




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeのデータセット作成時に、以下のエラーがでました。
Failed to create a data import job for item interactions dataset.
Input csv has rows that do not conform to the dataset schema. Please ensure all required data fields are present and that they are of the type specified in the schema.
データセット作成時にスキーマを設定しますが、実際のデータの属性とスキーマが合っていないためにエラーが発生したようです。
今回の記事では、CSVファイルに含まれる各カラムのデータ型を調べる方法を紹介します。
各カラムのデータ型を調べてみる
Amazon Personalizeの各データセットを作成する際に、次のエラーが出ました。
Failed to create a data import job for item interactions dataset.
Input csv has rows that do not conform to the dataset schema. Please ensure all required data fields are present and that they are of the type specified in the schema.
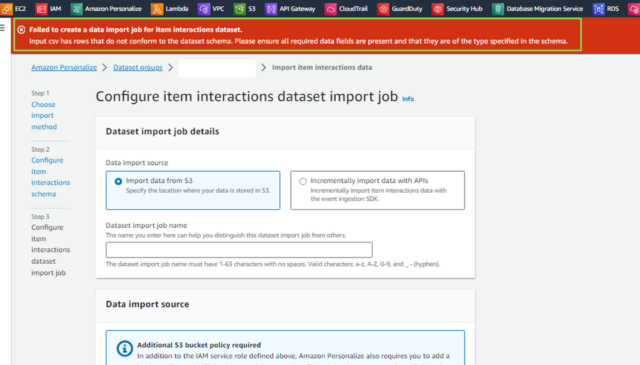
実データとスキーマを比較すると、属性名は合っていました。あとは、データ型が不一致の可能性があります。
AWS公式ドキュメントを確認すると、"Amazon Personalize にインポートするデータ (属性名やデータ型を含む) は、宛先データセットのスキーマと一致する必要があります"と書かれていますので、実データに含まれる各属性のデータ型を調べる必要がありそうです。
■準備
CSVファイルに含まれる各カラムのデータ型を調べる方法はいくつかありますが、今回はPythonのpandasライブラリを使う方法をやってみます。
検証には、以下を利用します。
- データファイル
- Jupyter Notebook
Jupyter Notebookについては、こちらの記事を参照してください。
■データ型を調べてみる
CSVファイルに含まれる各カラムのデータ型を調べてみましょう。
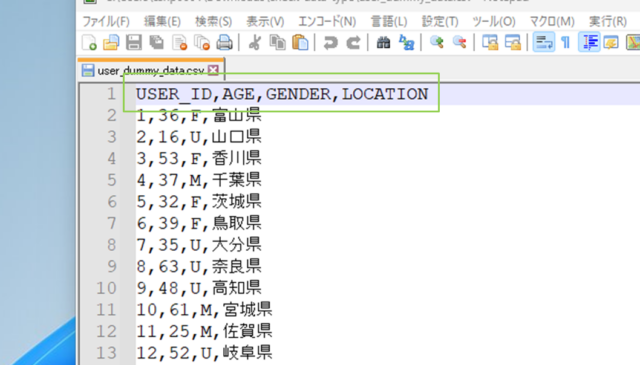
使用するデータは以下の画像の通りです。
USER_ID,AGE,GENDER,LOCATION
↓[Jupyter Notebook]を起動します。
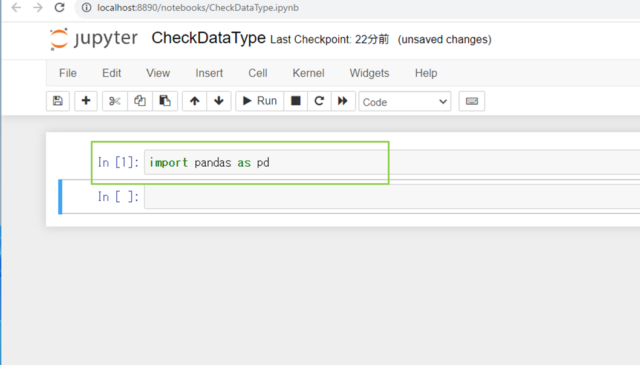
↓[pandas]をインポートします。pandasはデータ分析、データクリーニング、データ探索など、データサイエンスの分野で広く利用されています。
import pandas as pd
↓データ型を調べたいCSVファイルを読み込みます。
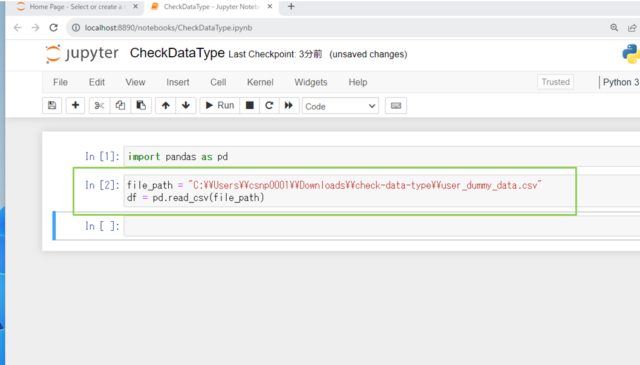
file_path = "C:\\Users\\csnp0001\\Downloads\\check-data-type\\ファイルパス"
df = pd.read_csv(file_path)
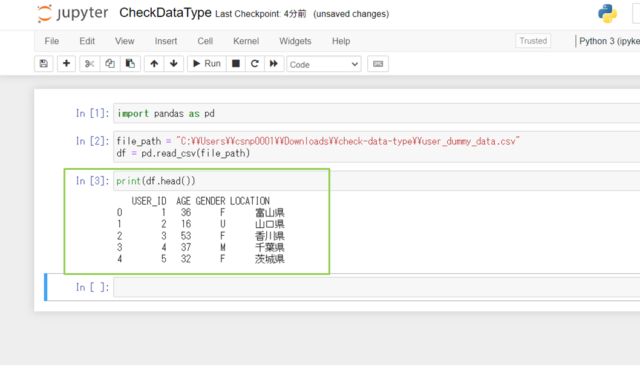
↓取り込めているか、先頭の5行を表示してみます。
print(df.head())
↓それではデータ型を調べてみましょう。基本的な情報(カラム名、非欠損値の数、データ型など)を表示してみます。
print(df.info())
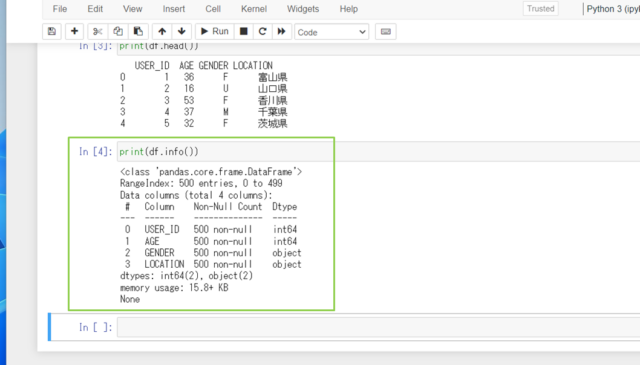
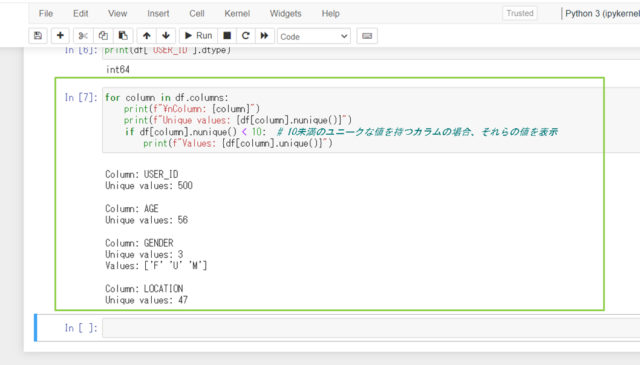
USER_ID,AGEがint、GENDER,LOCATIONがobjectだとわかりましたね。
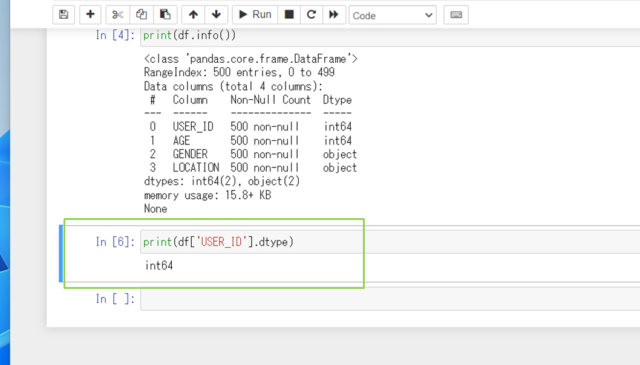
↓個別に調べたいときは、以下のコードを実行します。
print(df['USER_ID'].dtype)
↓どんな値が入っているかも確認できます。
for column in df.columns:
print(f"\nColumn: {column}")
print(f"Unique values: {df[column].nunique()}")
if df[column].nunique() < 10: # 10未満のユニークな値を持つカラムの場合、それらの値を表示
print(f"Values: {df[column].unique()}")
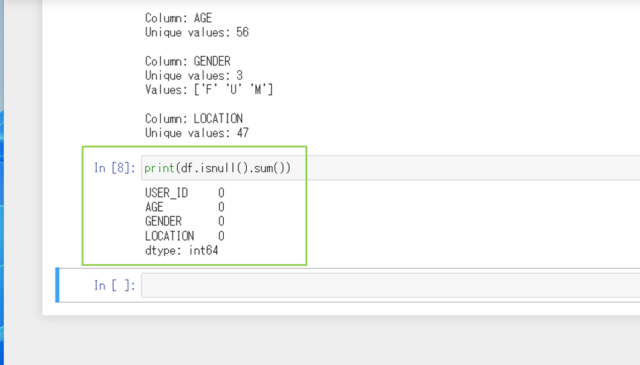
↓欠損値がないかを調べるときは、次のコマンドを実行します。
print(df.isnull().sum())
今回の検証は以上です。
まとめ: Amazon Personalizeのエラーを解決!各カラムのデータ型を調べる方法
Amazon Personalizeは推薦情報を取得できるキャンペーン作成まで、正直すんなりいきません。
とくに学習させるデータをインポートするまではエラーの連続です。今回紹介したデータ型の調査も、地味ですが有用な方法かと思います。ぜひ試してみてください。
参考リンク:AWS公式ドキュメント
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/
■Amazon Personalize学習用ダミーデータをPythonで作ってみた(齊藤弘樹)
https://cloud5.jp/saitou-personalize-create-dammydata/