




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
こんにちは!クラウド事業本部のいなむら(INAMURA)です。
Amazon Bedrock Data Automation(以降、BDA)がリリースされました。
こちらは非構造化データを効率的に処理し、インサイトを生成すもので、今回はBDAの基本機能を試してみました。
2024/12/04 What’s New
Amazon Bedrock Knowledge Bases now processes multimodal data
BDAユーザーガイド
BDA APIユーザーガイド
Using the Bedrock Data Automation API
BDAのポイント
1行まとめ
BDAは非構造化データ(音声や動画ファイル、大きなテキストドキュメントなど、そのサイズ、あるいは性質的にデータテーブルにきちんと収まらないデータ)をAIで自動処理し、有用なインサイトを生成するサービスです。
構造データと非構造データについて
参照URL:構造化データと非構造化データの違いは何ですか?
ポイントの詳細
| No | タイトル | 概要 |
|---|---|---|
| 1 | 非構造化マルチモーダルコンテンツからの抽出 | ドキュメント、画像、オーディオ、ビデオなどの非構造化のマルチモーダルコンテンツから情報を抽出可能。 |
| 2 | ワークフローの構築を支援 | インテリジェントドキュメント処理 (IDP)、メディア分析、および検索拡張生成 (RAG) を迅速かつ費用対効果の高い方法で構築が可能。 |
| 3 | アウトプットをカスタマイズ | 特定のビジネスニーズに合わせて出力形式のカスタマイズが可能。スタンドアロン機能として使用することも、RAG ワークフローのナレッジベースを設定する際のパーサーとしても使用が可能。 |
ハンズオン
前提
以下のリージョンで実行しています。
| No | リージョンコード | リージョン名 |
|---|---|---|
| 1 | us-west-2 | オレゴン |
1.左ペインの「データオートメーション」の「デモ」を押下
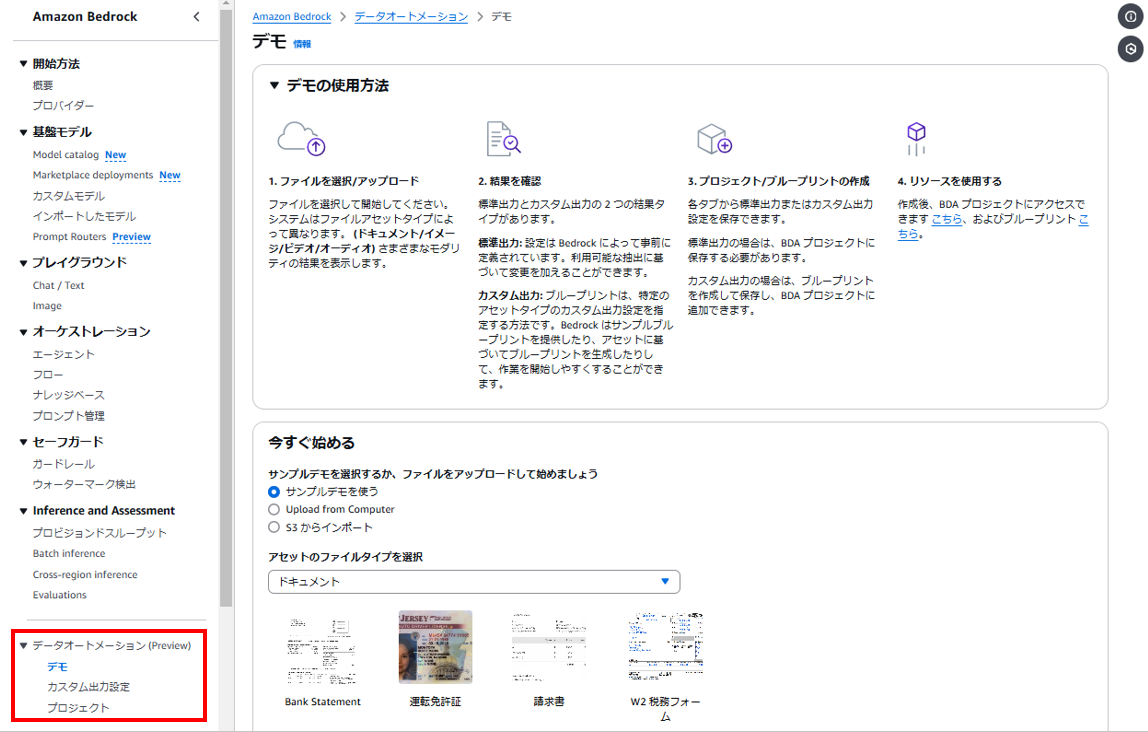
2.ファイルを選択/アップロード
今回は「サンプルデモ」を利用していきます。
フローとしては以下のようになっています。
| No | デモの使用方法 | 使用法詳細 |
|---|---|---|
| 1 | ファイルを選択/アップロード | ファイルを選択して開始 |
| 2 | 結果を確認 | 標準出力とカスタム出力の 2 つの結果タイプがあります。 |
| 3 | プロジェクト/ブループリントの作成 | 各タブから標準出力またはカスタム出力設定を保存できます。 |
| 4 | リソースを使用する | 作成後、BDAプロジェクト(左ペイン)からアクセスできます。 |
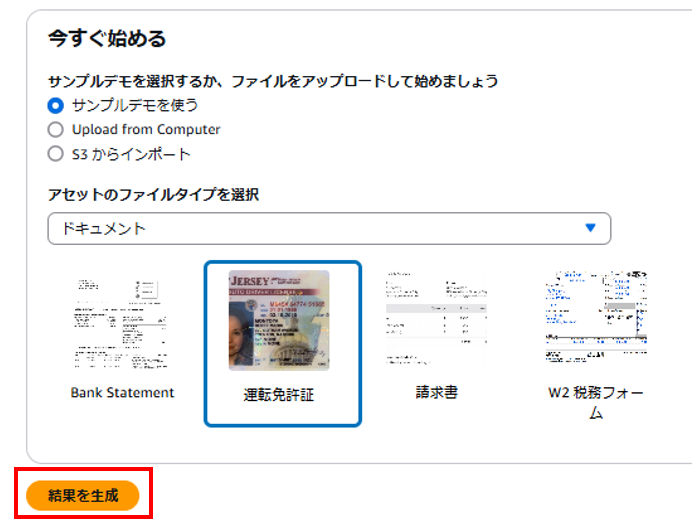
2-1.ファイルを選択して「結果を生成」を押下
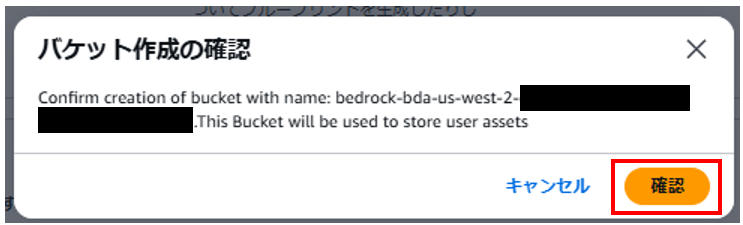
2-2.バケット作成の確認
結果の出力先となるS3バケットの作成を求められるため「確認」を押下
3.結果を確認
■標準出力の場合
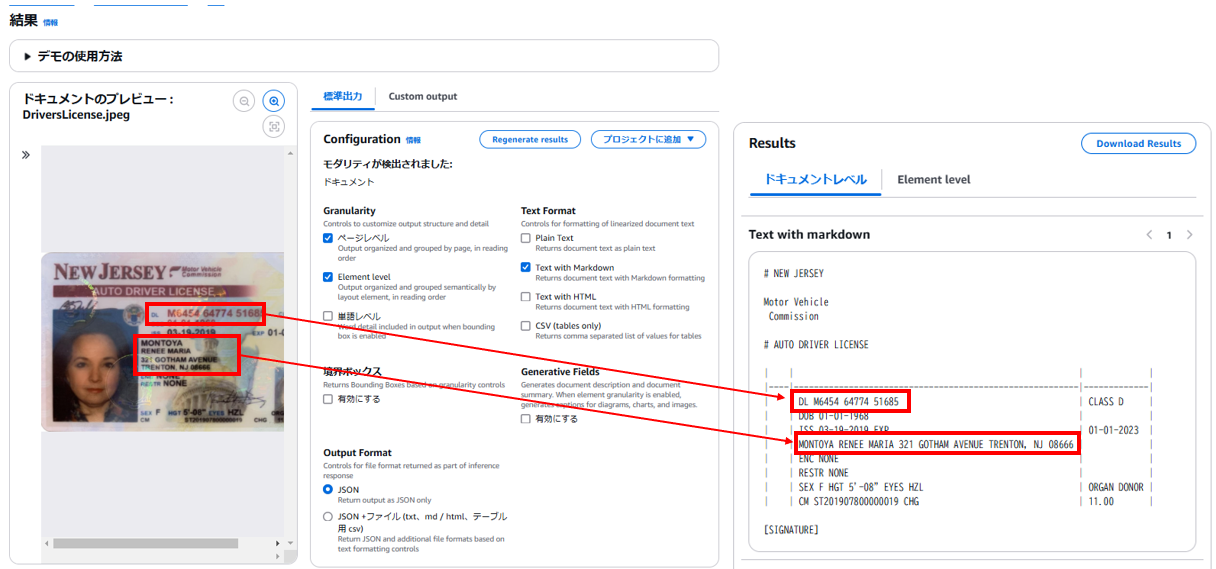
※本来の見え方だと「Results」が画面下部に表示されますが、横並びで表示させています。
■Custom outputの場合
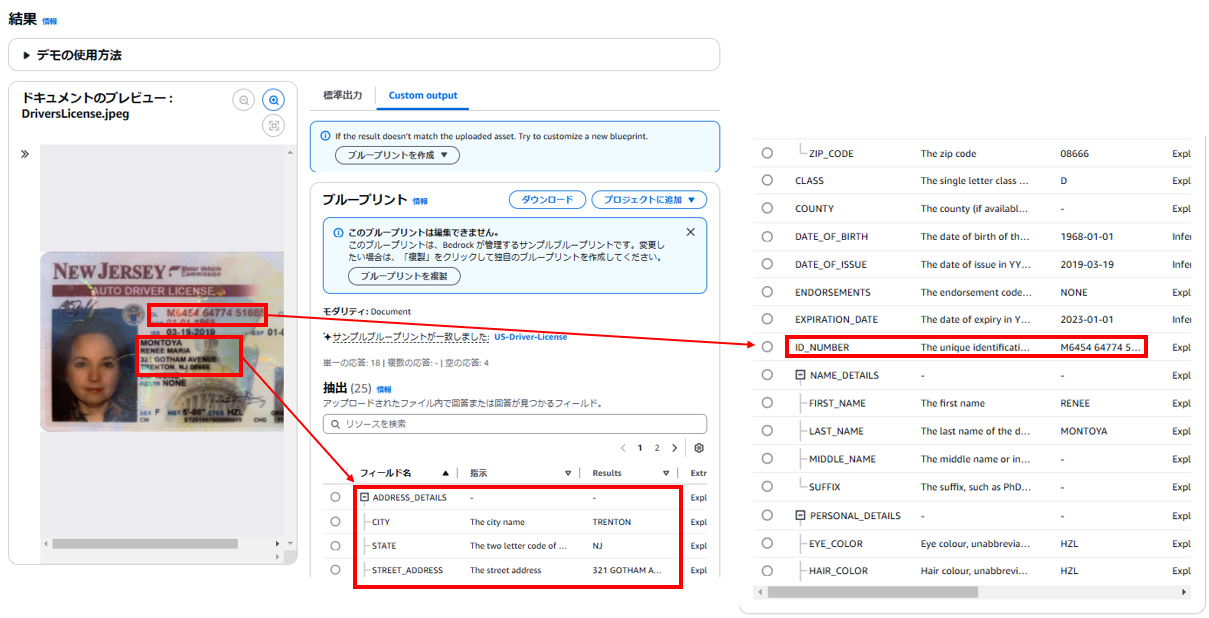
カスタム出力は、データを特定の形式や構造に変換する機能を提供します。このプロセスでは、ブループリントという設定ファイルが活用されます。
ブループリントとは、どのようなデータを抽出し、それをどのように加工・出力するかを指定する「指示書」のようなものです。
今回の場合「US-Driver-License」というブループリントに従い、運転免許証から特定の情報(名前、住所、生年月日など)が抽出されました。
※ブループリントについては「6.ブループリント複製」にて記載
4.ダウンロード
ResultsのDownload Resultsボタンを押下すると、Results.zipというファイルがダウンロードされます。
■標準出力の場合

■Custom outputの場合
5-1.プロジェクトの作成
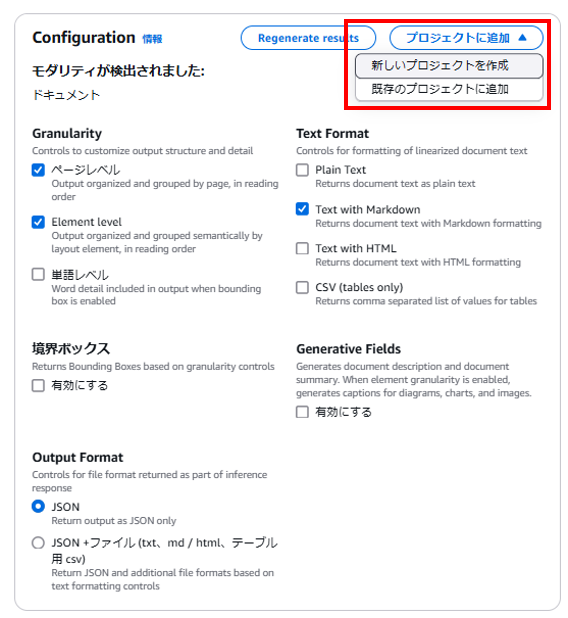
「Configuration」の内容をプロジェクトに保存することが可能です。
右上の「プロジェクトに追加」を押下して「Create a new BDA Project」のポップアップが表示されます。
5-2.新しいプロジェクト作成
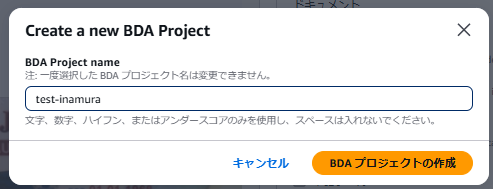
「BDAプロジェクトの作成」を押下すると、左ペイン「データオートメーション」の「プロジェクト」からアクセスすることが可能となります。
6-1.ブループリントの複製
調整したい場合は「ブループリントを複製」を押下して編集をする。
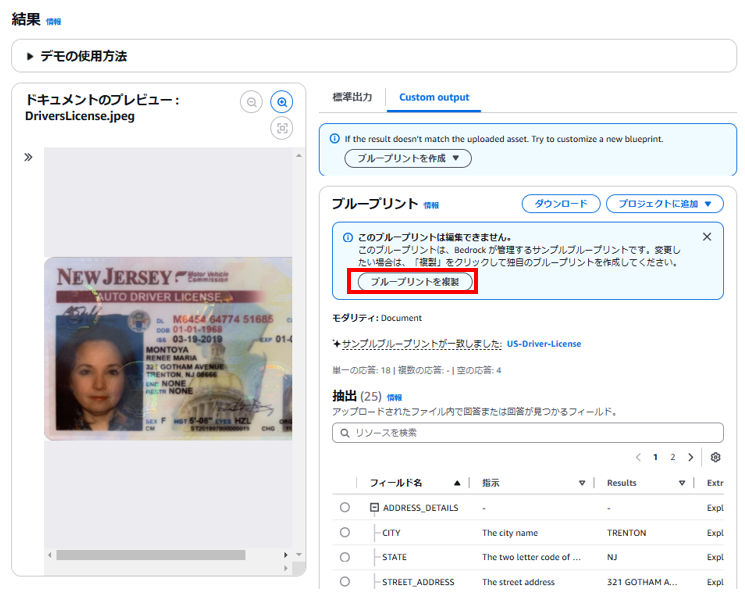
6-2.ブループリント複製を作成
「ブループリントを複製」を押下する。
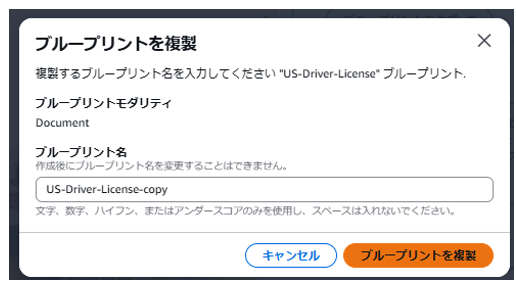
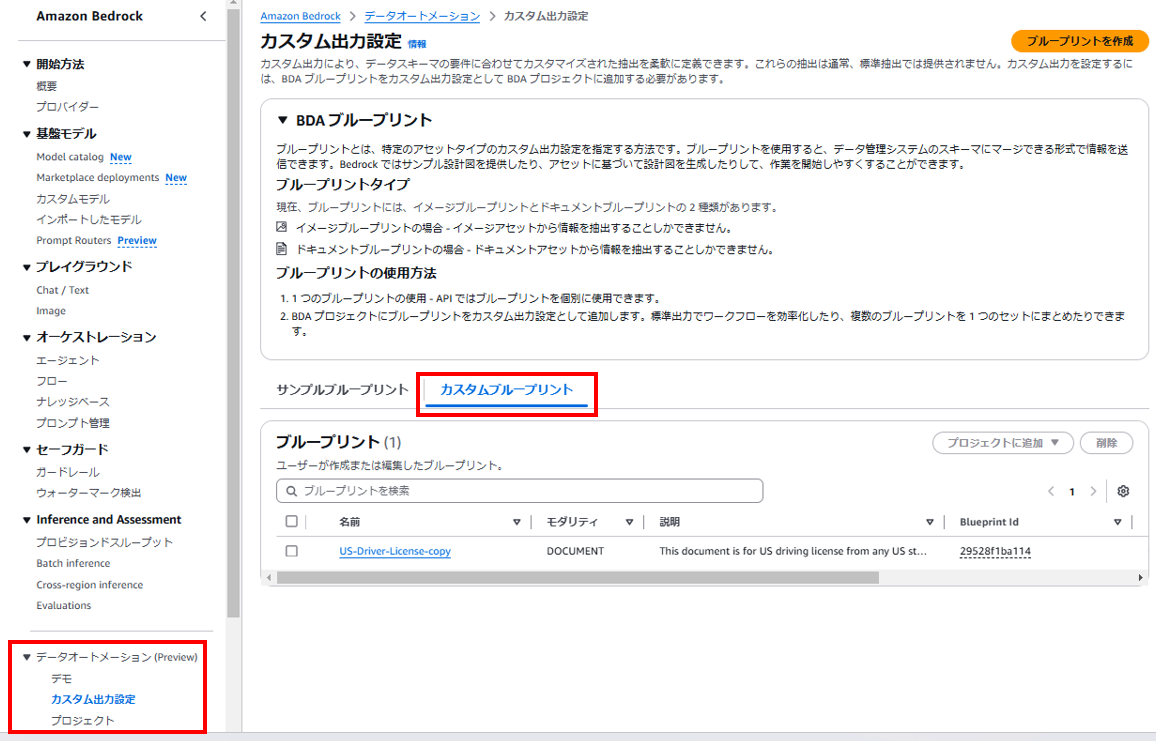
6-3.カスタムブループリントの確認
左ペインの「データオートメーション」の「カスタム出力設定」からアクセス。
タブ「カスタムブループリント」を選択して、「6-2」で作成したブループリントを確認することができる。
まとめ
BDAは非構造化データ処理を大幅に簡略化し、多くのビジネスシーンで活躍が期待できるツールです。
現時点では日本語対応が未実装ですが、将来的に対応が進むことで、日本国内でもさらなる普及が見込まれると思います。
個人的にデータ処理の可能性を広げるツールとして非常に期待しています。
今後の日本語対応が待ち遠しいです。