




わたしは2025年7月4日に開催された「第8回日本Zabbixユーザー会勉強会」に参加しました。
それまでの私は「Zabbix=監視ソフト」という程度の理解しか持っていませんでしたが、勉強会で紹介された多彩なユースケースを見て「これは触ってみたい!」と一気に興味が高まりました。
まずは全体像をつかむため、以下の3つのテーマでハンズオンを進めてきました。
-
検知・通知フローのテスト ←今回
本記事はシリーズの最後となる第3回として、監視対象ホストに異常が起きた際にメールで通知する設定を紹介します。
Zabbixでサーバーを監視してみた
■0. 前提
今回のハンズオンの前提は以下の通りです。第1回、第2回の続きとなります。
- 第1回で構築したZabbixサーバー
- 第2回で構築した監視対象ホスト
- 監視対象ホストがZabbixにホスト登録済み
- Zabbixサーバー用EC2インスタンスにAmazon SES操作権限付与済み
- Zabbixサーバー用セキュリティグループでOutboundルールに587/TCPが許可されていることを確認。
今回のハンズオンでは、Zabbixサーバーからメールを配信するためにメールサーバーが必要になります。
手軽さではGmailのメールサーバー機能を利用するのもアリですが、スケール面からAmazon SESを選択します。
そのため、Zabbixサーバーとして利用しているAmazon EC2インスタンスには、Amazon SESに対しメール送信のAPIを実行する権限が必要です。適宜以下の権限を付与してください。
{
"Version":"2012-10-17",
"Statement":[
{
"Effect":"Allow",
"Action":[
"ses:SendEmail",
"ses:SendRawEmail"
],
"Resource":"*"
}
]
}権限の参照情報は、こちら
■1. Amazon SES設定
まずは、送信用のメールサーバーを用意します。
↓AWSにログインし、SESのダッシュボード画面にアクセスします。
↓
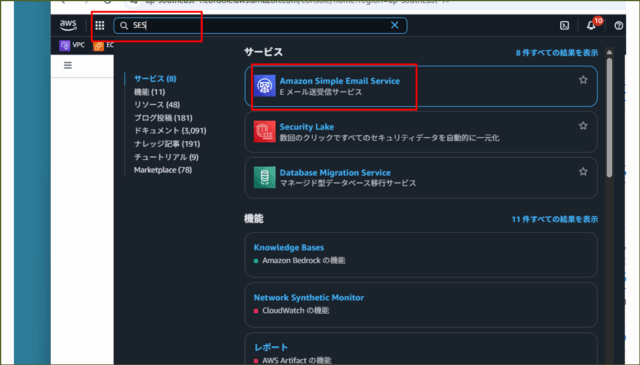
↓左のナビゲーションペインから[ ID ] ⇒ [ ID の作成 ]を押下します。
↓以下の設定値を入力します。
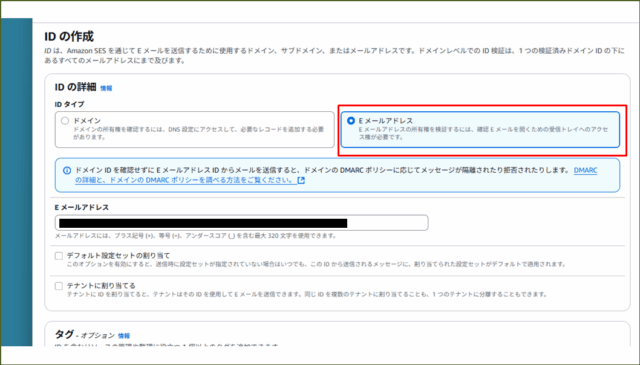
- ID タイプ: E メールアドレス
- Eメールアドレス: <検証に使える自身のメールアドレス>
↓設定したメールアドレスに、検証用メールが届きますので、リンクにアクセスします。
↓
↓検証が完了しましたら、ステータスが変わります。
↓
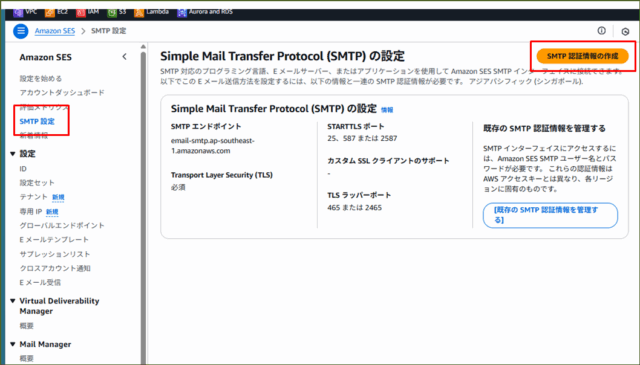
↓続いて、左のナビゲーションペインから[ SMTP 設定 ] ⇒ [ SMTP 認証情報の作成 ]を押下します。
↓
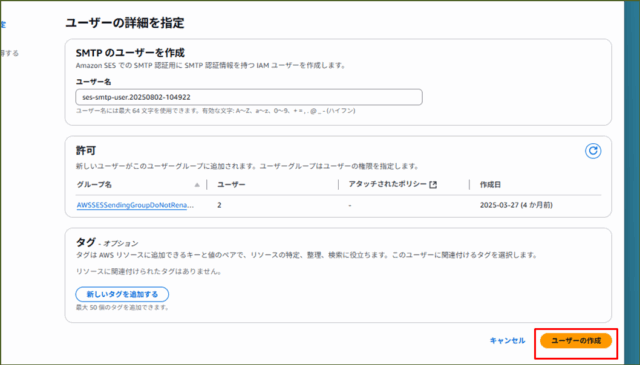
↓自動でIAM ユーザー(SMTP専用)が作成され、SMTP Username/Passwordが発行されます。メモしておきましょう。
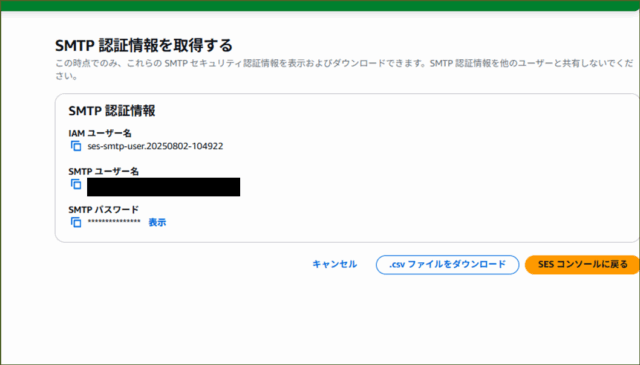
※発行される「Username/Password」は絶対に流出させないよう、取り扱いには注意しましょう。
■2. Zabbix通知設定(メール)
つぎに、Zabbixサーバーで通知設定を行っていきます。 こちらを参考に設定しました。
↓[ Alerts ] ⇒ [ Media Types ]を押下します。
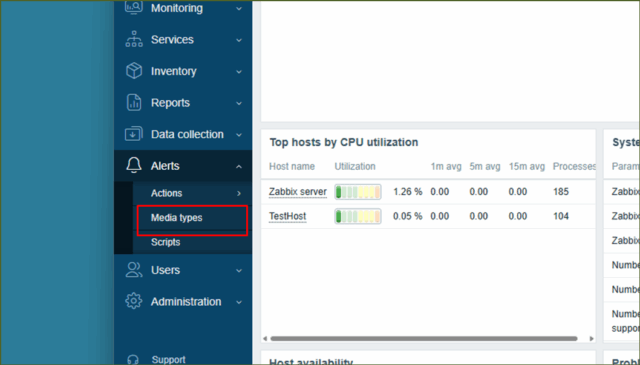
↓サンプルがすでに用意されていて、一覧の中に[ Email ]があるかとおもいますので、押下します。
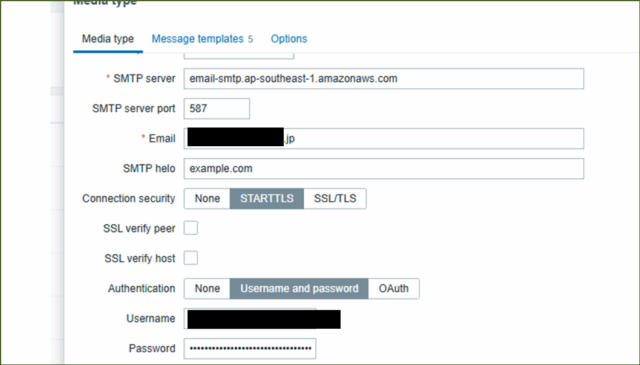
↓以下の設定値を入力し、[ Update ]を押下します。
| 項目 | 設定値 |
|---|---|
| Name | |
| Type | |
| provider Generic SMTP | |
| SMTP server | email-smtp.ap-southeast-1.amazonaws.com |
| SMTP server | port 587 |
| saitou.h@cp-info.co.jp | |
| SMTP helo | example.com |
| Connection security | STARTTLS |
| Authentication | Username and password |
| Username | 任意 |
| Password | 任意 |
| Message format | Plain text |
| Enabled | チェック |
↓[ Users ] ⇒ [Users]を押下します。
↓[ Admin ]を押下します。
↓[ Media ]タブを押下し、[ Add ]を押下します。
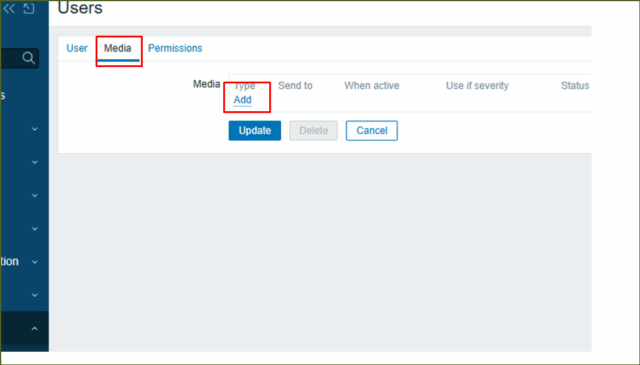
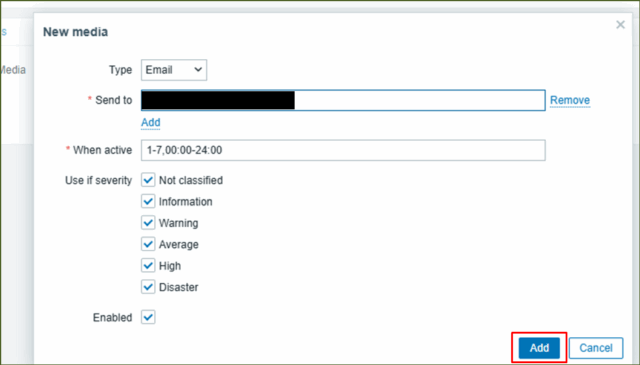
↓[ Send to ]に宛先メールアドレスを入力し、[ Add ]を押下します。“Amazon SESのサンドボックス制限”があるため、送信先メールアドレスは検証済みのアドレスと一致させましょう。
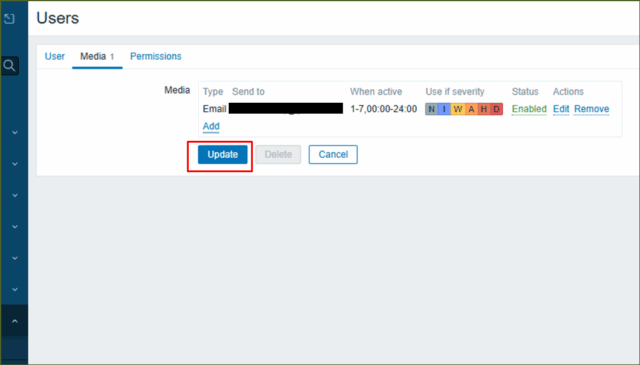
↓[ Update ]を押し、完了です。
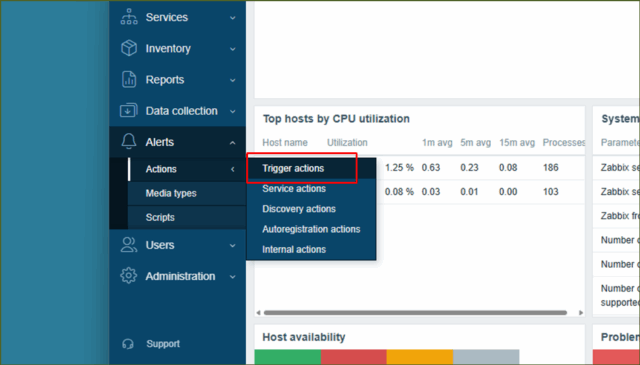
■3.Zabbixアクション有効化
つづいて、トリガーが発報した後のアクションを有効化していきます。デフォルトでは、特に通知などがされません。
↓[ Alerts ] ⇒ [Actions] ⇒ [Trigger actions ]を押下します。
↓一覧に[ Report problems to Zabbix administrators ]がすでにあるかと思いますので、押下します。
↓[ Operations ]タブを押下します。
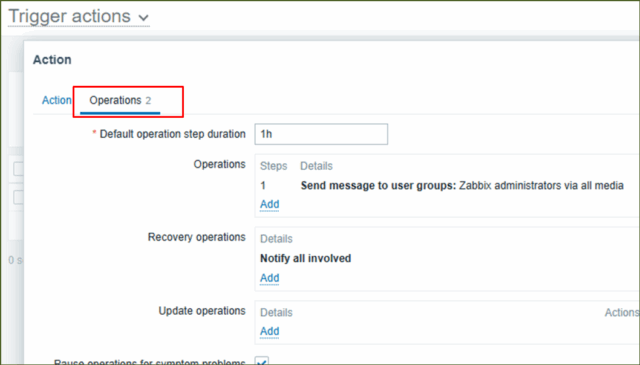
↓デフォルトで問題ないのですが、念のため設定が以下であることを確認します。
- [ Operations ]欄にある[ Steps1 ]の[ Details ]が"Send message to user groups: Zabbix administrators via all media"
- [ Recovery operations ]の[ Details ]が"Notify all involved"
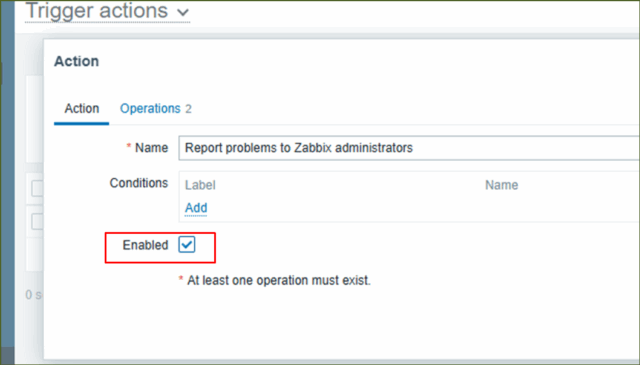
↓設定に問題なければ、[ Action ]タブの[ Enabled ]項目にチェックをいれて、[ Update ]を押下します。
設定は以上です。
■4.トリガー確認
さいごに、トリガーの項目としきい値の確認します。動作確認では、CPU使用率を上昇させてしきい値を超えるように操作します。
ですので、監視対象ホストのアラートのトリガーに、CPU使用率の監視があるか確認しておきます。
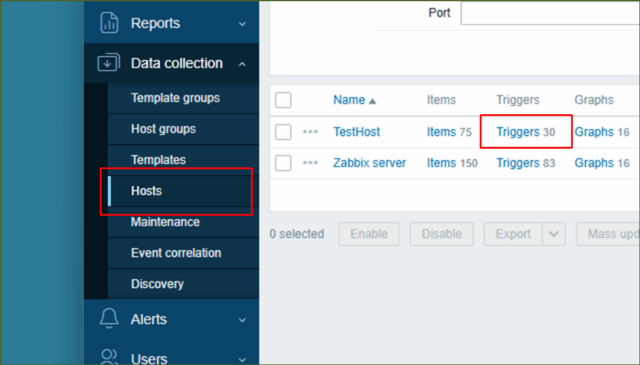
↓[ Data collection ] ⇒ [ Hosts ]を押下し、一覧から「監視対象ホスト」の行の[ Triggers ]を押下します。トリガーはデータの許容レベルの閾値を定義する式を持っていて、受信データが閾値を超えるとトリガーが"発報"するかステータスが’障害’になり、注意が必要なことの発生を通知します。
↓トリガー一覧の中に、[ Linux by Zabbix agent: Linux: High CPU utilization ]があるかと思います。トリガー条件式に"min(/TestHost/system.cpu.util,5m)>{$CPU.UTIL.CRIT}"と書かれていますが、実際の値が書かれていません。
↓実際の値は別の場所に格納されています。[ Data collection ] ⇒ [ Templates ]を押下し、一覧から、[ Linux by Zabbix agent ]を押下します。
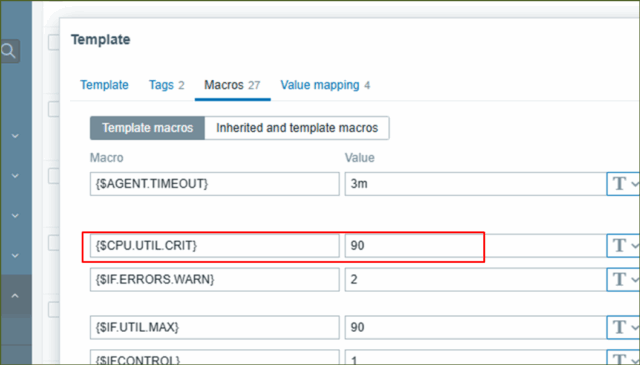
↓[ Macros ]タブを押下すると、さきほどの条件式で使われていた"{$CPU.UTIL.CRIT}"があり、[ Value ]は"90"と入力されていますね。ですので、デフォルトではCPU使用率90%以上になったら、発報するようになっていますね。
さいごの設定確認は以上です。
■5.動作確認
監視で異常があった際に通知されるか動作確認をしていきます。手順としては、監視対象ホストへ負荷をかけて、CPU使用率が高い状態を作り、発報させる流れです。
監視対象ホストにアクセスします。負荷をかけますので、以下のコマンドを実行しましょう。
topコマンドで現在のCPU使用率を確認します。
ubuntu@ip-10-0-1-182:~$ top
top - 07:01:10 up 6:15, 2 users, load average: 0.97, 0.36, 0.13
Tasks: 118 total, 1 running, 117 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni, 99.8 id, 0.2 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7737.0 total, 6520.8 free, 505.5 used, 969.1 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 7231.5 avail Mem
それでは、以下のコマンドで負荷を与えます。
yes > /dev/null &
【実行結果】
root@ip-10-0-1-182:~# yes > /dev/null &
[1] 5543
片方のコアは100%ですね。
ubuntu@ip-10-0-1-182:~$ top
top - 07:42:58 up 6:32, 3 users, load average: 0.96, 2.55, 2.26
Tasks: 124 total, 2 running, 122 sleeping, 0 stopped, 0 zombie
%Cpu0 : 57.3 us, 42.7 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.3 us, 0.3 sy, 0.0 ni, 99.3 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7737.0 total, 6513.3 free, 512.7 used, 969.5 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 7224.3 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5543 root 20 0 6112 1792 1792 R 99.7 0.0 0:15.28 yes
あと1回追加で負荷を与えてみます。
root@ip-10-0-1-182:~# yes > /dev/null &
[2] 5547
【実行結果】
ubuntu@ip-10-0-1-182:~$ top
top - 07:44:58 up 6:59, 3 users, load average: 1.96, 1.11, 1.05
Tasks: 127 total, 3 running, 124 sleeping, 0 stopped, 0 zombie
%Cpu0 : 59.1 us, 40.9 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 55.5 us, 44.5 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7737.0 total, 6511.2 free, 514.4 used, 969.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 7222.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
5543 root 20 0 6112 1664 1664 R 100.0 0.0 3:45.94 yes
5547 root 20 0 6112 1664 1664 R 99.7 0.0 3:40.50 yes
↓ZabbixのWebUIで提供されているグラフは100%に張り付きましたね。
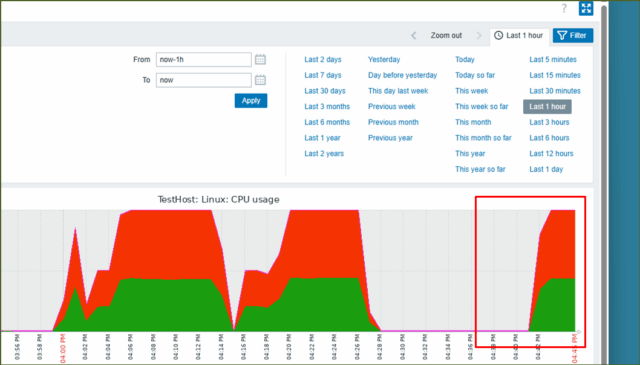
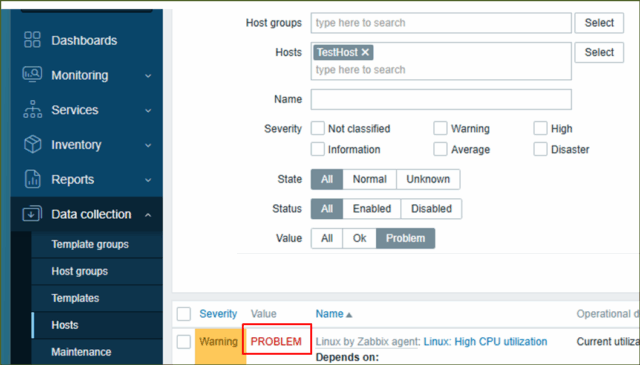
↓監視対象ホストのトリガーを見てみると、"OK"だった値がしきい値を超えたことで"PROBLEM"になっています。
↓そして、メールも届きました。
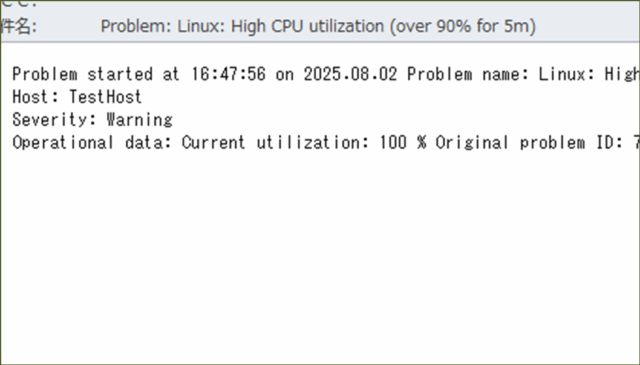
異常を検知し、メールを通知することが確認できました。
復旧時も通知が来るように設定されているので、監視対象ホストで負荷テストを停止してみます。
pkill yes
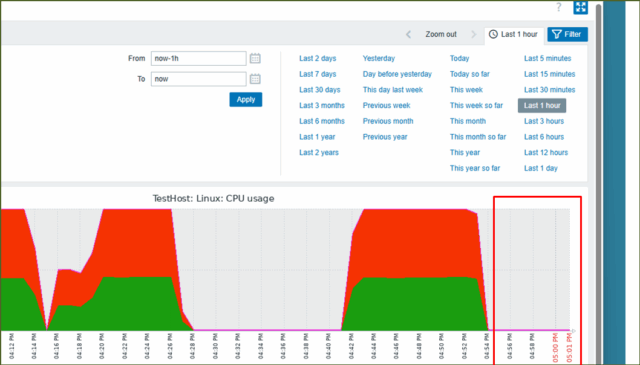
↓サーバ内ではCPUが一気に落ち着きました。
ubuntu@ip-10-0-1-182:~$ top
top - 07:53:18 up 7:07, 4 users, load average: 1.43, 1.71, 1.42
Tasks: 132 total, 1 running, 131 sleeping, 0 stopped, 0 zombie
%Cpu0 : 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu1 : 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 7737.0 total, 6510.3 free, 515.2 used, 970.0 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 7221.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 22680 13760 9536 S 0.0 0.2 0:04.94 systemd
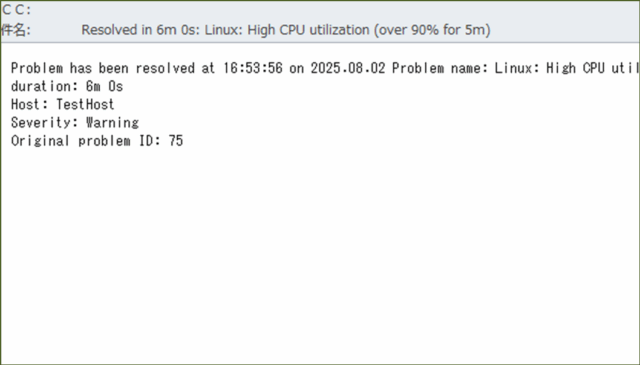
↓少ししたら、グラフに表示された値も落ち着き、復旧したというメールが来ました。
↓
今回のハンズオンは以上です。
まとめ
「Zabbixを触ってみたい」という思いから3回に渡って、いろいろ試してきました。
-
検知・通知フローのテスト ←今回
これでZabbixを用いて監視ができる基本を学ぶことができました。
つぎは監視対象ホストの自動登録や監視項目の詳細を見ていきたいですね。
参考リンク: Zabbix マニュアル
↓ほかの協栄情報メンバーもZabbixについての記事を公開しています。ぜひ参考にしてみてください。
■はじめてのZabbixサーバ構築 #1 サーバ立ち上げ編(齊藤弘樹)
■はじめてのZabbixサーバ構築 #2 監視対象ホスト登録編(齊藤弘樹)
■Zabbixサーバーの構築手順 (Ubuntu22.04/Zabbix6.4)(mochizuki.t)