文字で抽出する役割
└── langchange_en_js.py
※抽出した文字をAPIにて日本語訳にする役割サンプルコード(コメントアウトで各動作の内容記述あり)
application_form.py
from PIL import Image #画像を読み込むためのライブラリ
import sys #プログラミングを修了させるモジュール
import langchange_en_js #英文を日本語に変換するモジュールを呼び出す
import pyocr #外部OCRエンジン()を利用可能にするためのモジュール
import pyocr.builders #pyocrをコントロールするためのオブジェクト
import tkinter.filedialog #tkinterを利用しGUIでファイルを選択するためのモジュール
import os #非推奨警告が表示されてたため利用
os.environ['TK_SILENCE_DEPRECATION'] = "1"
#DEPRECATION WARNING: The system version of Tk is deprecated and may be removed in a future release. Please don't rely on it. Set TK_SILENCE_DEPRECATION=1 to suppress this warning.
def ocr_manners(): #OCRが利用できるかの確認
tools = pyocr.get_available_tools() #pyocrのOCRツール類をスキャンしてリスト
if len(tools) == 0: #len関数でリストの要素を確認、OCRツールがリストにないならシステム終了
print("No OCR tool found")
sys.exit(1) # システム終了
return tools[0]# pyocr OCRツールリストの1つ目をreturn
def selection_file(): #画像の選択をGUIで行う
print("画像を選択してください\n画像の中の英文を日本語に変換します\n")
root=tkinter.Tk() #tkinterのインスタンスを生成
root.withdraw() #この一文が無いと謎の黒いウインドウが出てくるので記述
type = [("画像ファイル",'*.png'),("画像ファイル",'*.jpg')] #選択できるファイルの種類
dir = '/Users/inamurateppei/projects/0_Qiita_hanson' #選択画面の最初のページ
return tkinter.filedialog.askopenfilename(filetypes = type, initialdir = dir) #選択された画像ファイルをreturn
def ocr_tool(tool,material): #OCRを利用した画像から文字を抽出する
langs = tool.get_available_languages() #利用できる言語を選択(インストールすれば日本語モデル有り)
lang = langs[0] #今回は英語を利用したモデルを選択
txt = tool.image_to_string(
Image.open(material),
lang=lang,
builder=pyocr.builders.TextBuilder()
)#material変数からイメージ画像を利用して、選択した言語(=英語)を代入
#print(txt) #出力する英文を確認するために利用
langchange_en_js.langchange(txt)# langchange_en_js.langchange関数を利用する
if __name__ == "__main__":
tool_list = ocr_manners()
select_material = selection_file()
ocr_tool(tool_list,select_material)langchange_en_js.py
# ライブラリのインポート
import requests #Endpointにリクエストをするため利用
import json #json形式のレスポンスを整形するため利用
import os #環境変数を使用するため利用
from dotenv import load_dotenv #.envから環境変数を読み込む
load_dotenv()
deepl_auth_token = os.getenv('DEEPL') + "&" #トークン直打ちでも可能
deepl_Endpoint = "https://api-free.deepl.com/v2/translate?" #APIのエンドポイント
Text = "text="
target = "&target_lang=ja" #日本語に変換
source = "&source_lang=en" #元は英語
def langchange(txt):
url = deepl_Endpoint + "auth_key=" + deepl_auth_token + Text + txt + target + source
url_info = requests.get(url) #英文含んだリクエストする
obj = json.loads(url_info.text) #レスポンスをjson形式で整形
print("↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓下記日本語訳部分↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓\n" + obj["translations"][0]["text"] + "\n" + "↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑上記日本語訳部分↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑")# ターミナルに出力する内容
if __name__ == "__main__":
obj = langchange(txt)2:application_formの部分的な説明
2.1 今回利用するライブラリをインストールする
# ライブラリのインポート
from PIL import Image #画像を読み込むためのライブラリ
import sys #プログラミングを修了させるモジュール
import langchange_en_js #英文を日本語に変換するモジュールを呼び出す
import pyocr #外部OCRエンジン()を利用可能にするためのモジュール
import pyocr.builders #pyocrをコントロールするためのオブジェクト
import tkinter.filedialog #tkinterを利用しGUIでファイルを選択するためのモジュール
import os #非推奨警告が表示されてたため利用
os.environ['TK_SILENCE_DEPRECATION'] = "1"主な役割
・画像を読み込みOCRエンジンを利用して文字を抽出するために記述
from PIL import Image
import pyocr
import pyocr.builders
・自作したモジュールを利用するために記述
import langchange_en_js
・GUIで画像ファイルを選択するために記述
import tkinter.filedialog
・『将来削除される可能性がある』という通知を表示させないようにするために記述
import os os.environ['TK_SILENCE_DEPRECATION'] = "1"
DEPRECATION WARNING: The system version of Tk is deprecated and may be removed in a future release. Please don't rely on it. Set TK_SILENCE_DEPRECATION=1 to suppress this warning.2.2 ocr_manners()関数
OCRを利用できるか確認するための関数
def ocr_manners(): #OCRが利用できるかの確認
tools = pyocr.get_available_tools() #pyocrのOCRツール類をスキャンしてリスト
if len(tools) == 0: #len関数でリストの要素を確認、OCRツールがリストにないならシステム終了
print("No OCR tool found")
sys.exit(1) # システム終了
return tools[0]# pyocr OCRツールリストの1つ目をreturn
お作法的な関数な部分もあり割愛
2.3 def selection_file()関数
画像ファイルをGUIで選択するための関数
def selection_file(): #画像の選択をGUIで行う
print("画像を選択してください\n画像の中の英文を日本語に変換します\n")
root=tkinter.Tk() #tkinterのインスタンスを生成
root.withdraw() #この一文が無いと謎の黒いウインドウが出てくるので記述
type = [("画像ファイル",'*.png'),("画像ファイル",'*.jpg')] #選択できるファイルの種類
dir = '/Users/inamurateppei/projects/0_Qiita_hanson' #選択画面の最初のページ
return tkinter.filedialog.askopenfilename(filetypes = type, initialdir = dir) #選択された画像ファイルをreturnocr_manners()関数で、OCRツールを利用できることが利用できる場合の後続の処理となります
当初は画像ファイルのパスを手入力でしたが、GUIで操作するためにtkinterを利用しています
tkinter.filedialog.askopenfilenameを利用してパスではなくて、ファイル自体を選択しています
2.4 ocr_tool()関数
実際にOCRツールを利用して、 2.3 def selection_file()関数から文字を抽出
def ocr_tool(tool,material): #OCRを利用した画像から文字を抽出する
langs = tool.get_available_languages() #利用できる言語を選択(インストールすれば日本語モデル有り)
lang = langs[0] #今回は英語を利用したモデルを選択
txt = tool.image_to_string(
Image.open(material),
lang=lang,
builder=pyocr.builders.TextBuilder()
)#material変数からイメージ画像を利用して、選択した言語(=英語)を代入
langchange_en_js.langchange(txt)# langchange_en_js.langchange関数を利用するlangs = tool.get_available_languages()
lang = langs[0]はコメントアウトもしていますが、日本語モデルを追加することで、後述のlangchange_en_js.pyで呼び出ししなくても同様の動きを実現できるかもしれません
が、ここではlangchange_en_js.langchange(txt)にて、別ファイルのlangchange_en_js.pyを呼び出しを行っていきます
3:langchange_en_jsの部分的な説明
3.1 今回利用するライブラリをインストールする
# ライブラリのインポート
import requests #Endpointにリクエストをするため利用
import json #json形式のレスポンスを整形するため利用
import os #環境変数を使用するため利用
from dotenv import load_dotenv #.envから環境変数を読み込む
load_dotenv()
deepl_auth_token = os.getenv('DEEPL') + "&" #トークン直打ちでも可能
deepl_Endpoint = "https://api-free.deepl.com/v2/translate?" #APIのエンドポイント
Text = "text="
target = "&target_lang=ja" #日本語に変換
source = "&source_lang=en" #元は英語3.2 langchange(txt)関数
def langchange(txt):
url = deepl_Endpoint + "auth_key=" + deepl_auth_token + Text + txt + target + source
url_info = requests.get(url) #英文含んだリクエストする
obj = json.loads(url_info.text) #レスポンスをjson形式で整形
print("↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓下記日本語訳部分↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓\n" + obj["translations"][0]["text"] + "\n" + "↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑上記日本語訳部分↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑")# ターミナルに出力する内容
if __name__ == "__main__":
obj = langchange(txt)レスポンスされるjson形式を整形してターミナル出力をす
4:挙動の確認
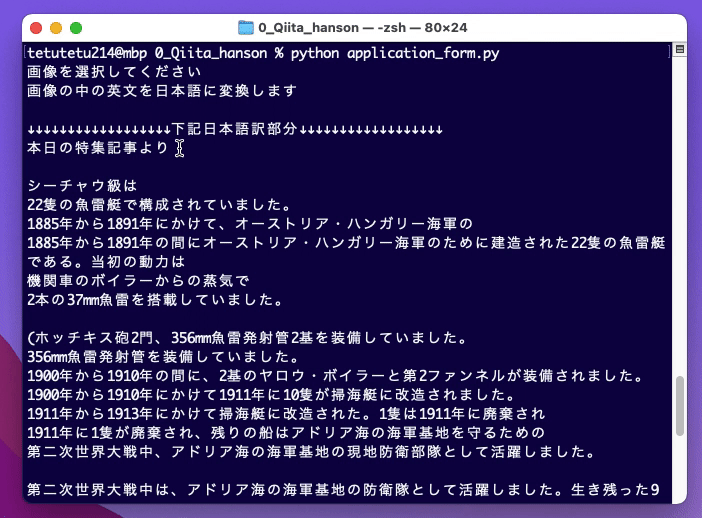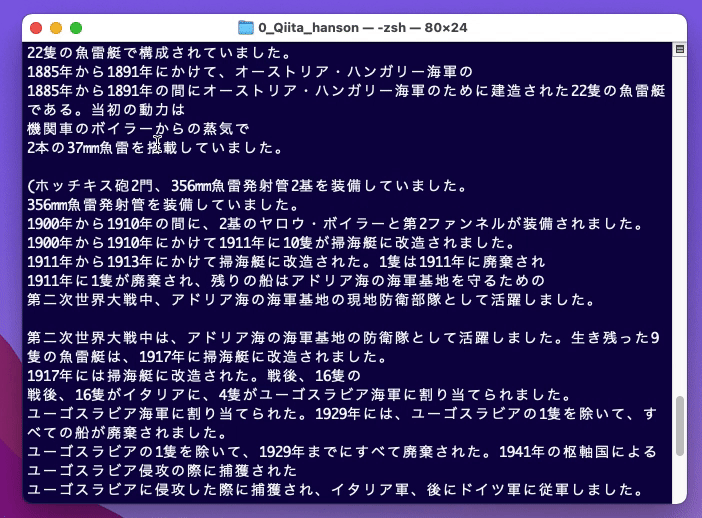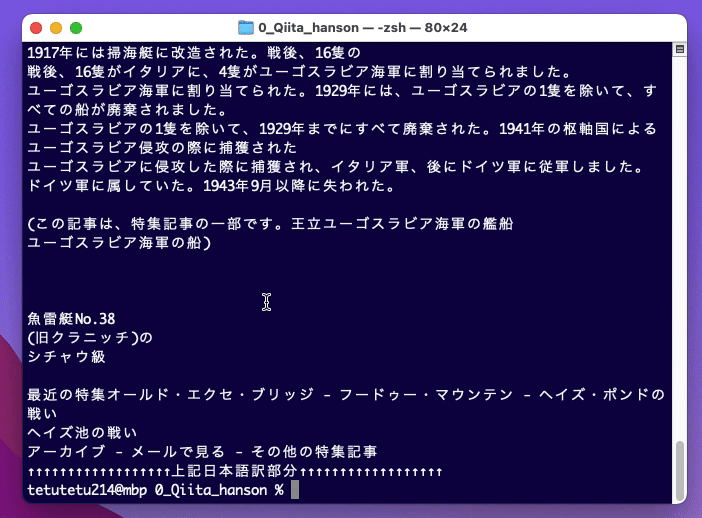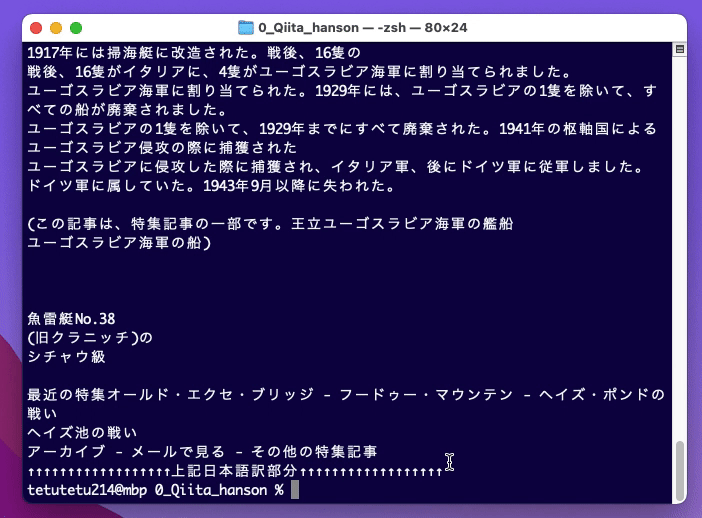
tetutetu214@mbp 0_Qiita_hanson % python application_form.py
画像を選択してください
画像の中の英文を日本語に変換します
処理ファイルをGUIにて選択

利用したtest.png画像(Wikipedia 2022年1月22日のページより抜粋)

↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓下記日本語訳部分↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
本日の特集記事より
****************** 中略 ******************
アーカイブ - メールで見る - その他の特集記事
↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑上記日本語訳部分↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑↑画像ファイルから英文を抽出してAPIにリクエストして、APIからのレスポンス(日本語訳にしてあるという)動きを確認することができました。
さいごに
当初はAmazon Rekognitionのテキスト検出で文章抽出を考えていましたが、日本語に対応していないことからハンズオンの方針を変更して、こちらの構築を行いました。
いままでの構築では別ファイルの関数呼び出しをしたことがなかったので、pyocrで日本語モデルをインストールすればAPIを叩かなくてよかったのかもしれなかったのですが、このような方法を選択しました。
GUIでファイルを選択するや、非推奨の警告などを出力しないようにするなど手を動かさないと分からないことも多々あり、記事を書いている終盤『画像ファイルを選択しなかった場合』の挙動について抜けていることにも気が付きました、、、いつか修正す、、、る?
また来週もコードを書きながら理解を深めていきたいと思います。