




はじめに
仕事の都合で最近は、Geminiばっかりの毎日です。
Geminiの特徴としてはマルチモーダルが挙げられるかと思いますので、AWS環境からS3に保存したPDFをGeminiで内容要約してもらおうと思ったのでハンズオンをしてみます。
マルチモーダルAI(Multimodal AI)とは?
- テキスト、画像、音声、動画、数値データなど、複数の異なる種類のデータ(モダリティ)を一度に処理できる統合されたAIモデル。
- 複数のデータ源から得られた情報を組み合わせることで、より人間らしい文脈に応じた理解や出力を実現することが可能となる。
マルチモーダルの性能・コスト
- マルチモーダルに対応している、AWSとGoogle Cloudの主なモデル比較
表:マルチモーダルAIモデルのコスト比較 (2025年2月23日時点)
| 項目 | AWS | Google Cloud |
|---|---|---|
| モデル名 | Amazon Nova pro | Gemini 2.0 flash |
| 最大入力トークン | 300,000 | 1,048,576 |
| 最大出力トークン | 5,000 | 8,192 |
| $ / 1M input tokens | $0.80 | $0.10 |
| $ / 1M output tokens | $3.20 | $0.40 |
参照ドキュメント:Amazon Nova モデル
参照ドキュメント:Amazon Nova Pro料金
参照ドキュメント:Gemini モデル
ハンズオン
構成図
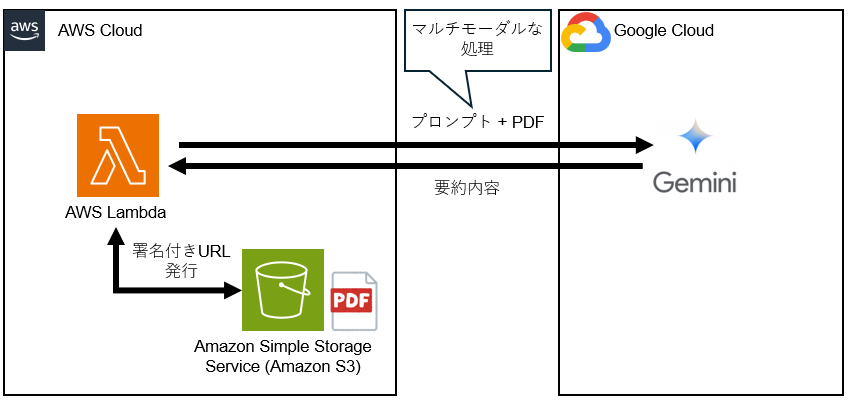
1.Google Cloudの準備
- 以下ブログを参考にGoogleCloudの設定をする。
参照ブログ:AWS Lambda から Gemini APIを利用した呼出しハンズオン
2.S3の準備
- 「マネジメントコンソール」画面から「S3」画面へ遷移します。
- 「バケットを作成」を選択し、新規バケットを作成する。
- 以下設定を入力して「作成」を押下します。
| バケット名 | それ以外の設定 |
|---|---|
| ${バケット名} | デフォルト |
3.Lambdaレイヤーの準備
3.1.ライブラリのインストール
- マネジメントコンソール右上 [>.] アイコンより、Cloudshellの起動します。
- 以下コマンドを実行します。
# ディレクトリの作成
mkdir python
# 作成したディレクトリにライブラリをインストール
pip install google-genai httpx -t python
# ライブラリをZIP圧縮
zip -r layer.zip python- コマンド実行後、「アクション > ファイルのダウンロード」をクリックして「layer.zip」をローカルにダウンロードします。
3.2.Lambdaレイヤーの作成
- 「マネジメントコンソール」画面から「Lambda」画面へ遷移します。
- 左ペイン「レイヤー」を選択し「レイヤーの作成」を押下します。
- 以下設定を入力して「作成」を押下します。
| 名前 | .zipファイルをアップロード | 互換性のあるアーキテクチャ | 互換性のあるランタイム |
|---|---|---|---|
| ${Lambdaレイヤー名} | ダウンロードした「layer.zip」 | x86_64 | Python 3.9 |
4.Lambdaの構築
4.1.Lambda構築
- 「マネジメントコンソール」画面から「Lambda」画面へ遷移します。
- 「関数を作成」押下します。
- 設定画面にて以下設定を入力して「関数の作成」押下します。
| 関数名 | ランタイム | アーキテクチャ |
|---|---|---|
| ${Lambda関数名} | Python 3.9 | x86_64 |
4.2.コード
- 以下コードソースを上書きして「Deploy」を押下します。
import os
import boto3
import httpx
from google import genai
from google.genai import types
def lambda_handler(event, context):
s3 = boto3.client("s3")
# S3パスからバケット名とキー抽出
bucket_name = os.environ.get("BUCKET_NAME")
file_name = os.environ.get("FILE_NAME")
#署名付きURLの生成
url = s3.generate_presigned_url(
ClientMethod="get_object",
Params={"Bucket": bucket_name, "Key": file_name},
ExpiresIn=3600,
)
#Geminiへのプロンプト
api_key = os.environ.get("API_KEY")
client = genai.Client(api_key=api_key)
doc_url = url
doc_data = httpx.get(doc_url).content
prompt = "このドキュメントを要約して下さい"
response = client.models.generate_content(
model="gemini-2.0-flash",
contents=[
types.Part.from_bytes(
mime_type="application/pdf",
data=doc_data
),
prompt]
)
print(response.text)
return {
"statusCode": 200,
"body": response.text
}4.3.その他Lambdaの設定変更
4.3.1.レイヤー
- 「レイヤーの追加」を押下して、以下設定を行う。
| レイヤーソース | レイヤー選択 | バージョン |
|---|---|---|
| カスタムレイヤー | ${Lambdaレイヤー名} | 1 |
4.3.2.環境変数
- 「設定」の左ペイン「環境変数」を押下して、以下設定を行う。
| キー | 値 |
|---|---|
| API_KEY | ${1.Google Cloudの準備で取得した値} |
| BUCKET_NAME | ${2.S3の準備で作成したバケット名} |
| FILE_NAME | ${要約したいファイル名} |
※簡易検証のためAPIキーを環境変数に設定しています。ただし本番利用の際は、AWS Secrets Managerなどを利用してセキュアに運用ください。
4.3.3.一般設定
- 「設定」の左ペイン「一般設定」を押下して、以下設定を行う。
| タイムアウト |
|---|
| 5分 |
※Geminiに要約してもらうPDFの内容により、各自適切な値に修正する。
4.3.4.アクセス権限
- 「設定」の左ペイン「アクセス権限」の「ロール名」を押下する。
- IAMロールの編集画面遷移後、「許可を追加 > ポリシーをアタッチ」を押下する。
- 「AmazonS3FullAccess」 を検索・チェックを入れて「許可を追加」を押下する。
※簡易検証のため「AmazonS3FullAccess」を利用しています。ただし本番利用の際は、必要最小限の権限に変更ください。
5.実行結果
- 今回、自身の経歴書をPDFに与えて要約を実行しました。
- 以下ログが出力されました。
※職務経歴部分も出力されましたが、表記には(以下略)として記載。
Status: Succeeded
Test Event Name: test
Response:
{
"statusCode": 200,
"body": "承知いたしました。以下にドキュメントの要約を示します。\n\n**概要:**\n\nこのドキュメントは、稲村鉄平氏の業務経歴書です。AWS関連の資格を複数取得しています。\n\n**スキル:**\n\n*クラウド: AWS全般\n\n**職務経歴:**\n\n(以下略)
}
Function Logs:
START RequestId: 8d1897c5-f21d-463d-b3eb-ebff27e4c968 Version:
$LATEST
承知いたしました。以下にドキュメントの要約を示します。
**概要:**
このドキュメントは、稲村鉄平氏の業務経歴書です。AWS関連の資格を複数取得しています。
**スキル:**
* クラウド: AWS全般
**職務経歴:**
(以下略)
END RequestId: 8d1897c5-f21d-463d-b3eb-ebff27e4c968
REPORT RequestId: 8d1897c5-f21d-463d-b3eb-ebff27e4c968 Duration: 9313.41 ms Billed Duration: 9314 ms Memory Size: 128 MB Max Memory Used: 124 MB Init Duration: 1261.67 ms
Request ID: 8d1897c5-f21d-463d-b3eb-ebff27e4c968おわりに
得られた知見
- Gemini API を利用してマルチモーダル処理をするための一連のステップの理解。
今後の課題
- 抽出内容が実際に合っているのかという、合致性を確認するためのの方法を考える(RAGASによる評価指標 (ROUGEスコアなど) の利用等)
- 上記合致性の確認方法の自動化