




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
AWS Summit Japan 2024のセッション「アーキテクチャ道場2024!」においての内容と学びをまとめたいと思います。
AWS Summit Japan 2024の雰囲気はこちらの記事をご覧ください。
AWS Summit JAPAN 2024参戦レポート!
アーキテクチャ道場とは
アーキテクチャ道場とは、「お題」に対して最適なアーキテクチャの提案を解説いただけるセッションです。
設計の経験がなくても、SAPを取得していたり、設計を勉強したい方にもおすすめのセッションです。
お題は2つありましたが、今回は1つ目のお題について学んだことをまとめたいと思います。
お題
一つ目のお題は以下のような内容でした。
※資料から引用

用語のお勉強
■バイナリー障害とは?
システムが正常に動作するか、完全に異常な動作をするかのいずれかの状態を取る障害。
■グレー障害とは?
観測される状態が視点によって変化する障害。
インフラの死活監視には成功するがアプリケーションは正常に応答しない、依存する⼆つのコンポーネントが互いに相⼿に異常が発⽣したとみなす障害。
■ブラウンアウトとは?
機能は完全に失われていないが部分的または一時的なサービス低下している状態。
パフォーマンスが次第に悪化していく、レスポンスのエラーレートが上昇する、死活ステータスが断続的に切り替わる等。
お題1のアーキテクチャ
・Route53、ALB、EKS、Auroraで構成されており、同一リージョン内の3つのAZに冗長化されている状態。
・想定する障害はAZ1全体に影響するブラウンアウト。
・利用中のAWSサービスは別のサービスに変更せずに、AWSの設計の見直しを行う。
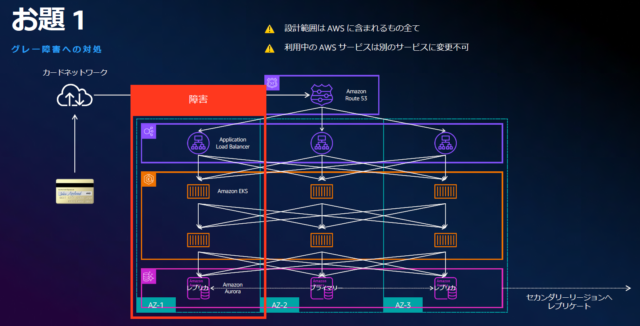
※資料から引用
アーキテクチャ検討⽅針
【対処法.1】
AZを隔離しやすくするために、AZ間の独立性を高めた設計にする。
つまり、AZを跨ぐ通信や処理を極力排除する必要がある。
【対処法.2】
障害を「検知」し、自動で「隔離」をすることで他のAZに影響のないアーキテクチャを実装する。
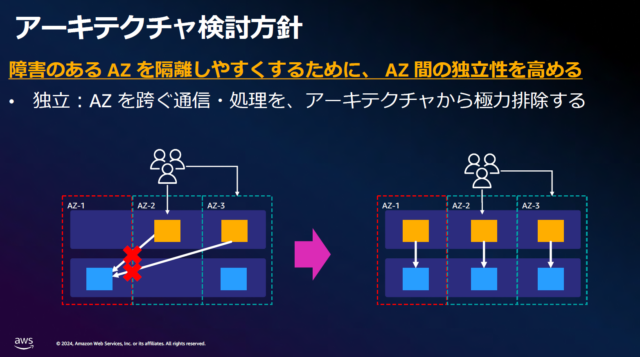
※資料から引用
対処法.1:AZ間の独立性を高めた設計
①ALB のクロスゾーン負荷分散をオフにする。
②すべてのAZにPodが存在する必要があるので、個別のAZにFargate Profileを作成して、各AZごとにDeploymentを作成する。
③KubernetesのサービスディスカバリはAZを跨ぐため、バックサービスをAZごとに作成し、各AZのフロントサービスからのエンドポイントとして環境変数に個別に指定する。
④バックサービスのDB参照は、各AZのインスタンスを指すカスタムエンドポイントを作成し、各AZのバックサービスからのDBエンドポイントとして指定する。

※資料から引用
⑤バックサービスのDB更新は、クラスターごとにプライマリーインスタンスは1つしか持てないため、AZ-1、AZ-3 からのDB書き込みはAZを跨ぐことを許容する。
※各AZでクラスタを構築して更新系クエリをAZ 内で完結させることは可能だが、データの⼀貫性・冗⻑性のリスクがあるため採⽤しない!
AZ間の独立性を高めたアーキテクチャがこちら
このようにアプリケーションの中に障害の範囲を限定するための隔壁を設けるアーキテクチャスタイルを「バルクヘッド」という。
※「バルクヘッド(Bulkhead)」は、元々船舶の設計に由来する用語で、船体を複数の区画(バルクヘッド)に分けて、ある区画が浸水しても他の区画に影響を及ぼさないようにする仕組みのこと。
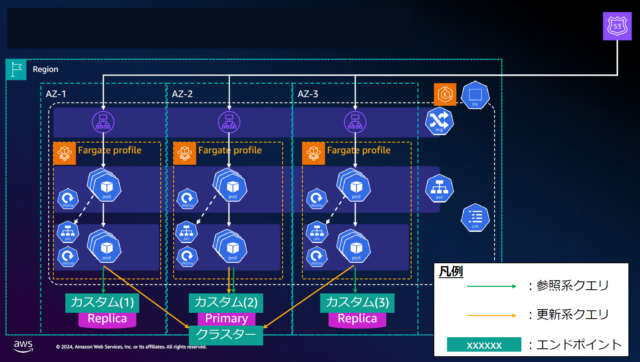
※資料から引用
対処法.2:障害を「検知」し、自動で「隔離」
【AZ-1全体にわたる障害想定と影響】
AZ-1内部…AZ-1へのリクエスト全体でエラー率・レイテンシが増加する。
AZ間通信…AZ-1→プライマリDBへのアクセスでエラー率・レイテンシが増加する。
【障害検知】
AZ-1の障害ならばAZ-1を隔離し、他の原因の場合は別対処をするように障害を検知する。
↓↓↓
複合条件で検知を行う場合は<< Amazon CloudWatch 複合アラーム >>を利用する。
以下のように複数のアラームをAND、ORで組み合わせることが可能。
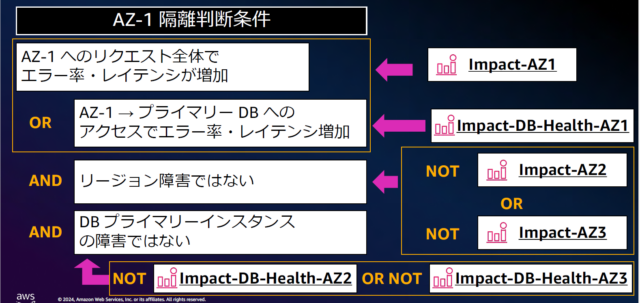
※資料から引用
【各アラームの詳細】
■アラーム名「Impact-AZ1」
以下を[ErrorRate-AZ1] OR [Latency-AZ1] として設定する。
[ErrorRate-AZ1]
メトリクス:エラー率(Metric Mathで算出)
AZ: AZ-1
閾値: >3%
回数: 5分中3分
[Latency-AZ1]
メトリクス:レイテンシ
AZ: AZ-1
閾値: >100ms
回数: 5分中3分
※アラーム名「Impact-AZ2」「Impact-AZ3」も同様の設定を行う。
・
・
■アラーム名「Impact-DB-Health-AZ1」を設定する前に・・・
各AZからプライマリDBへのヘルスチェックが必要となるため、以下の実装を行う。
・最前段にNLBを配置し、配下のサービスでプライマリDBへのヘルスチェッククエリを実行する。
※NLBを配置する理由は、AZ指定でリクエストするため!
・ワークロード本体同様にAZごとに独立させる。
・AZごとにCloudWatch Syntheticsを作成し、ヘルスチェックリクエストのメトリクスを取得する。
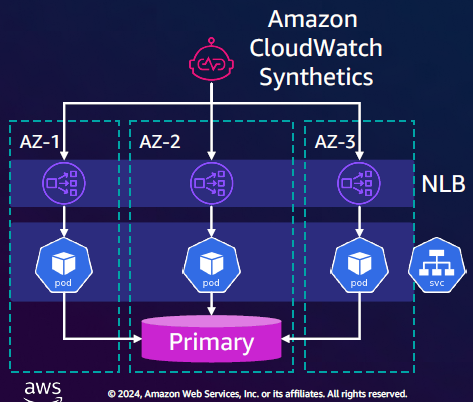
※資料から引用
アラーム名「Impact-DB-Health-AZ1」
以下を[DB-Health-Success-AZ1] OR [DB-Health-Latency-AZ1] として設定する。
[DB-Health-Success-AZ1]
メトリクス: 成功率
AZ: AZ-1
閾値: 50ms
回数: 5分中3分
[DB-Health-Latency-AZ1]
メトリクス: レイテンシ
AZ: AZ-1
閾値: >50ms
回数: 5分中3分
※アラーム名「DB-Health-Success-AZ2」「DB-Health-Success-AZ3」も同様の設定を行う。
上記を複合アラームとして設定。

※資料から引用
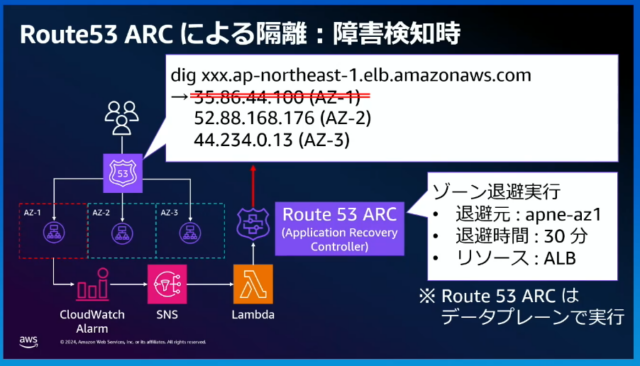
【AZ-1の隔離】
AZ-1の障害を検知したら、CloudWatch Alarm→SNS→LambdaでRoute53 ARC(Application Recovery Controller)を起動し、ゾーンシフトを使用してAZ-1のDNSレコードを削除し、AZ-1を隔離する。
※ゾーンシフト:あるリソースを、あるAZから一定時間退避させることができる。
まとめ
障害の種類、バルクヘッドのアーキテクチャ、検知方法、自動隔離方法まで、幅広い学びがありました。
一つのアーキテクチャから知らなかった機能を知るきっかけになるので、いろんなアーキテクチャを勉強していきたいと思います。
ちなみにお題2は更にハイレベルなアーキテクチャでした。
以下より2024年7月5日までオンデマンド配信しておりますので、ぜひ見てみてください。(要ログイン)
https://japansummit.awslivestream.com/