



はじめに
たまたまGlueを使ってS3内のデータをRDSに書き込む機会があったのですが、GlueとRDSを接続する手順が複雑だったので、備忘録としてブログに残しておこうと思います。
アイキャッチ画像はETLの抽出、変換、書き出しをカブトムシの育成過程で強引に表現したもの。
S3という土から卵を抽出→成虫まで変換→RDSという虫かごに書き出し。
あまり気にしないでください。
大まかな流れ
下記の流れでGlueとRDSを接続します。
①コネクター作成
②クローラ作成
③ETL Jobs作成
準備
以下リソースは予め作成しておきましょう。
・DBインスタンスの作成
・データベース、テーブルの作成
DBインスタンスを作成したら、データベース、テーブルを作っておきます
・S3用VPCエンドポイント
・カスタマー管理ポリシー
下記を許可しておきます
「s3:GetObject」「s3:PutObject」
・Glue用IAMロール
追加するポリシーは下記の2つ
・AWS管理ポリシー:AWSGlueServiceRole
・上記カスタマー管理ポリシー
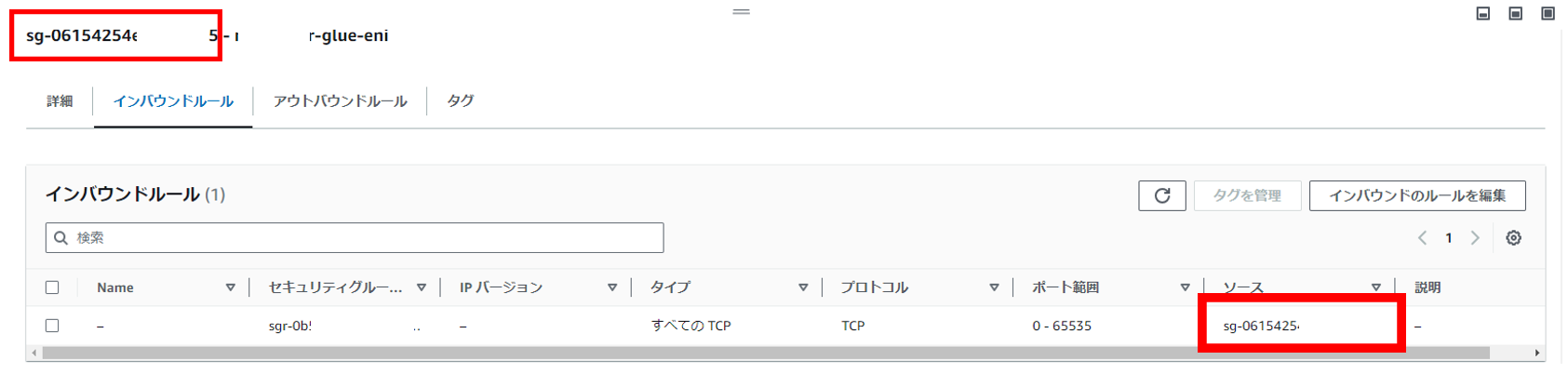
・GlueのENI用のセキュリティグループ
インバウンドルールにはセキュリティグループ自身のIDを設定します
こちらのセキュリティグループをRDSに設定するセキュリティグループのインバウンドルールに許可しておきます
接続から書き込みまで
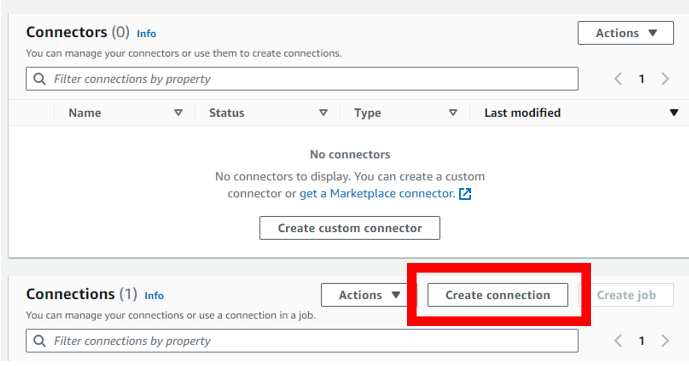
コネクターを作成する
マネジメントコンソールからGlueの画面を開き「Connections」、「Create connection」をクリックする。
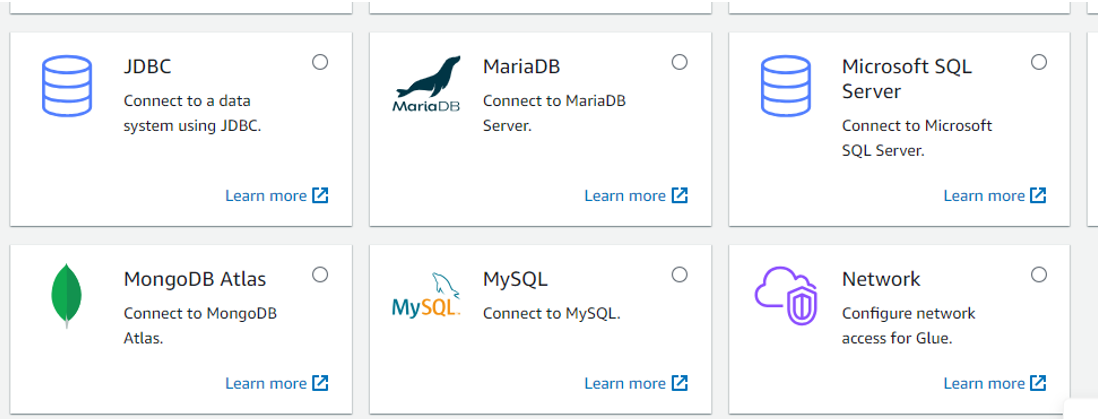
GlueジョブのターゲットとなるDBのエンジンを選択。
※当ブログではMySQLを選択しています
詳細を設定する
「Database instance」は予め作成しておいたDBインスタンスを選択
「Database name」はDBインスタンス内で作成したデータベース名を入力
DBインスタンス作成時に設定したユーザー名とパスワードを入力
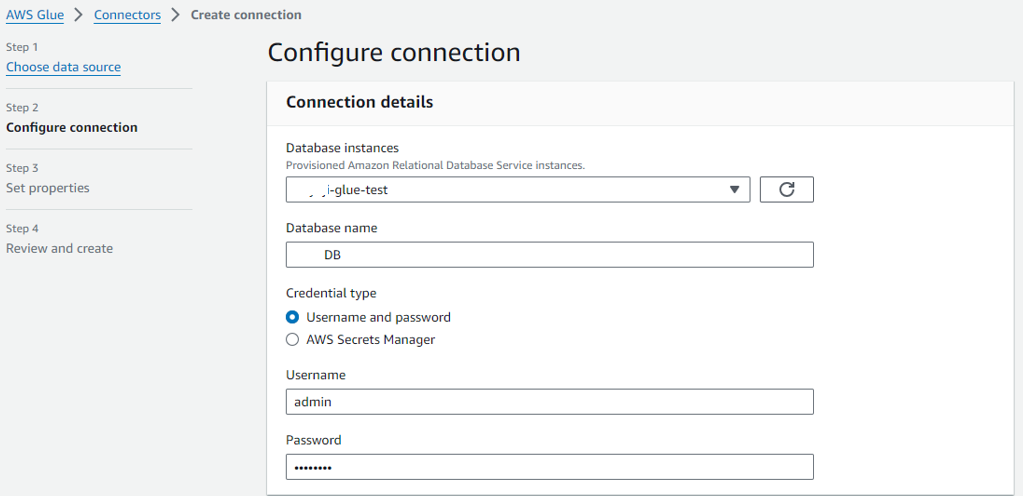
VPC、サブネットはDBインスタンスを作成したものと同じにする
DBインスタンスに割り当てるセキュリティグループには予め作成しておいたGlueのENI用セキュリティグループをインバウンドで許可しておきます。
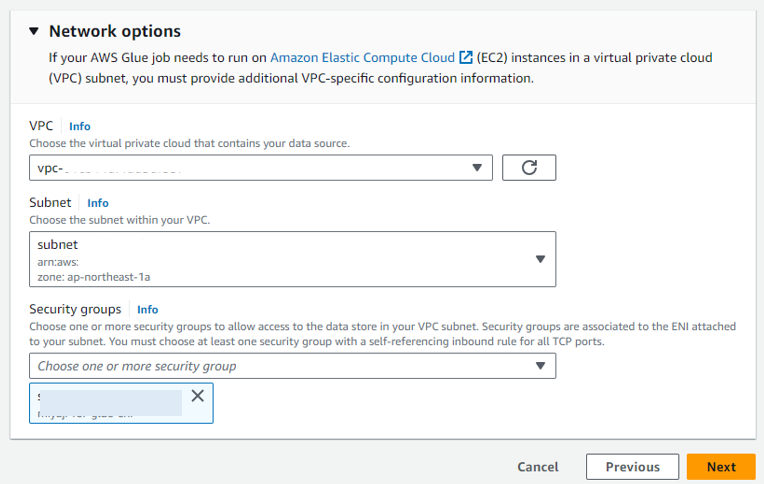
「Name」に任意の名前を入力します。
最後にレビュー画面で「Create connection」をクリックします。
「Connections」が作成されます。
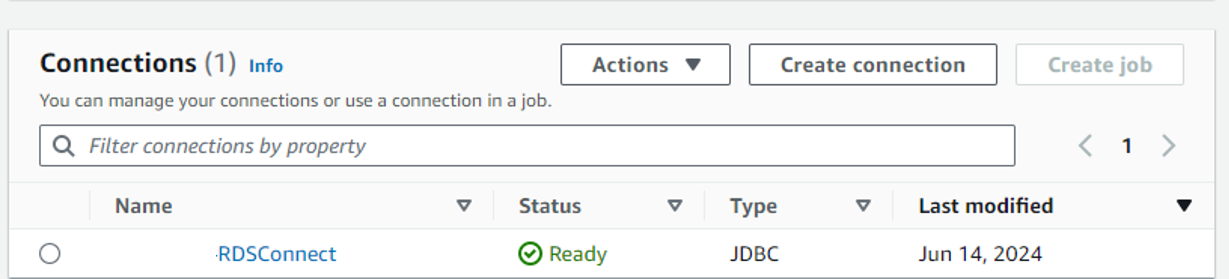
余談ですが、Connectionsの画面からETLジョブを作成することも可能ですが、その場合ビジュアルエディターは対応していません。
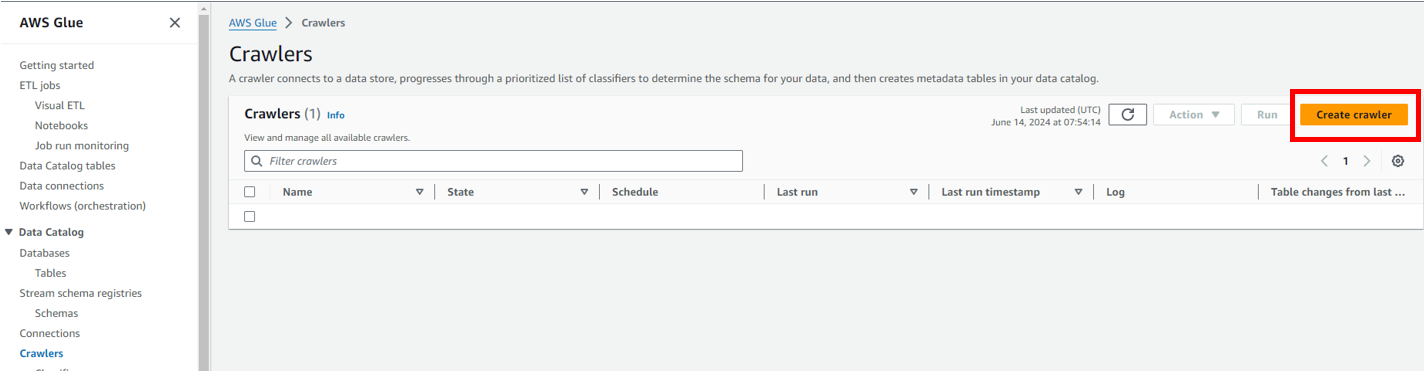
クローラを作成
「Create crawler」をクリックします。
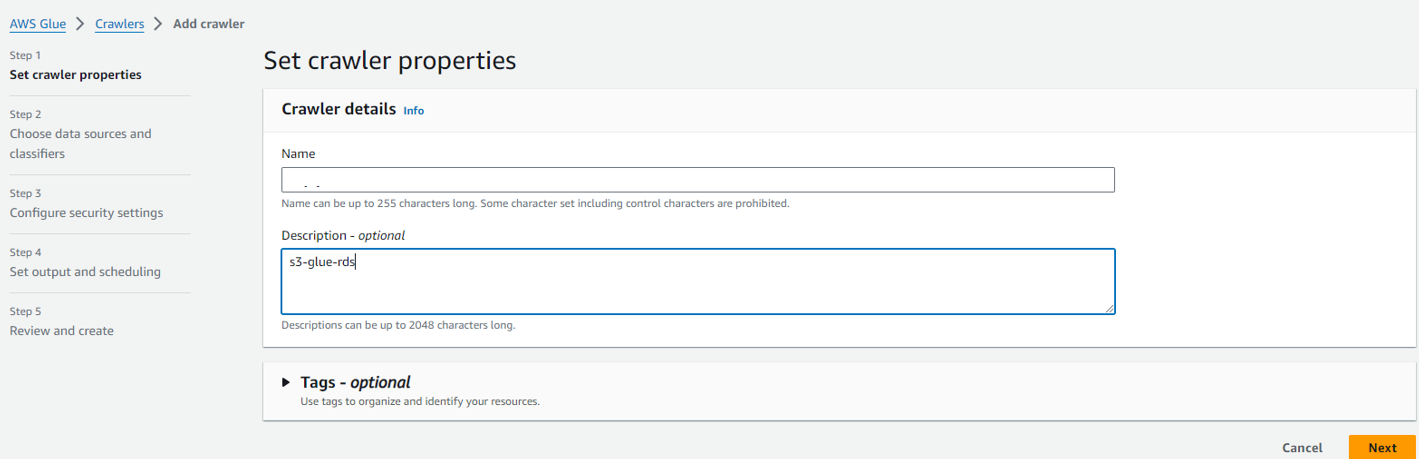
「Name」に任意の名前を入力します。
※「Description」はあってもなくても構いません。
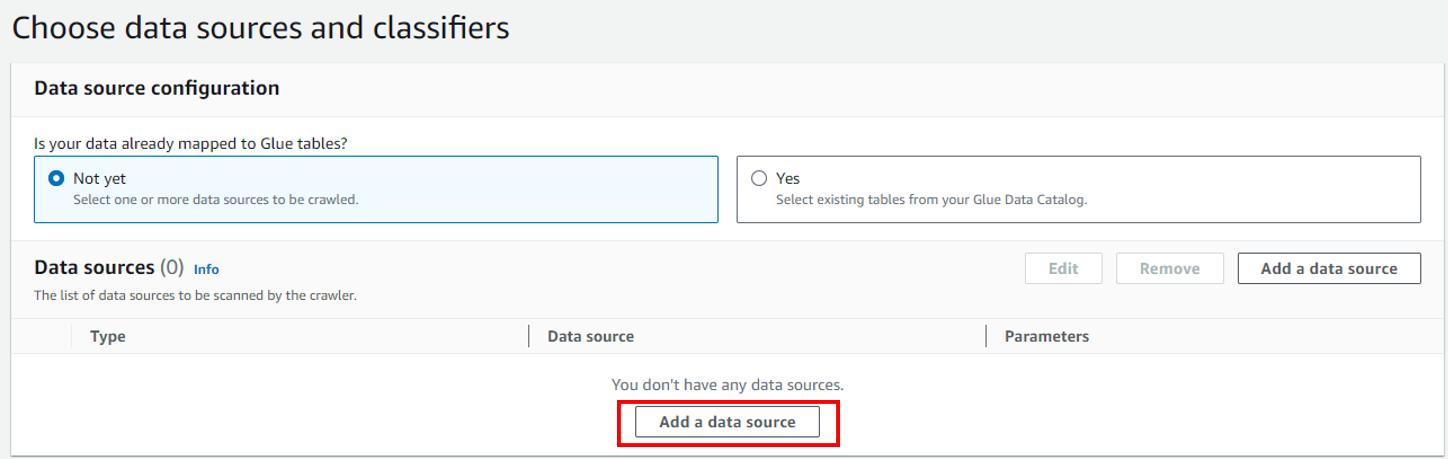
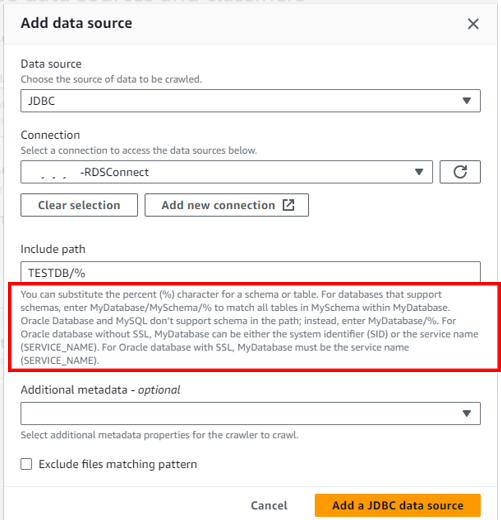
「Add a data source」をクリックします。
「Data source」はJDBCを選択
「Connection」は上記で作成したConnectionを選択
「Include path」はDBエンジンごとに決まっている(以下キャプチャ赤枠内参考)
※MySQLの場合はRDS内に作成したデータベース名 + /% と入力する
「Add a JDBC dara source」をクリックする
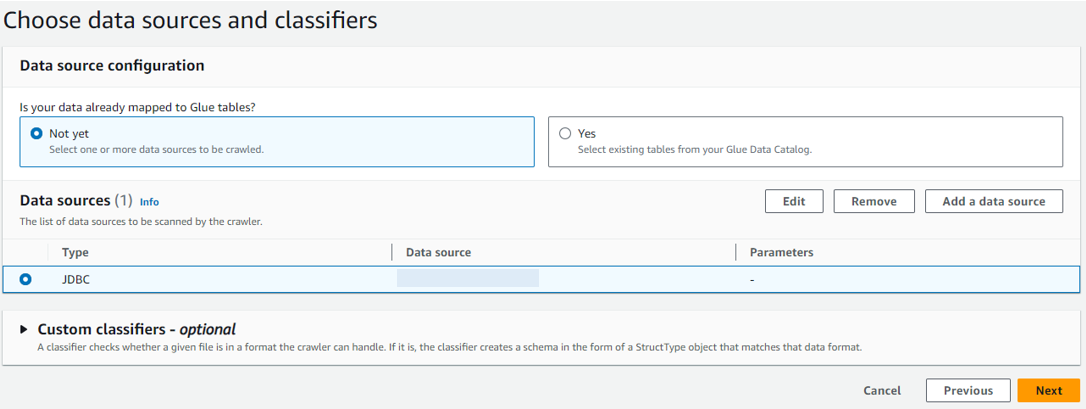
「Data source」が追加されたので、「Next」をクリックします。
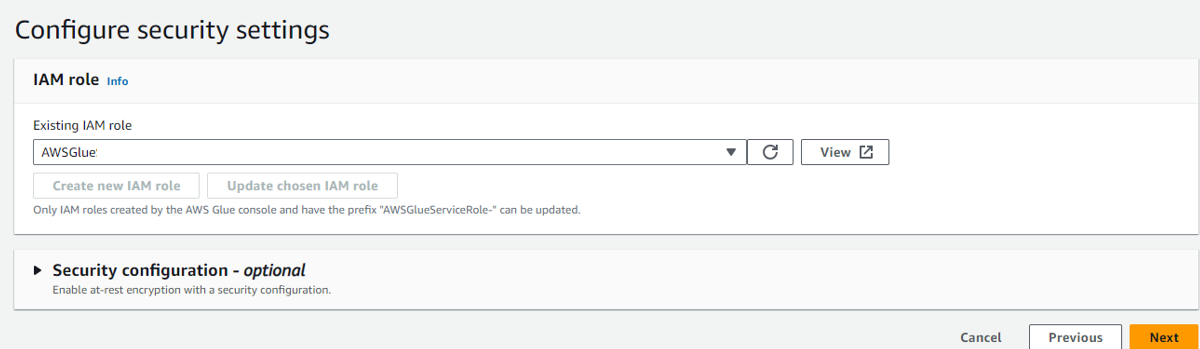
予め作成したGlue用IAMロールを選択します。
「Add database」をクリックします。
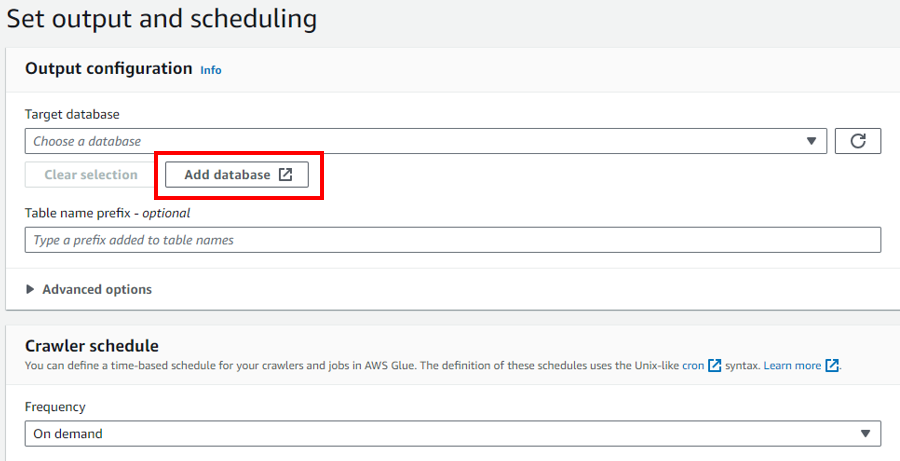
「Name」に任意の名前を入力し、「Create database」をクリックします。
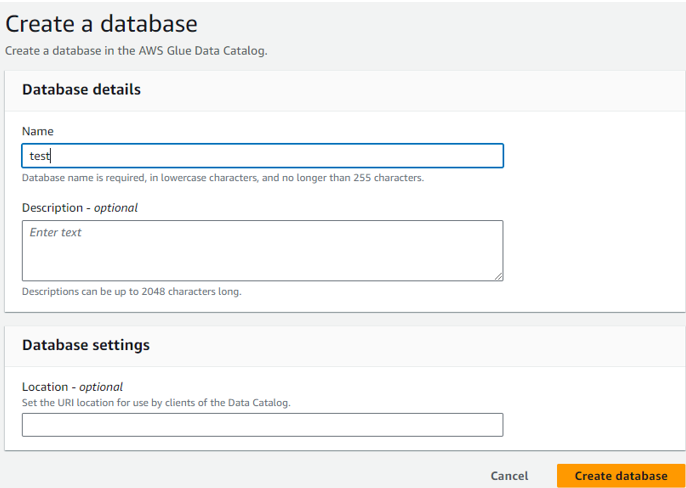
作成したdatabaseを追加し、「Next」をクリックします。
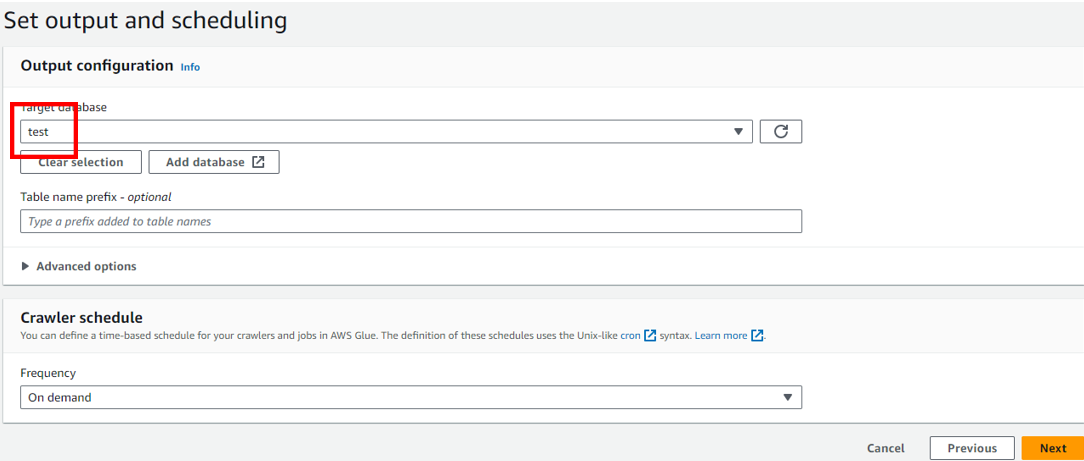
レビュー画面で「Create crawler」をクリックしクローラを作成します。
DatabaseにTableを作成
作成したクローラの画面で「Run crawler」をクリックします。
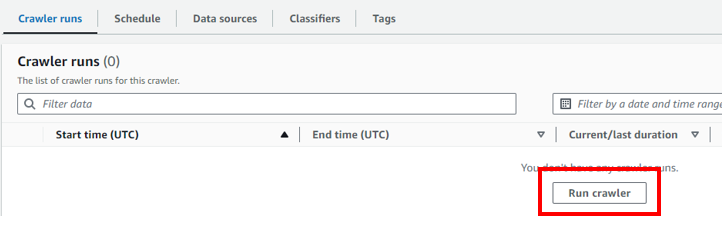
しばらく経過するとStatusが「Completed」に遷移しRun crawlerが完了します。
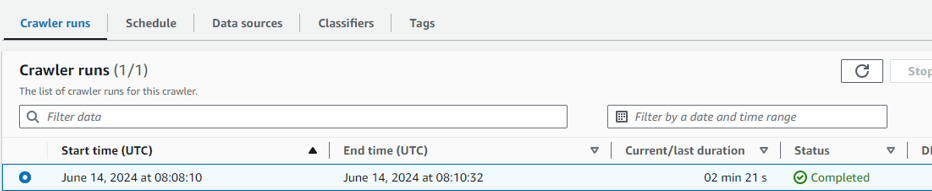
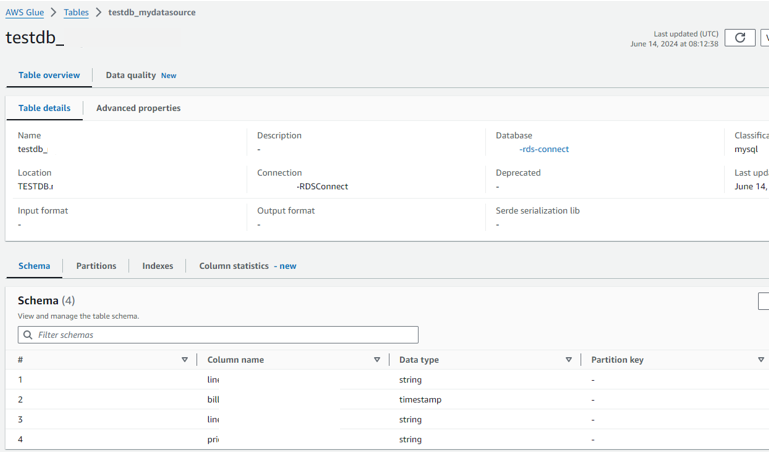
Create crawlerの画面で追加したDatabaseにTableが作成されています。
RDSのDB内に作成していたスキーマ情報が取得されていますね。
ETLジョブを作成する
「Visual ETL」をクリックします。
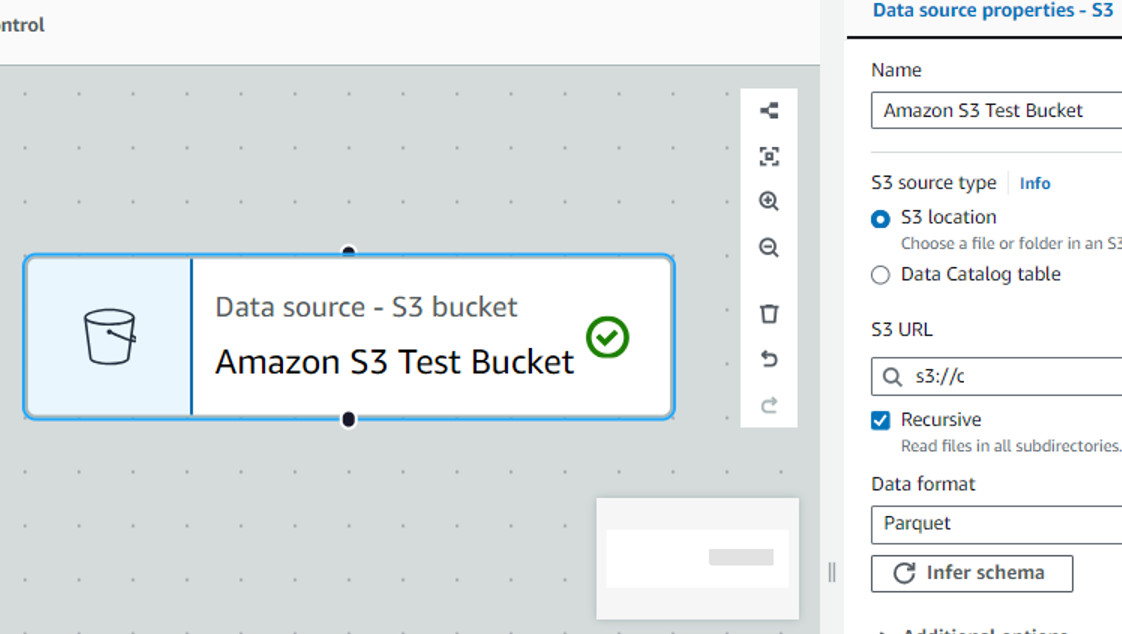
「Add nodes」の「Soueces」から「Amazon S3」を選択します。
「Name」には任意の名前を入力
「S3 URL」には抽出元のS3オブジェクトのURLを入力
「Data format」は当ブログではParquetを選択
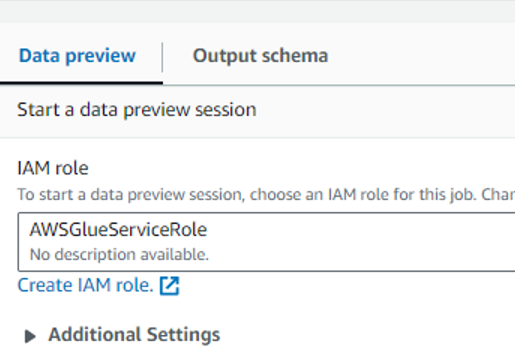
予め作成しておいたGlue用IAMロールを設定します。
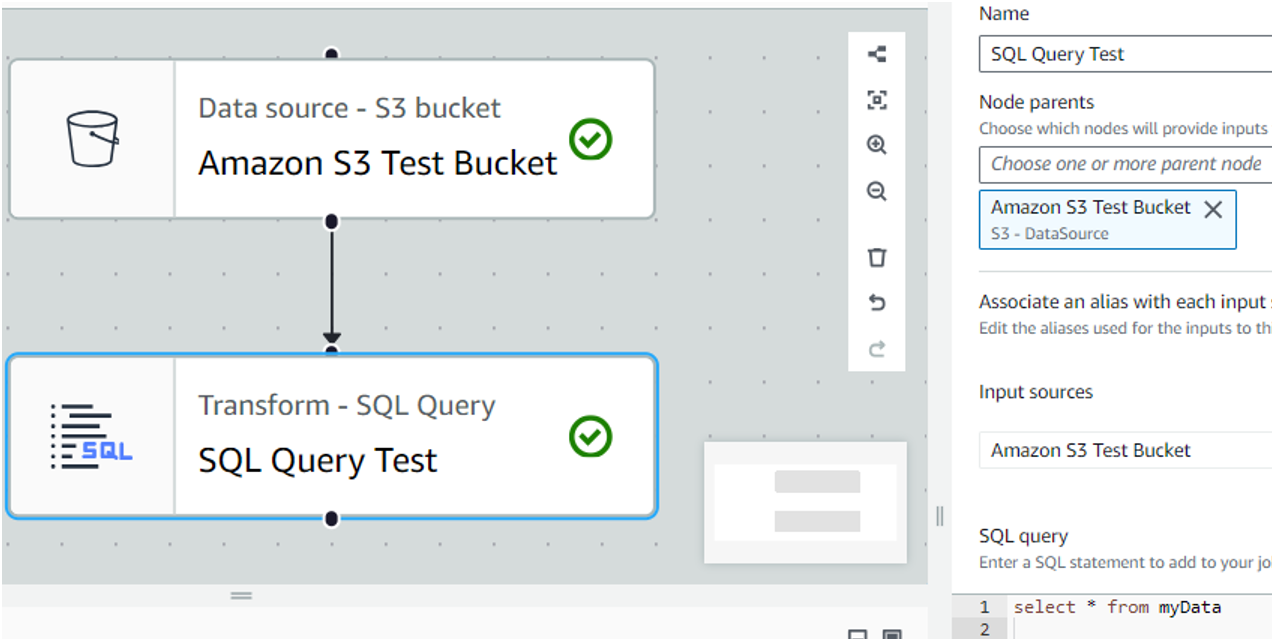
「Add nodes」の「Tranceforms」から「SQL Query」を選択します。
「Name」には任意の名前を入力
「Node parents」にはSourcesのS3を選択
「SQL Query」に実行したいSQL文を入力
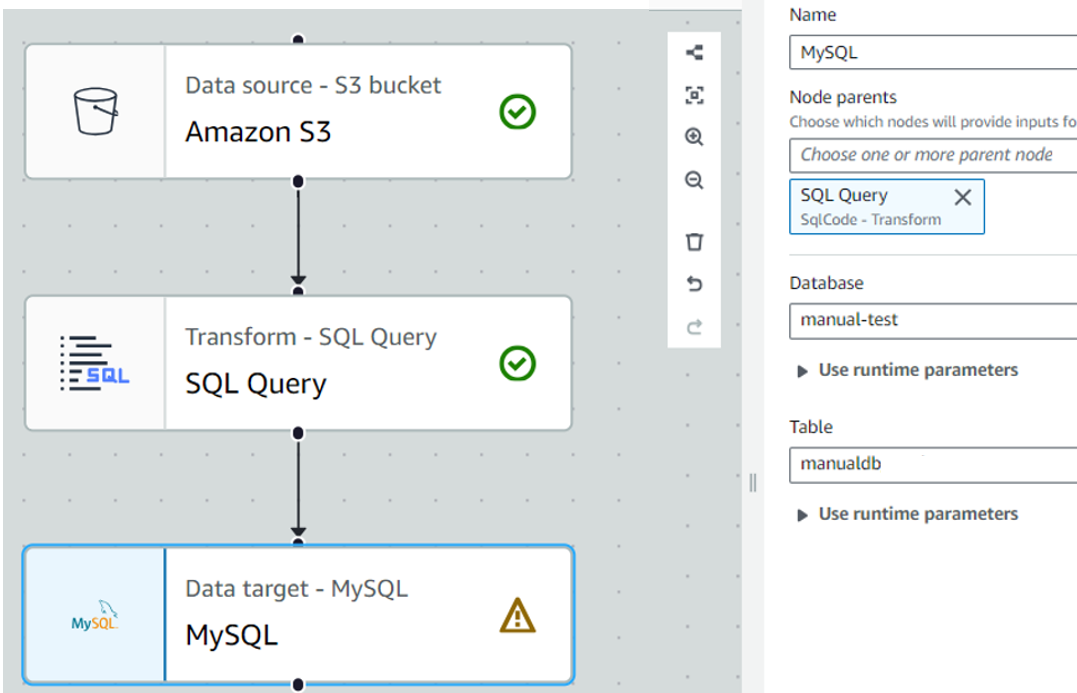
「Add nodes」の「Targets」から「MySQL」を選択します。
「Name」には任意の名前を入力
「Node parents」にはTranceformsのSQL Queryを選択
「Database」、「Table」にクローラを作成する際に作成したDatabaseとTableを選択
一旦ジョブを保存
ここまで進めたらジョブを保存しましょう。(どのタイミングでもいいんですが)
画面左上の「Untitled job」を任意の名前に変更
画面右上の「Save」をクリックする
ジョブを実行する
「Runs」タブから「Run job」をクリックします。
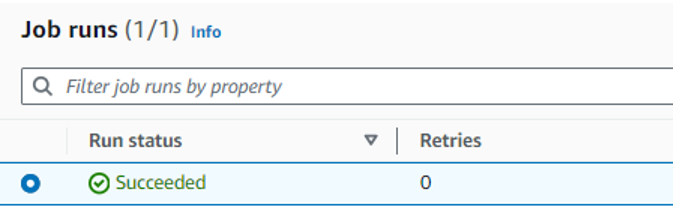
しばらく経過すると「Run status」が「Succeeded」に遷移します。
RDSのDBを確認するとデータが書き込まれています。

以上でGlueとRDSの接続手順になります。
最後に
当ブログを書くきっかけとなったタスクについてなんですが、S3とSQL Queryは予め準備されており、私の役割はGlueとRDSを繋ぐことでした。
最初Visual ETLの画面を見て「なんや、RDS作っといて画面からMySQL選ぶだけやんけ」と思ったのですが、MySQLを選択してもRDSインスタンス名が表示されず、あれ?どういうこと?ってなりました。色々調べつくし今回の手順で実現することができました。
このブログの内容が今後誰かのお役に立てれば、幸いです。
ありがとうございました。