



はじめに
この記事では、RAGの基本的な仕組みをサンプルコードを用いて解説します。RAGとは、外部のドキュメントから関連情報を検索し、その情報をもとにLLM(大規模言語モデル)が回答を生成する仕組みです。
今回は Google Colab 上で動作するシンプルなRAGを実装しながら、各コードの意味を詳しく説明していきます。
なお本コードは以下Udemyで紹介されていたものを一部カスタマイズしたものになります。
https://www.udemy.com/course/rag-deploy/
目次
- [RAGの仕組み]
- [全体のコード]
- [OpenAIモデルの種類]
- [セクション別解説]
- [この実装の特徴と注意点]
- [よくあるエラーと対処法]
- [まとめ]
- [参考リンク]
RAGの仕組み
本セクションでRAG(Retrieval-Augmented Generation)に関する基本知識(だと思っている)を復習します。
RAGの必要性
今更ですが、LLM(ChatGPTなど)は社内情報といったクローズドな情報を回答できません。
しかしそういった情報を回答してくれるチャットボットの需要は高いかと思います。
RAGはこのようなクローズドな情報を回答可能にする考え方です。
【RAGなしの場合】
ユーザー: 「2023年の第1事業部の売上は?」
LLM: 「申し訳ありませんが、その情報は持っていません」
または「○○億円です」(ハルシネーション=嘘)
【RAGありの場合】
ユーザー: 「2023年の第1事業部の売上は?」
RAG: ① 社内データベースから関連情報を検索
② 「第1事業部売上300億円」という情報を発見
③ この情報をもとにLLMが回答
LLM: 「2023年の第1事業部の売上は300億円です」RAGの3ステップ
RAGは以下の3つのステップで動作します。
ステップ1:検索(Retrieval)
ユーザーの質問から関連情報を検索します
ステップ2:拡張(Augmented)
上記検索結果をプロンプトに追加します。
ステップ2:生成(Generation)
上記の拡張されたプロンプトに基づいて、LLMが回答を生成します。
そのままRAG(Retrieval-Augmented Generation)の頭文字になっているので覚えやすいですね。
ベクトル化と類似度検索の仕組み
本記事で利用するソースコードで「検索」部分では、ベクトル化と類似度検索という技術を使います。
ベクトル化とは?
テキストを数値の配列(ベクトル)に変換することです。
LLMはテキストを理解できず「似ているかどうか」の判断ができません。
"猫が好き" → [0.2, 0.8, -0.1, 0.5, ...]
"犬が好き" → [0.3, 0.7, -0.2, 0.4, ...]
"車が好き" → [0.9, 0.1, 0.6, -0.3, ...]意味が似ているテキストは、似たベクトルになります。
LLMが自然言語を「理解」できるのは、内部でテキストをベクトルに変換しているからです。
類似度検索とは?
ベクトル同士の「近さ」を計算して、似ているものを見つけます。
質問: "猫が好き" → [0.2, 0.8, -0.1, 0.5, ...]
ドキュメント1: "私は猫を飼っています" → [0.25, 0.75, -0.15, 0.45, ...] 類似度: 0.95 ★高い
ドキュメント2: "今日は晴れです" → [0.1, 0.1, 0.9, 0.2, ...] 類似度: 0.20 低い
ドキュメント3: "犬と散歩しました" → [0.35, 0.65, -0.25, 0.35, ...] 類似度: 0.85 中程度コサイン類似度
ベクトルの「近さ」を測る方法の1つがコサイン類似度です。
本コードでは実際に計算をしています。
- 1に近い → 非常に似ている
- 0に近い → 関連性が低い
- -1に近い → 正反対の意味
全体のコード
こちら全体のコードとなります。
あくまで仕組みを理解することに特化したものとなります。
from openai
import OpenAI
import numpy as np
import os
from sklearn.metrics.pairwise import cosine_similarity
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("openai-api-key")
client = OpenAI()
def vectorize_text(text):
response = client.embeddings.create(
input = text,
model = "text-embedding-3-small"
)
return response.data[0].embedding
question = "2023年の第1事業部の売上はどのくらい?"
documents = [
"2023年上期売上200億円、下期売上300億円",
"2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円",
"2024年は全社で1000億円の売上を目指す"
]
vectors = [vectorize_text(doc) for doc in documents]
question_vector = vectorize_text(question)
max_similarity = 0
most_similar_index = 0
for index, vector in enumerate(vectors):
similarity = cosine_similarity([question_vector], [vector])[0][0]
print(documents[index], ":", similarity)
if similarity > max_similarity:
max_similarity = similarity
most_similar_index = index
print(documents[most_similar_index])
prompt = f'''以下の質問に以下の情報をベースにして答えて下さい。
[ユーザーの質問]
{question}
[情報]
{documents[most_similar_index]}
'''
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=200
)
print(response.choices[0].message.content)出力例
2023年の第1事業部の売上は300億円です。OpenAIモデルの種類
RAGを実装する前に、OpenAIのモデルの種類を理解しておくことが重要です。モデルによって用途が異なり、間違ったモデルを使うとエラーになります。
モデル一覧は以下で網羅されています。
https://platform.openai.com/docs/models
| 今回は以下のモデルを使用しています。 | カテゴリ | 役割 | 入力 → 出力 |
|---|---|---|---|
| 埋め込みモデル | テキストをベクトル化 | テキスト → 数値の配列 | |
| 生成用モデル | 新しいテキストを生成 | テキスト → 新しいテキスト |
なお、各モデルの「Endpoints」からソースコードで使用しているメソッドに対応しているかどうか判断できます。
以下は今回埋め込みで使用している「text-embedding-3-small」の記載例です。
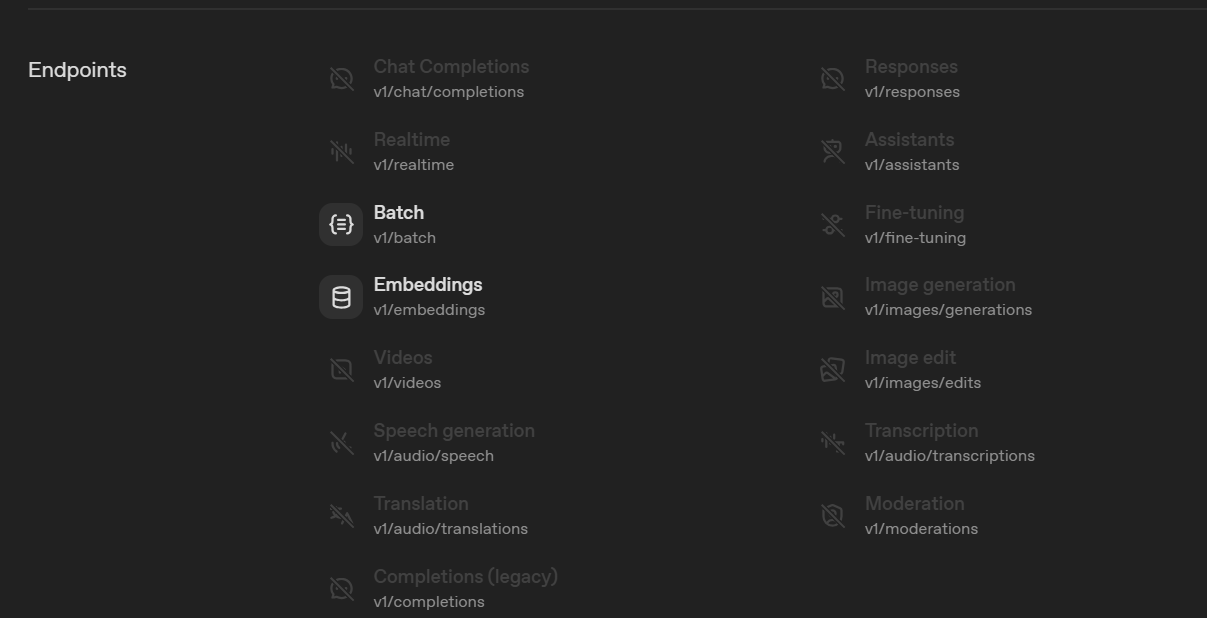

推論モデル使用時の注意点
推論モデル(gpt-5-nanoなど)を使う場合、トークンの一部が「思考」に使われますので、
トークンを節約したい場合は注意が必要です。
ちなみに、本コードでgpt-5-nanoを使用すると本来自然言語で回答がかえってくる部分「content」が空になります。
# ❌ これだと回答が空になることがある
response = client.chat.completions.create(
model="gpt-5-nano-2025-08-07",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=200 # 思考だけで使い切ってしまう
)
# content='' になる可能性あり
# ✅ トークン数を増やすか、通常のモデルを使う
response = client.chat.completions.create(
model="gpt-4o-mini", # 推論なしのモデル
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=200
)セクション別解説
以降でソースコードを解説していきます。
1. ライブラリのインポートと初期設定
from openai import OpenAI
import numpy as np
import os
from sklearn.metrics.pairwise import cosine_similarity
from google.colab import userdata
os.environ["OPENAI_API_KEY"] = userdata.get("openai-api-key")
client = OpenAI()| ライブラリ | 用途 |
|---|---|
openai |
OpenAI APIを使用するためのSDK |
numpy |
数値計算ライブラリ(OpenAI SDKの内部処理で使用) |
sklearn.metrics.pairwise |
コサイン類似度の計算 |
google.colab.userdata |
Colabのシークレット機能からAPIキーを取得 |
2. テキストのベクトル化関数の準備
def vectorize_text(text):
response = client.embeddings.create(
input = text,
model = "text-embedding-3-small"
)
return response.data[0].embeddingこの関数は、テキストをベクトル(数値の配列)に変換します。
使用するモデルは埋め込みモデルの一つである「text-embedding-3-small」を利用します。
コードを普段書かない私は最近知ったのですが、VS Codeでメソッドにカーソルを合わせて、「Cntr+Shift」でそのメソッドのソースコードに飛べるんですね。引数などを知りたい方はローカルにOpenAIをインストールしてVS codeから調べてみてください。
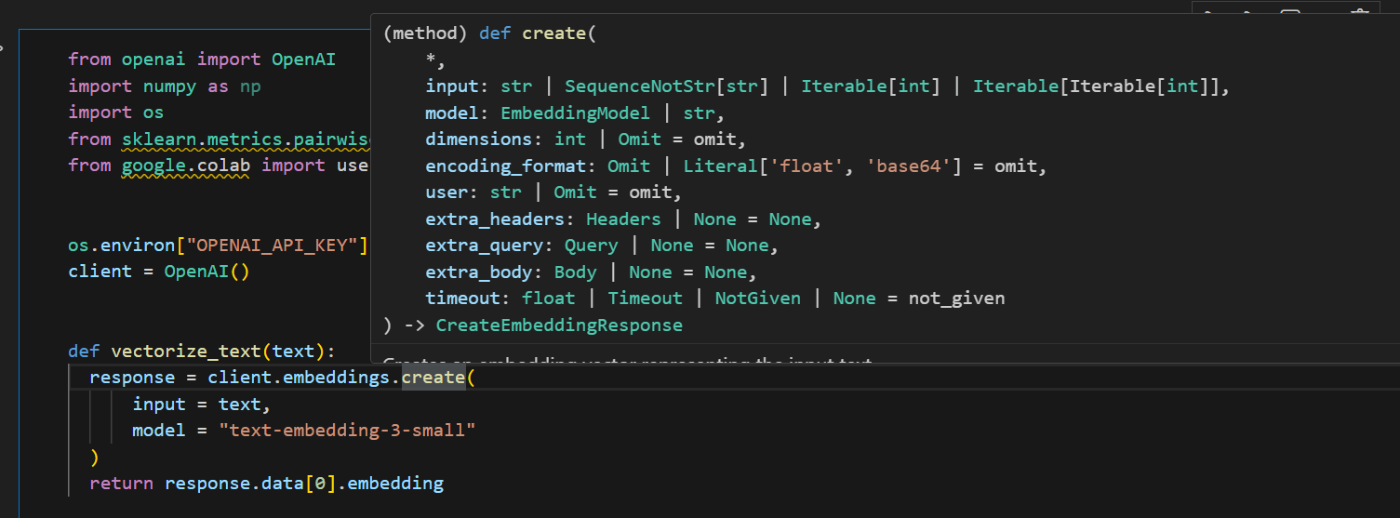

response.data[0].embeddingで、実際のベクトル(浮動小数点数のリスト)を取得しています。
注意:
gpt-4oやgpt-5などのチャットモデルはembeddings.create()では使用できません。必ず埋め込み専用モデル(text-embedding-3-smallなど)を指定してください。
試しに直接「text」に文字列を渡してベクトル化してみます。
text = "こんにちは"
print(vectorize_text(text))
def vectorize_text(text):
response = client.embeddings.create(
input = text,
model = "text-embedding-3-small"
)
return response.data[0].embedding出力
しっかりとベクトル化されていますね。
[0.01923767849802971, -0.009727869182825089, 0.0033011757768690586, 0.03210317716002464,
#以下省略3. 質問とドキュメントの定義
question = "2023年の第1事業部の売上はどのくらい?"
documents = [
"2023年上期売上200億円、下期売上300億円",
"2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円",
"2024年は全社で1000億円の売上を目指す"
]question: ユーザーからの質問documents: 検索対象となるドキュメント群
今回はシンプルに3つのドキュメントをPythonのリストとして定義しています。
4. ベクトル化の実行
vectors = [vectorize_text(doc) for doc in documents]
question_vector = vectorize_text(question)リスト内包表記を使って、すべてのドキュメントと質問をベクトル化しています。
# 上記は以下と同じ意味
vectors = []
for doc in documents:
vectors.append(vectorize_text(doc))5. 類似度検索
以下のような流れで類似検索および結果を表示しています。
①ベクトル化されたドキュメントに対してインデックスを割り振る
②cosine_similarityを用いて二つのベクトル(質問とドキュメント)を比較する
③上記の結果、質問と最もベクトルが近いドキュメントを表示する
max_similarity = 0
most_similar_index = 0
for index, vector in enumerate(vectors):
similarity = cosine_similarity([question_vector], [vector])[0][0]
print(documents[index], ":", similarity)
if similarity > max_similarity:
max_similarity = similarity
most_similar_index = index
print(documents[most_similar_index])出力例
2023年上期売上200億円、下期売上300億円 : 0.6030701786684198
2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円 : 0.8517503924012055
2024年は全社で1000億円の売上を目指す : 0.6196779986448152
2023年第1事業部売上300億円、第2事業部売上150億円、第3事業部売上50億円補足①
enumerate()はインデックス(番号)と要素を同時に取得できる関数です。
vectors = ["ベクトルA", "ベクトルB", "ベクトルC"]
for index, vector in enumerate(vectors):
print(index, vector)
# 出力:
# 0 ベクトルA
# 1 ベクトルB
# 2 ベクトルC補足②
cosine_similarity()は2次元配列(行列)を期待しています。
question_vector = [0.1, 0.2, 0.3] # 1次元配列
[question_vector] = [[0.1, 0.2, 0.3]] # 2次元配列([]で囲む)複数のベクトルを一度に比較できるよう設計されているため、1つのベクトルでも[]で囲んで2次元配列にする必要があります。
また返り値も二次元配列であるためcosine_similarity([question_vector], [vector])[0][0]で類似度の結果を取得します。
6. プロンプトの作成と回答生成
以下プロンプトです。
chat.completions.create()については以下の公式APIリファレンスに詳細な記載があります。
https://platform.openai.com/docs/api-reference/chat/create
prompt = f'''以下の質問に以下の情報をベースにして答えて下さい。
[ユーザーの質問]
{question}
[情報]
{documents[most_similar_index]}
'''
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_completion_tokens=200
)
print(response.choices[0].message.content)検索で見つかった最も関連性の高いドキュメントをプロンプトに含め、LLMに回答を生成させます。
これがRAGの「Augmented(拡張された)」部分です。LLMが持っていない情報を外部から補完しています。
この実装の特徴と注意点
ベクトルDBは使用していない
今回のコードでは、ベクトルをPythonのリストに保存しています。
| 項目 | 今回のコード | ベクトルDB使用時 |
|---|---|---|
| ドキュメント数 | 少量向け | 大量データ対応 |
| ベクトルの保存 | メモリ上 | 永続化される |
| 毎回ベクトル化 | 必要(API料金発生) | 不要 |
| 検索速度 | 全件ループ | 高速 |
本番環境では、Pinecone、Chroma、FAISS などのベクトルDBを使用することが一般的です。
よくあるエラーと対処法
1. PermissionDeniedError: 埋め込みモデルの指定ミス
PermissionDeniedError: You are not allowed to generate embeddings from this model原因: チャットモデル(gpt-4oなど)をembeddings.create()で指定している
対処: 埋め込み専用モデル(text-embedding-3-smallなど)を使用する
2. PermissionDeniedError: 生成APIでのモデル指定ミス
PermissionDeniedError: You are not allowed to sample from this model原因: 埋め込みモデル(text-embedding-3-smallなど)をchat.completions.create()で指定している
対処: 生成用モデル(gpt-4o-miniなど)を使用する
3. 推論モデルで回答が空になる
content=''
finish_reason='length'
reasoning_tokens=200原因: 推論モデル(gpt-5-nanoなど)でmax_completion_tokensが小さすぎる。思考にトークンを使い切ってしまった
対処:
max_completion_tokensを増やす(1000以上)- または通常のモデル(
gpt-4o-miniなど)を使用する
まとめ
この記事では、RAGの基本的な実装を通じて以下を学びました。
- RAGの仕組み: 検索→拡張→生成の3ステップ
- OpenAIモデルの種類: 埋め込みモデル、生成用モデル、推論モデルの違い
- テキストのベクトル化: OpenAIの埋め込みモデルでテキストを数値ベクトルに変換
- 類似度検索: コサイン類似度で質問に最も関連するドキュメントを検索
- 回答生成: 検索結果をコンテキストとしてLLMに渡し、回答を生成
私の場合、実際の現場ではAWSのマネージドサービスなどを使って構築することになると思いますが、それでもRAGの基本的な仕組みを学習することができてよかったかと思います。