



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
AWS Systems Manager(SSM) インベントリ はマネージドインスタンスからメタデータを収集して、情報表示する機能です。 OSやアプリケーション、ネットワーク設定などの情報を収集してくれます。
今回はインベントリを使った「定期的にEC2のインベントリ情報帳票を作成する」 の方法を紹介します。
1.前提
SSMを使うためには、当該リソースを「マネージドインスタンス」(SSMで管理されたインスタンスのこと)にする必要があります。マネージドインスタンスにするためには、以下の 3 点が必要です。
-
インスタンスに SSM Agent が導入されていること
SSM Agent の導入については今回は手順については触れません。
詳しくはドキュメント↓を参照してください。
SSM エージェント の使用 -
インスタンスから SSM API へのネットワーク経路が確保されていること
以下2パターンのどちらかで、SSM Agentからのアウトバウンド経路を確保する:
・インターネット経由
・VPCエンドポイント経由 -
インスタンスに適切な IAM Role が付与されていること
IAM Roleにアタッチが必要なIAM Policy:AmazonSSMManagerInstanceCore
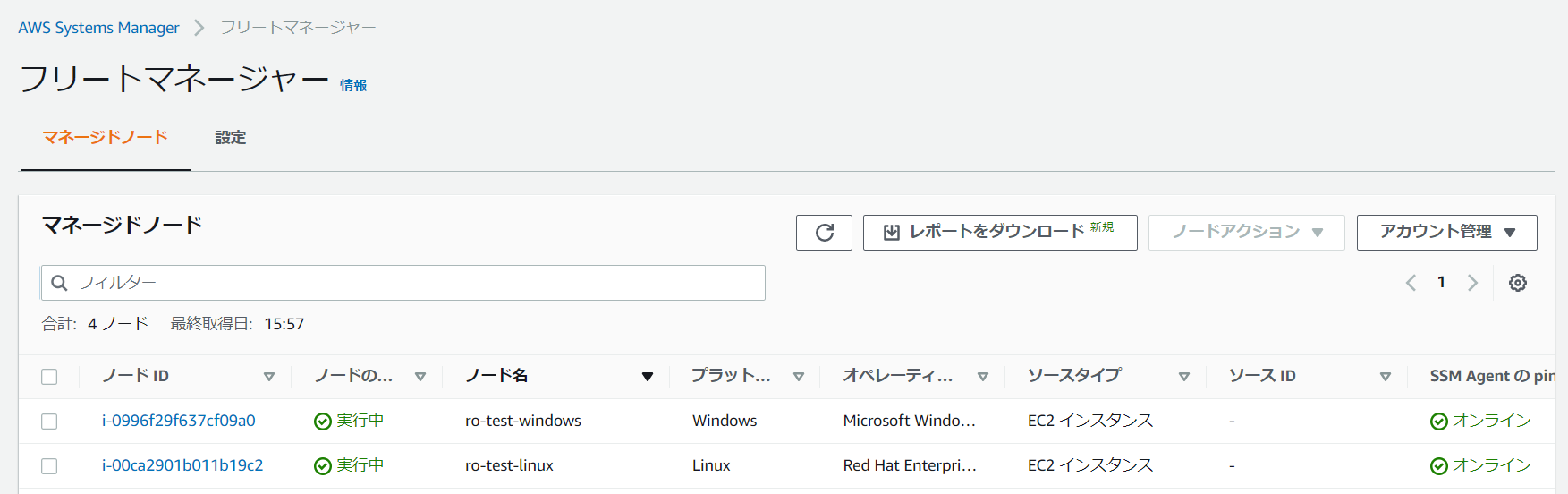
※設定完了すれば、対象インスタンスがマネージドノードとして表示されていることを確認できる。

2.構成
今回作成する構成は以下の通りです。
(マルチアカウント構成の場合は、全てのアカウントのインベントリデータを特定アカウントのS3バケットへ集約することで一元管理をすることも可能です。)
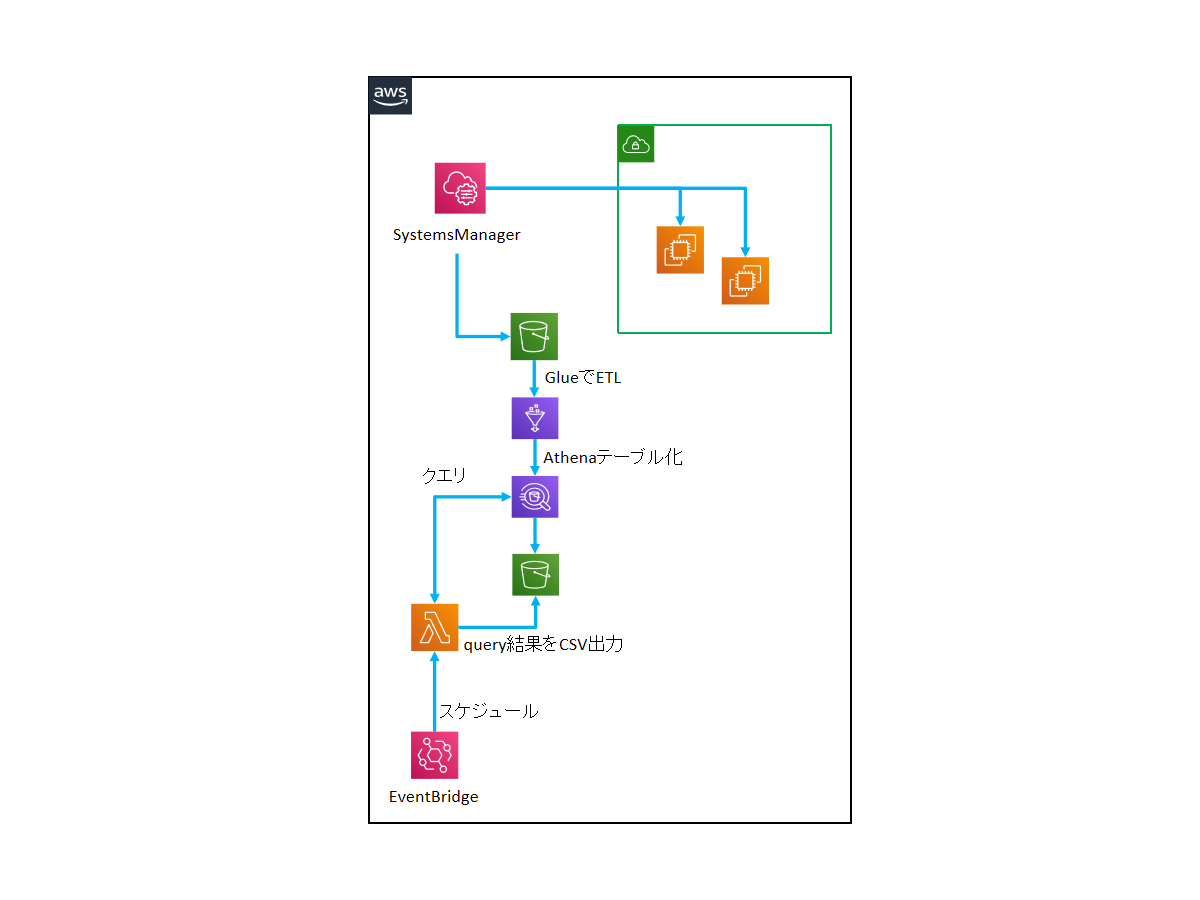

- EC2のインベントリ情報はSystems Managerを経由してS3に収集される。
- 収集されたインベントリ情報データを抽出し、検索しやすい形にデータ変換を行う。
- 定期的にインベントリ情報帳票を作成するLambda関数を実行し、生成したインベントリ情報帳票をS3に保管する
ちなみに「はじめに」の説明では"メタデータの取得”とありましたが、実際にどのようなデータがメタデータとして取得できるのでしょうか。
主な取得可能情報は以下の通り:
以下以外にも、個別に取得設定(カスタムインベントリ)することが可能。
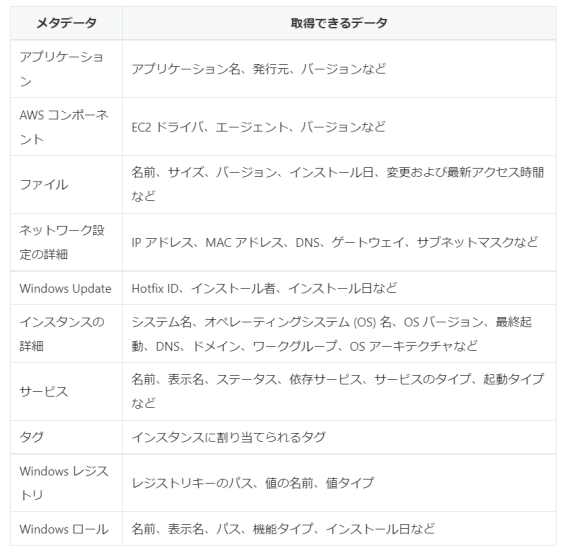

(詳細はAWSサイトを参照)
3.インベントリセットアップ
ここからは実際に設定を行っていきます。
まず、インベントリセットアップを行います。
-
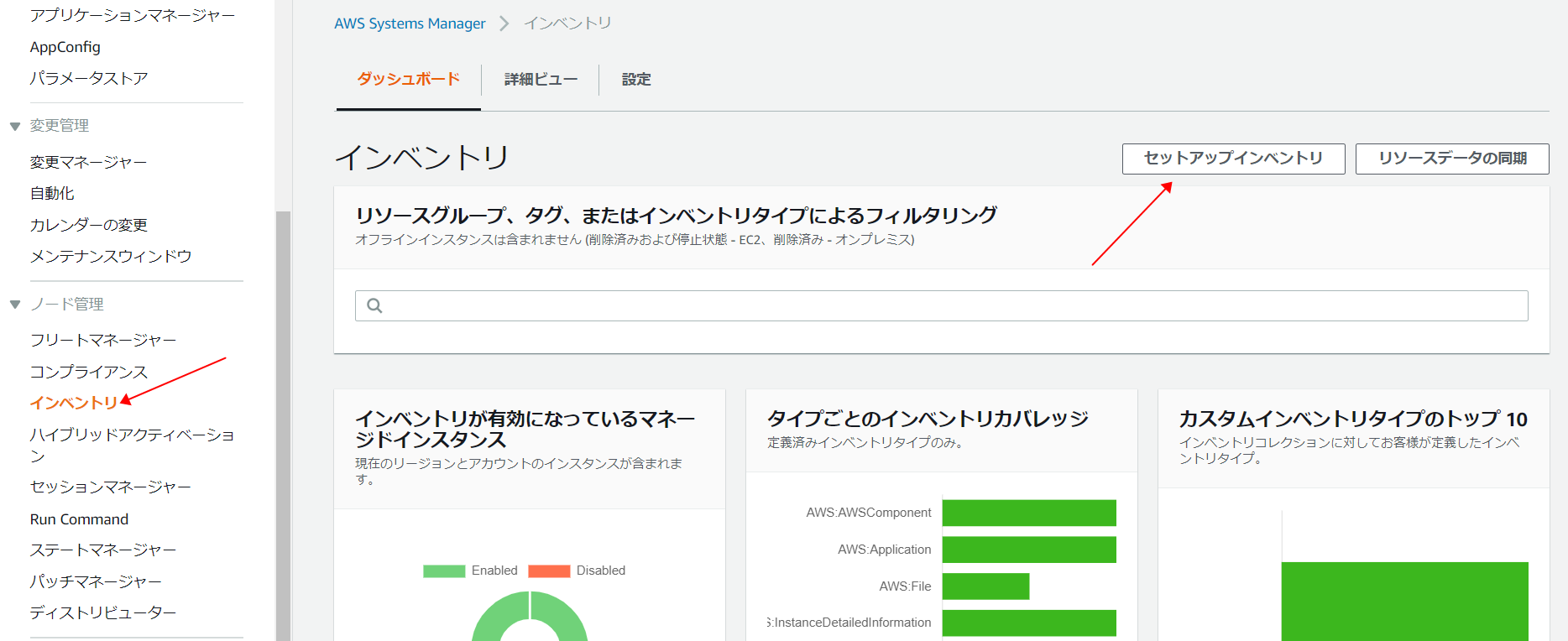
サービスの検索で、SSMと入力して、「System Manager」を選択します。左のメニューから「インベントリ」を選択します。ページが開いたら、「セットアップインベントリ」をクリックします。
-
入力画面が出てきます。 以下の通り入力してみてください。
名前:
任意の名前を指定できます。
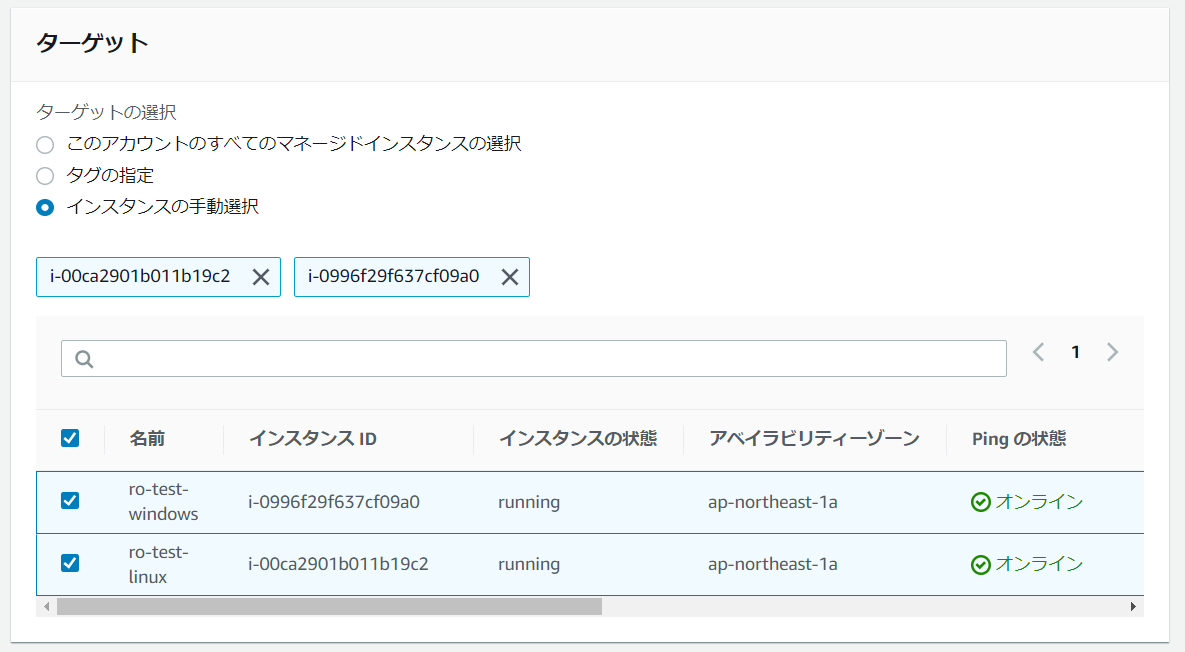
ターゲット:
「インスタンスの手動選択」を選択します。
スケジュール:
30分に指定します。

パラメータ:
デフォルトのままにします。
詳細設定:
今回はS3に書き込まないので、チェックは外しておきます。
さいごに
右下のセットアップインベントリボタンをクリックします。

-
画面が遷移して作成されていることが確認できました。







4.リソースデータ同期
次はインベントリ情報をS3へ格納するために同期設定を行います。
SSM リソースデータ同期を利用して、Inventoryの情報をS3に適宜出力します。
4.1.バケットポリシーの変更
まずはインベントリ情報を書き込めるようバケットポリシーを設定します。
-
対象バケットをクリックし、バケットの詳細画面を開きます。その後、上部の「アクセス許可」ボタンを押し、バケットポリシー「編集」ボタンを押します。
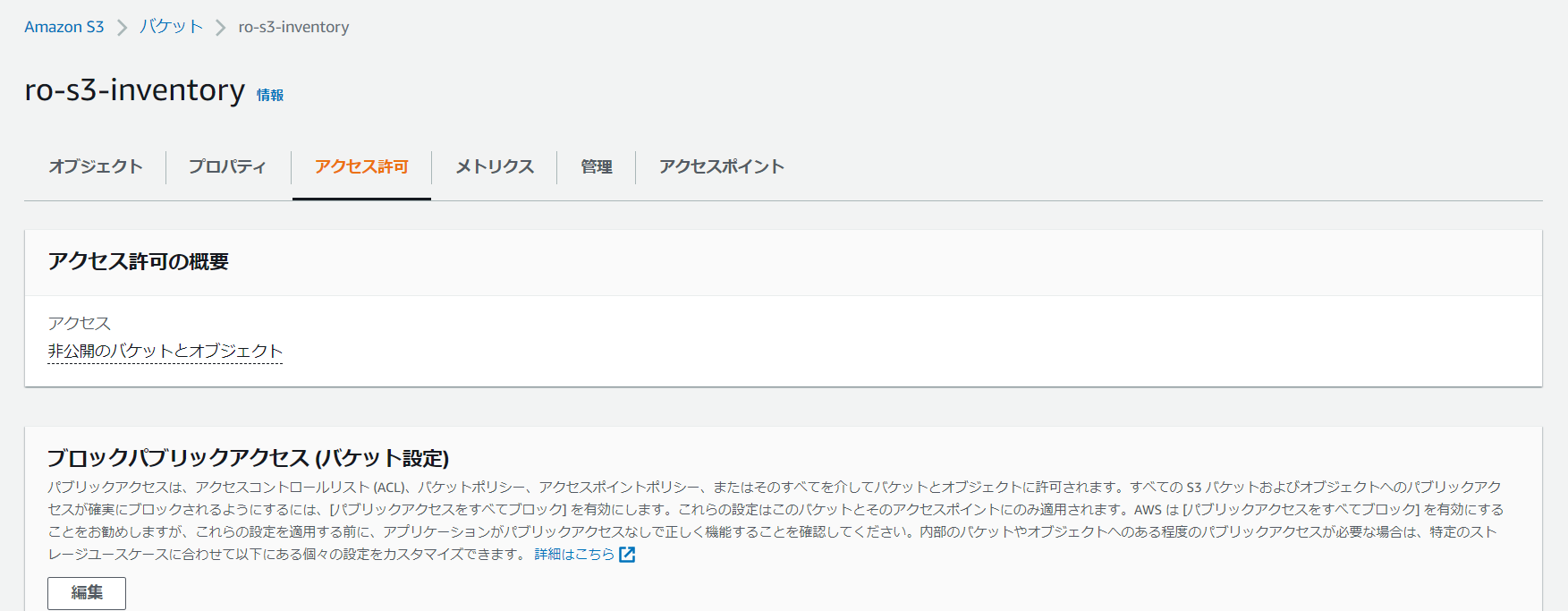
-
「ポリシー」に表示されている文字列(JSONドキュメントといいます)をすべて選択して削除し、以下の内容をコピーして貼り付けます。(まだ保存しません)
{ "Version": "2012-10-17", "Statement": [ { "Sid": "SSMBucketPermissionsCheck", "Effect": "Allow", "Principal": { "Service": "ssm.amazonaws.com" }, "Action": "s3:GetBucketAcl", "Resource": "arn:aws:s3:::YOUR_BUCKET_NAME" }, { "Sid": " SSMBucketDelivery", "Effect": "Allow", "Principal": { "Service": "ssm.amazonaws.com" }, "Action": "s3:PutObject", "Resource": "arn:aws:s3:::YOUR_BUCKET_NAME/*/accountid=YOUR_ACCOUNT_ID/*", "Condition": { "StringEquals": { "s3:x-amz-acl": "bucket-owner-full-control" } } } ] }こちらのページのバケットポリシー例をJSONをエディタ内に記述していきます。
上記のjson内の
"Resource":"arn:aws:s3:::YOUR_BUCKET_NAME"
や
"arn:aws:s3:::YOUR_BUCKET_NAME//accountid=YOUR_ACCOUNT_ID/"
はbacket-nameやアカウントIDを変更する必要があります。 -
Jsonの内容を修正できたら、右上の保存ボタンを選択します。


以上でバケットポリシーの変更は完了です。
4.2.SSMのリソースデータの同期設定
次はインベントリ情報をS3へ格納するために同期設定を行います。
-
インベントリの画面が開いて、右上の「リソースデータの同期」ボタンをおします。
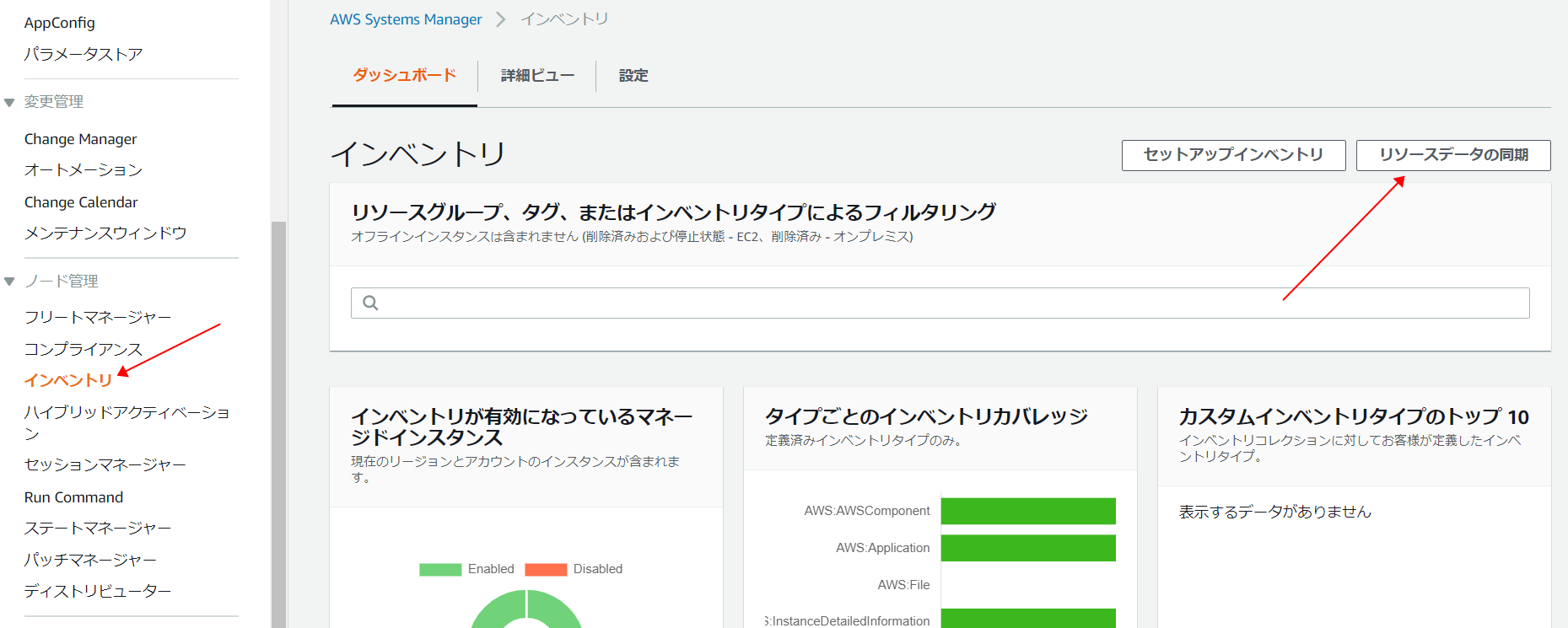
-
リソースデータの同期の一覧画面が開いたら、右上の「リソースデータの同期の作成」をクリックします。

-
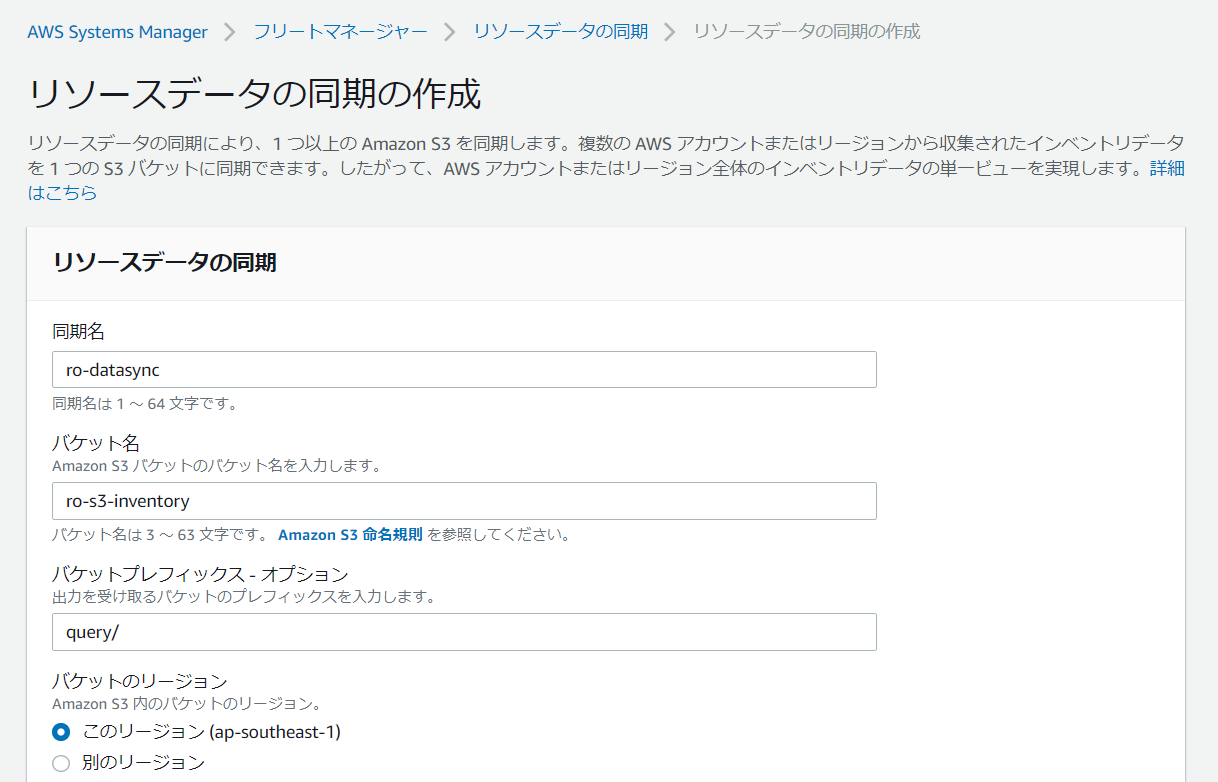
入力画面が出てきます。以下の通り入力してみてください。
同期名:
好きな名前をつける事ができます。
バケット名:
S3のバケット名を設定します。
バケットプレフィックス:
S3のバケットのプレフィックスを設定します。
(入力しなくてもいい)
バケットのリージョン:
バケットのリージョンを選択します。
さいごに
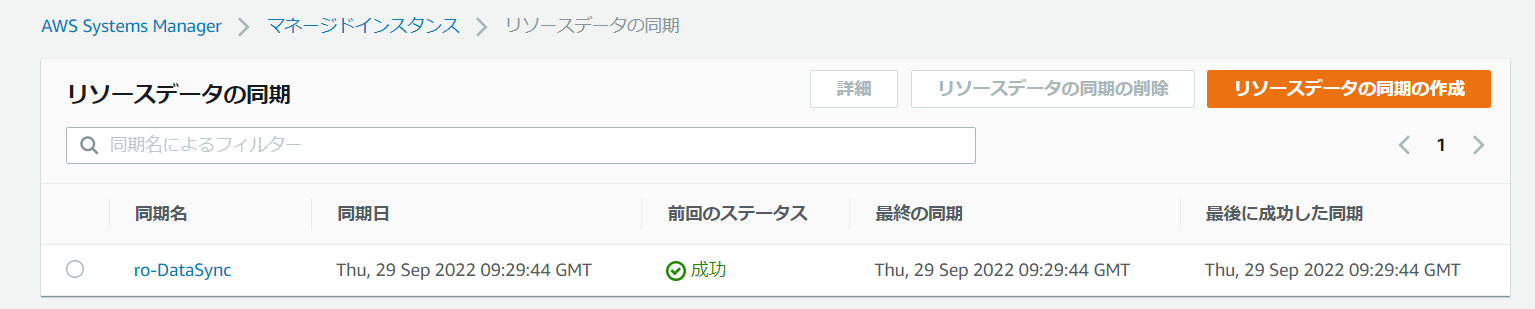
右下の作成ボタンをクリックします。 -
リソースデータの同期一覧が表示され、最後にいつ同期が完了したのかが表示されます。
4.3.同期情報の確認
早速ですが、S3バケットに移動して、インベントリ情報が出力されているかを確認しましょう。
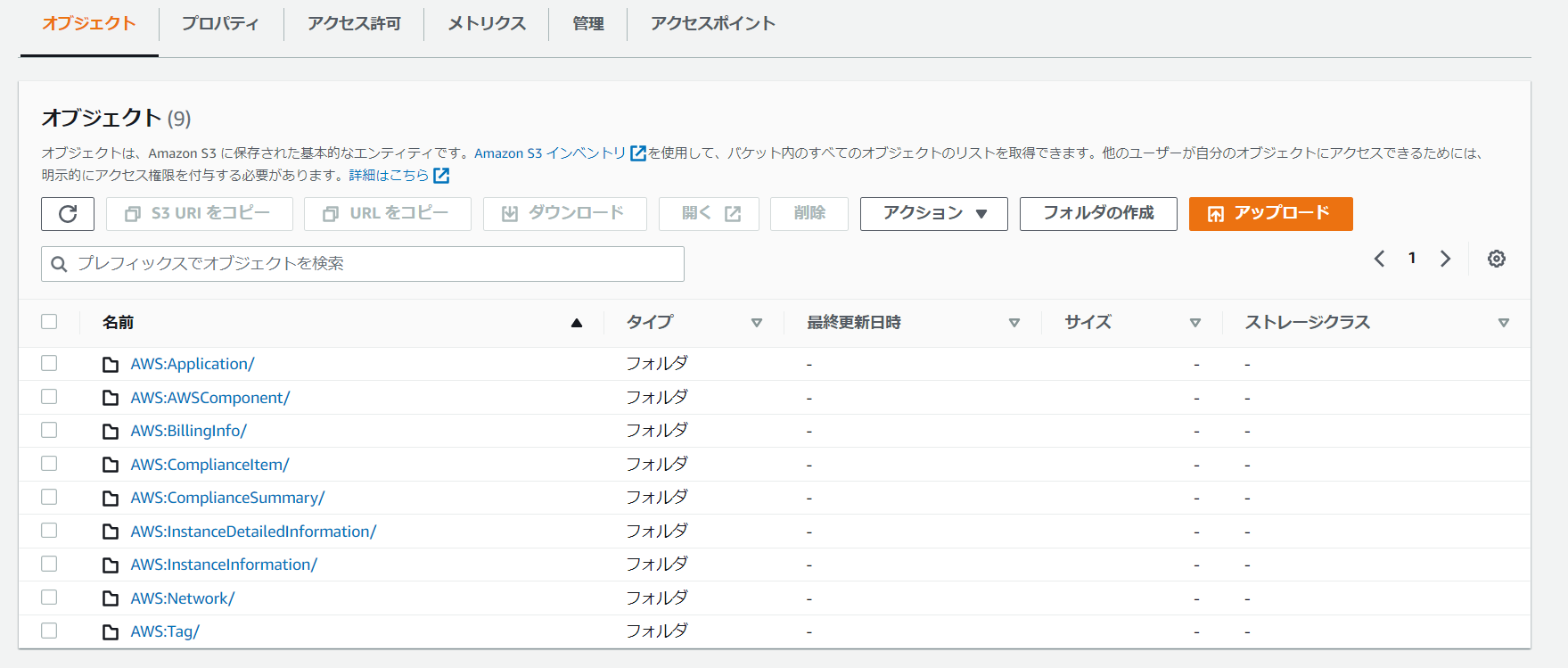
問題なく確認がとれました!






5.データベースとテーブルの作成
それでは、Glue クローラを使って、S3をクロールして情報を集めましょう。
5.1.データベースを作成
-
サービスの検索で、Glueと入力して、Glueを選択します。左のメニューから「データベース」を選択します。ページが開いたら、「データベースの追加」をクリックします。
-
データベース名を入力し、作成ボタンをクリックします。
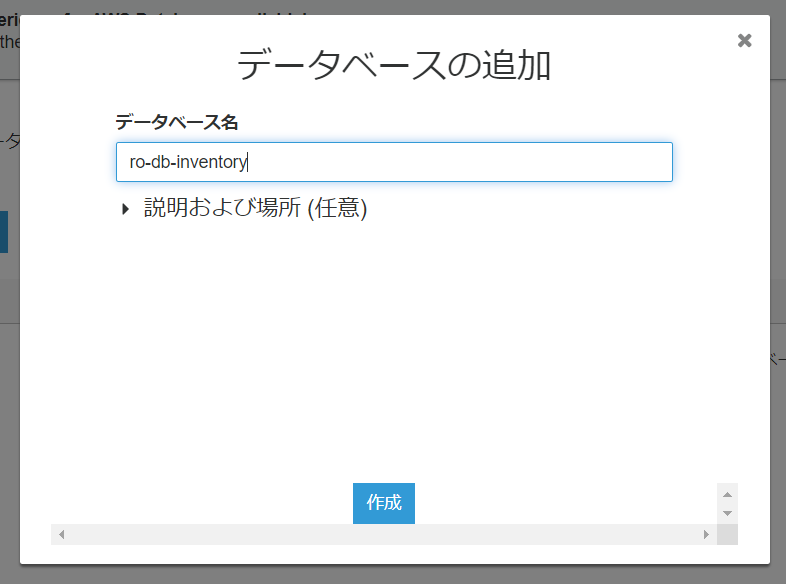
-
データベースの作成が完了です。
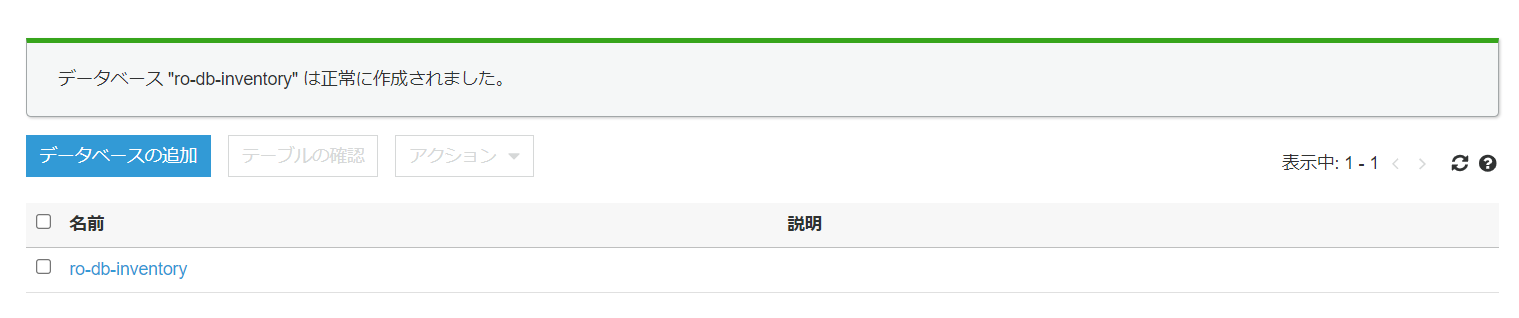
5.2.クローラを作成
-
Glue左のメニューからテーブルを選択します。ページが開いたら、「クローラを使用してテーブルを追加」をクリックします。
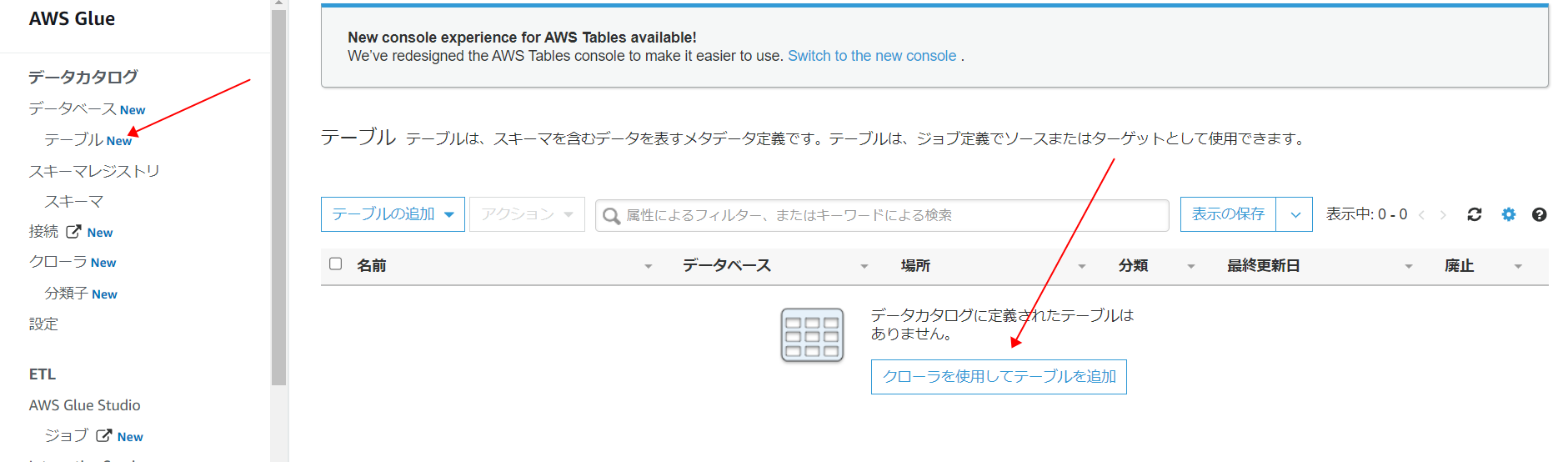
-
以下の手順通りに設定してみてください。
- クローラに関する情報の追加
クローラの名前を入力します。
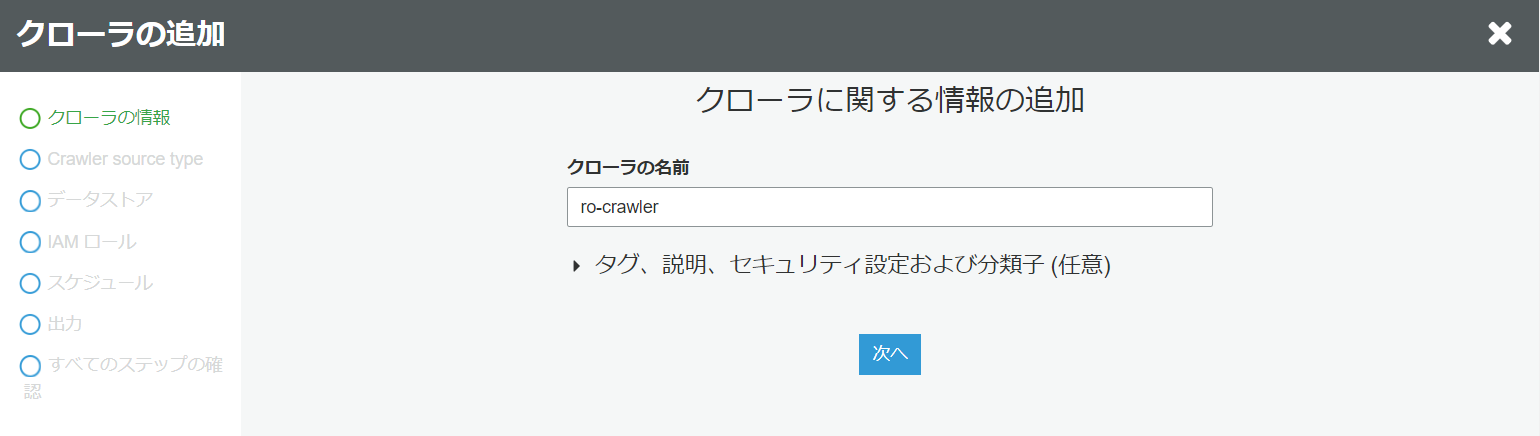
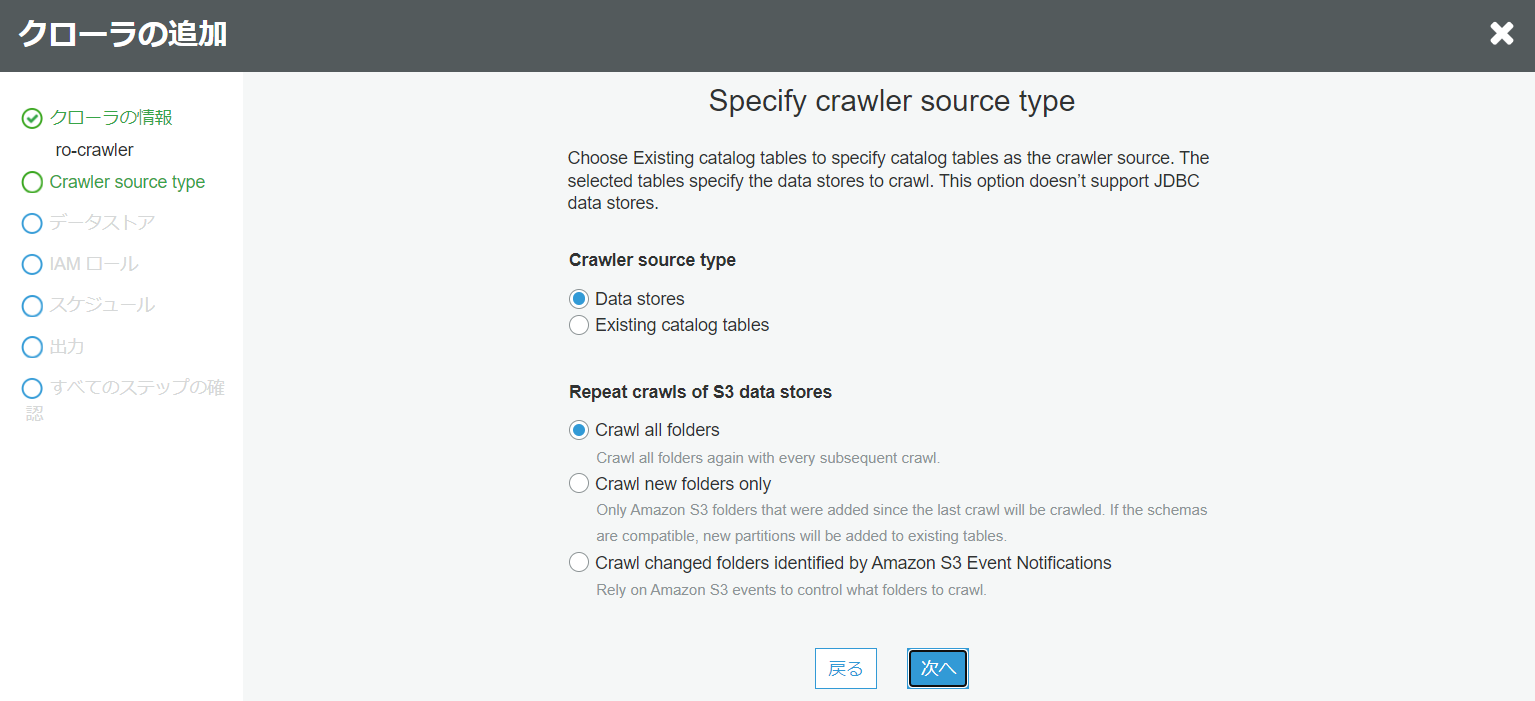
- Crawler source type
デフォルトのままで次に行きます。
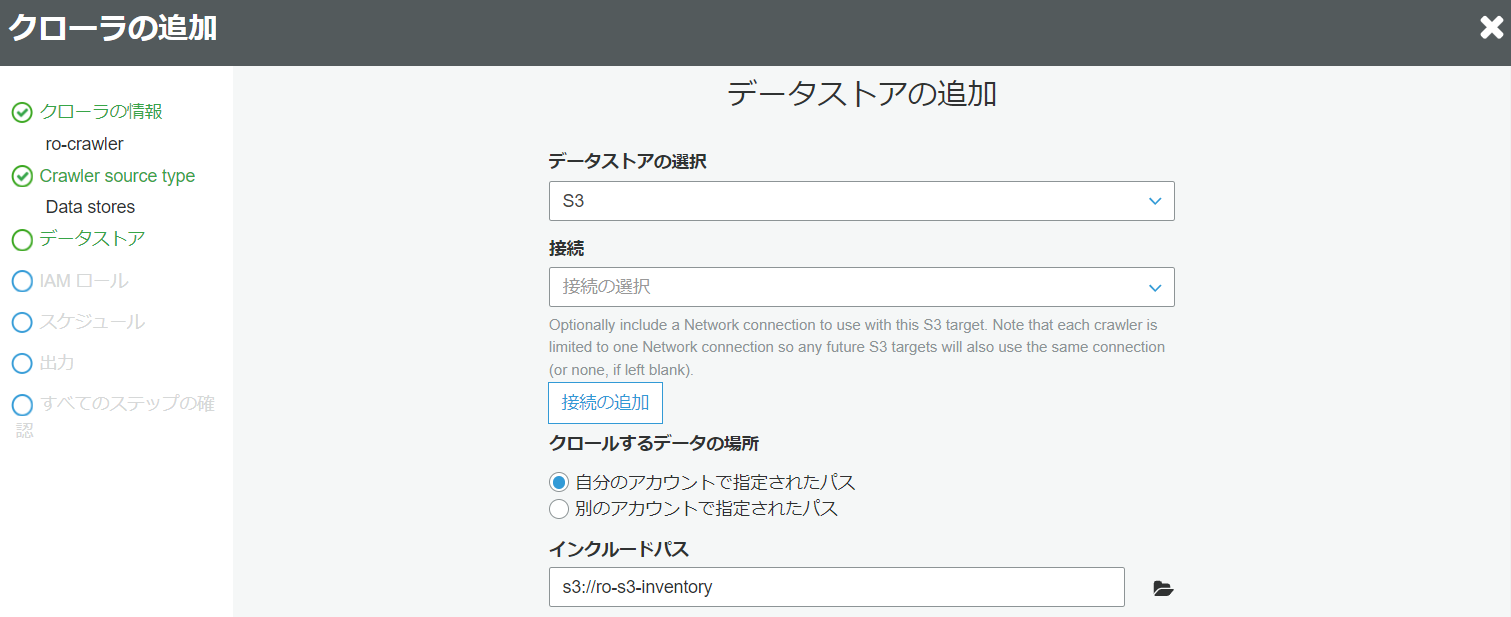
- データストア
インクルードパスを対象バケットを選択する。
ほかの設定箇所はデフォルトで「次へ」ボタンクリックします。
(glueはリージョンサービスのため、S3バケットとglueは同じリージョンであることが前提)
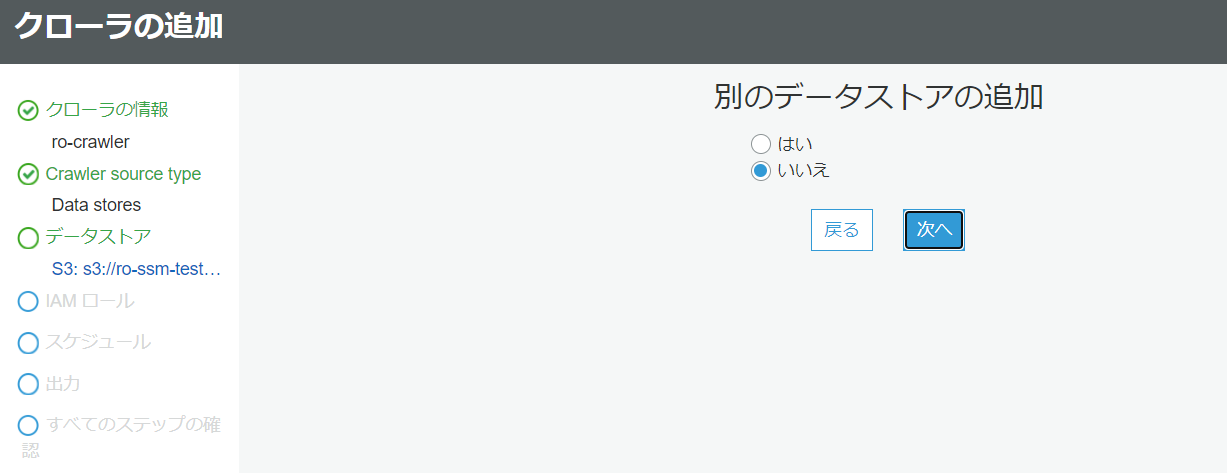
- 別のデータストアの追加
デフォルトのままで次に行きます。
- IAMロールの選択
既存の IAM ロールを選択します。
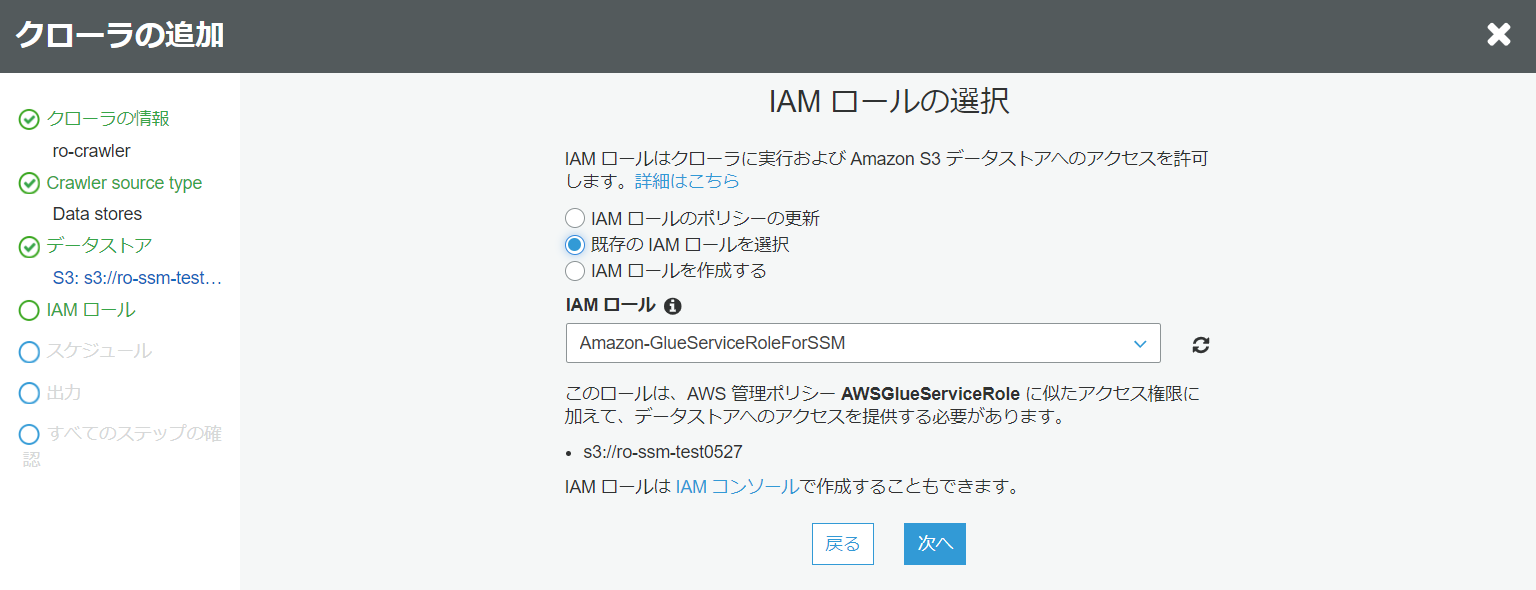
既存の IAM ロールがなければ、作成することも可能です。
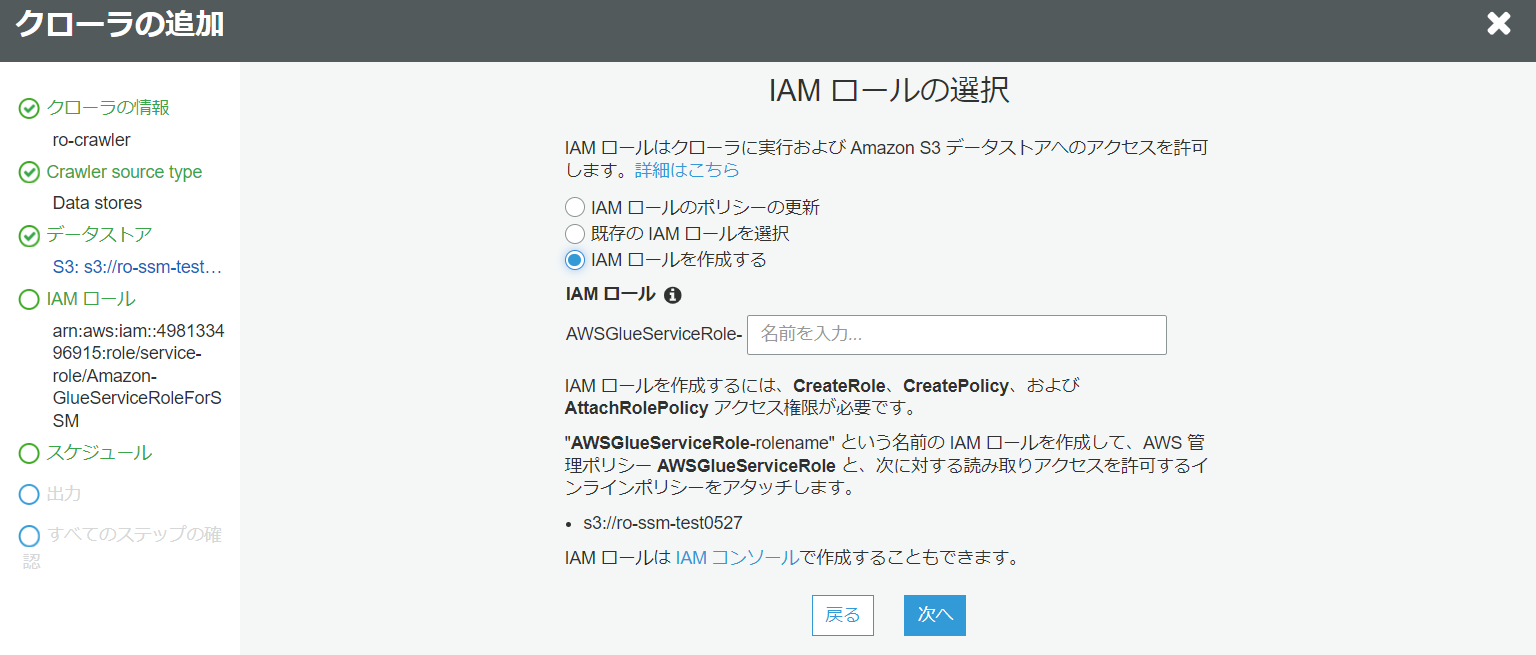
- このクローラのスケジュールを設定する
デフォルトのままで次に行きます。
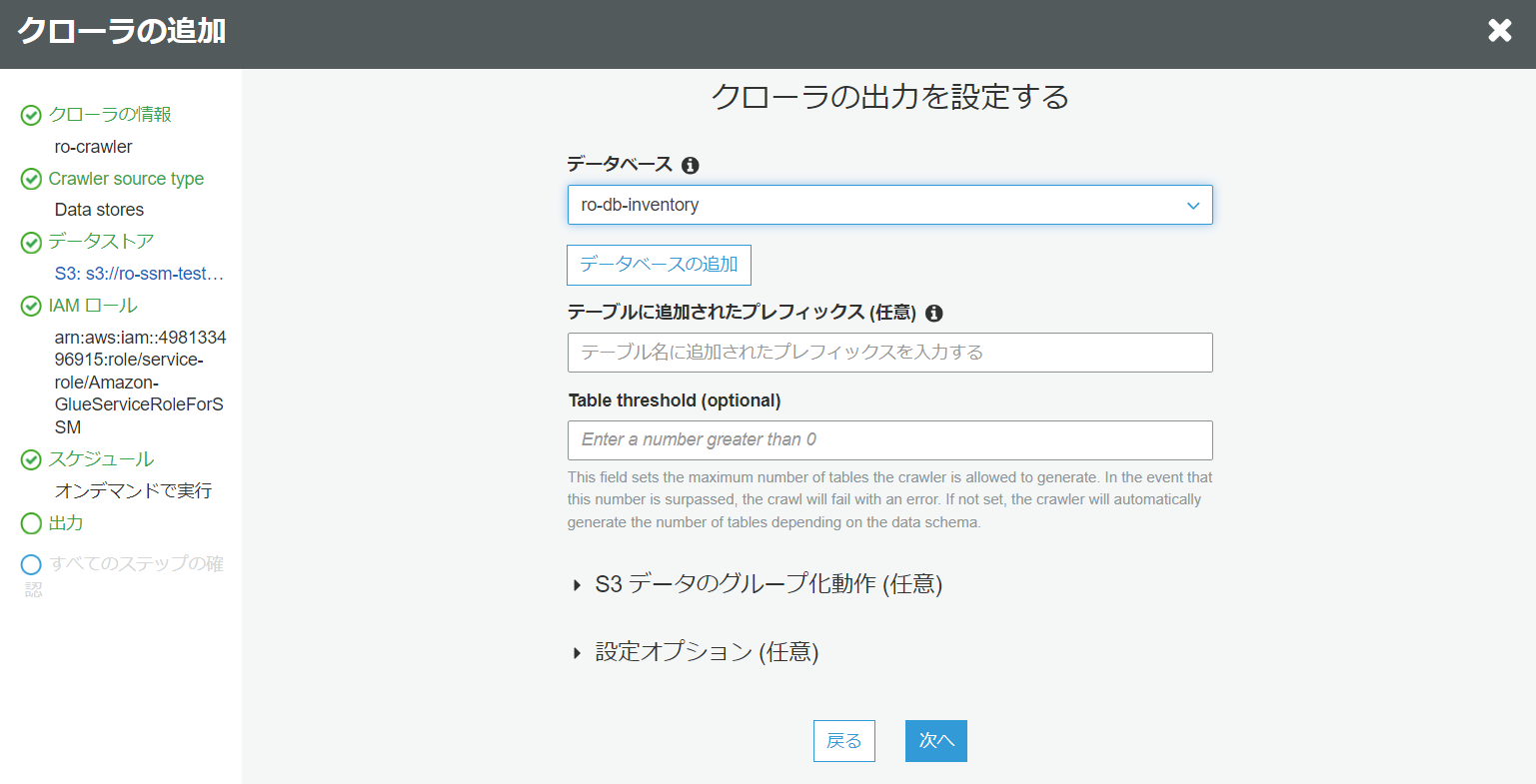
- クローラの出力を設定する
5.1で作成したのデータベース名を入力し、次に行きます。
- 最後すべてのステップを確認して完了ボタンをクリックします。
画面が遷移して作成されていることが確認できました。
- クローラに関する情報の追加














※テーブルを作成する前、一つの事前作業があります。
クローラを実行する時にエラーが発生しないよう不要なjsonファイルを削除:
・対象のバケットオブジェクト名をクリックして、各インベントリ情報のフォルダが表示されることを確認します。
・前項で表示されたバケット画面の「AWS:InstanceInformation」をクリックします。
アカウントIDが記載された以下のオブジェクト(フォルダ)が表示されます。accountid=xxxxxxxx
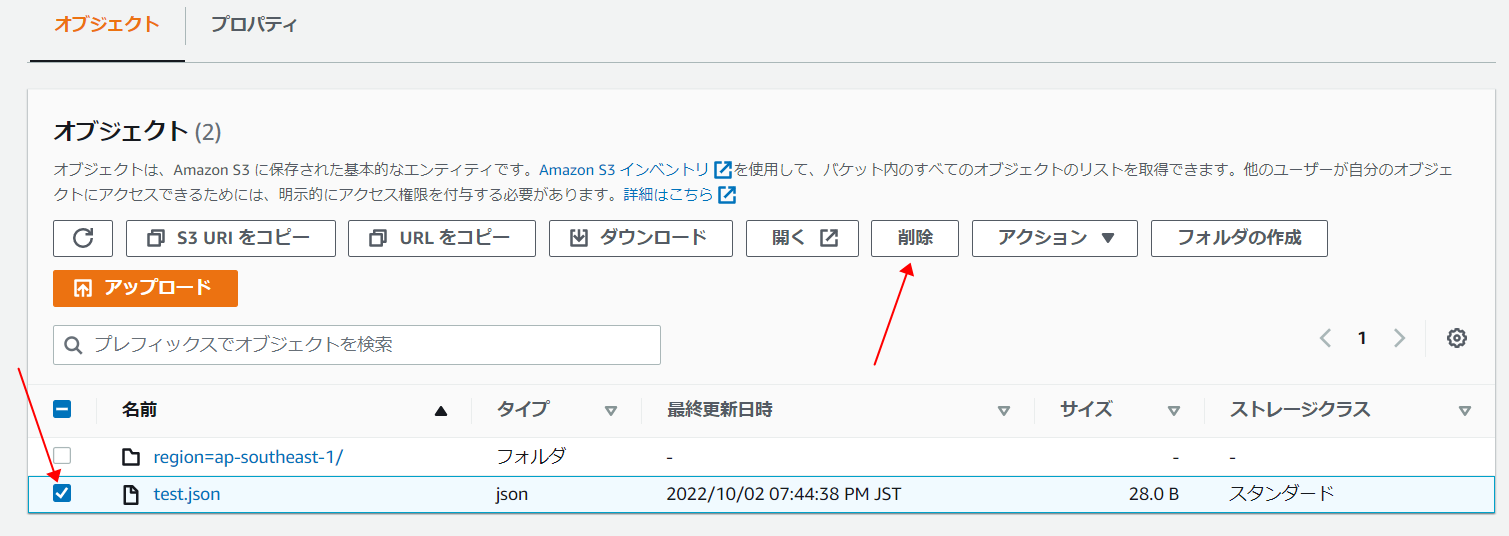
・対象オブジェクト直下の「test.json」ファイルを選択して削除します。
・「概要」項目にて正常に削除されたことを確認します。




5.3.テーブルを作成
- 作成したのクローラを選択して、「クローラの実行」をおします。
- 実行中になりました。少し待ちましょう。
- テーブルの作成が完了です。




6.クエリを実行してみる
lambdaを作成する前に、まずはAhtenaにてクエリを実行してみましょう。
-
Athenaコンソール画面を開いて、データベースを選択します。
-
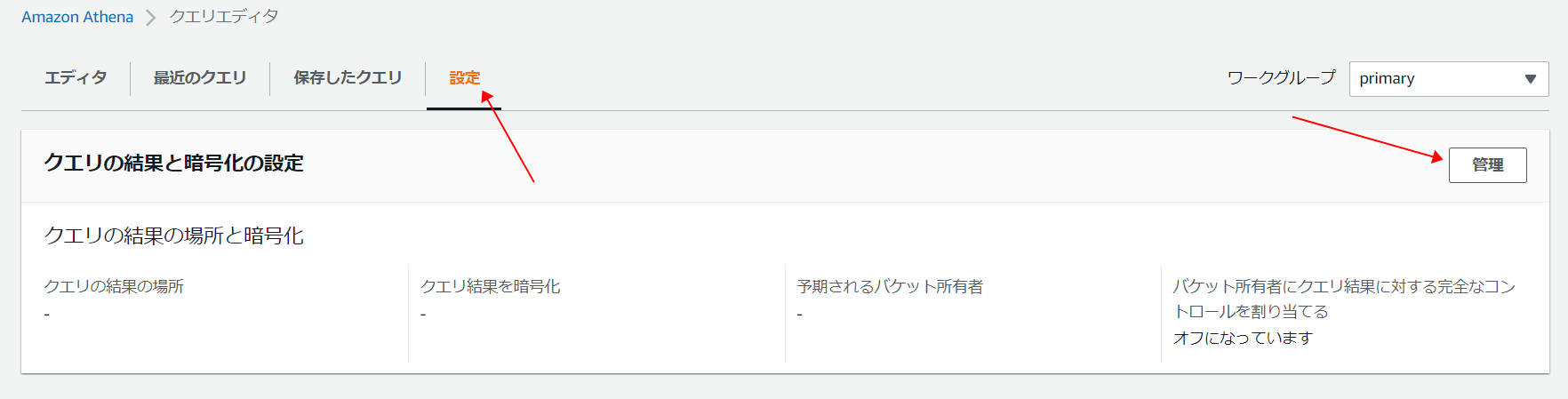
最初のクエリを実行する前に、Amazon S3 でクエリ結果の場所を設定する必要がありますので、
「設定」⇒「管理」をクリックします。
-
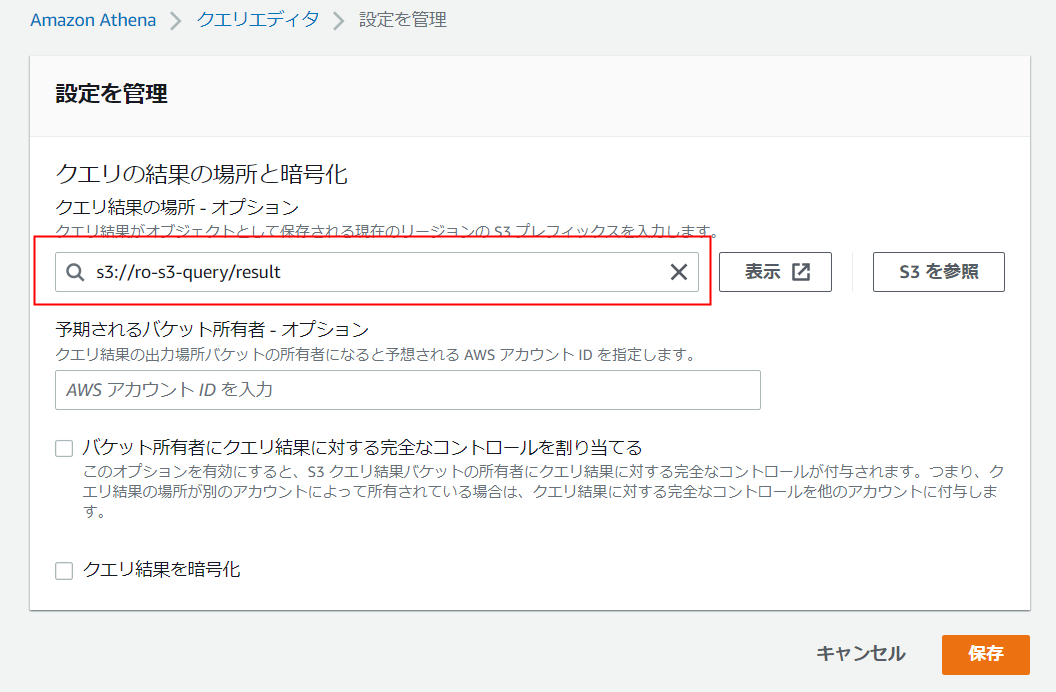
クエリ結果の出力パスを指定して、保存します。
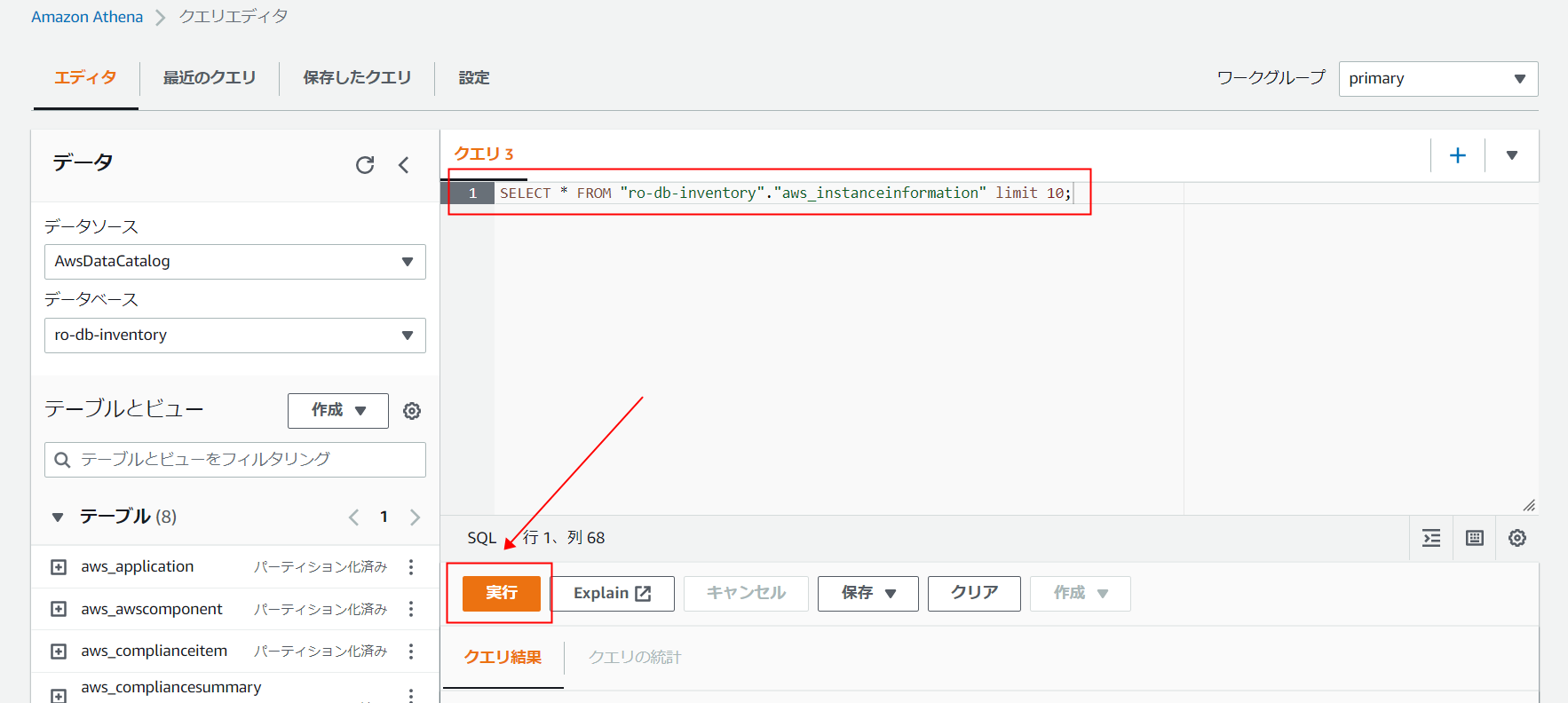
4.クエリを実行してみましょう。
テストとして
SELECT * FROM "ro-db-inventory"."aws_instanceinformation" limit 10;
を入力して、「実行」ボタンをクリックします。
5.失敗です!なぜだろうか。。。(他のテーブルが問題なくクエリ実行できたことを確認済み、aws_instanceinformationテーブルのみエラーが発生している状況)
エラーメッセージ: Table descriptor contains duplicate columns
カラムが重複している?
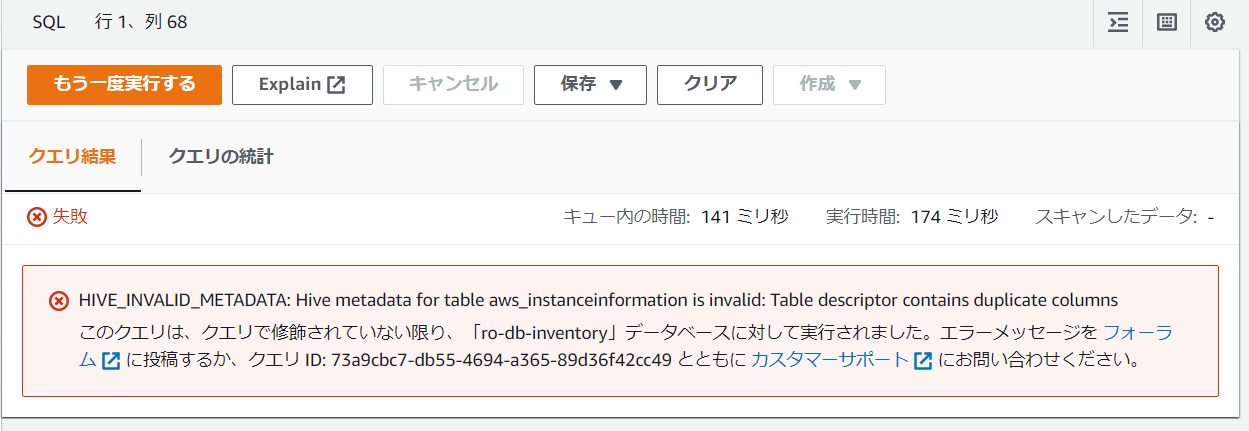
テーブル「aws_instanceinformation」を確認すると、確か「resourcetype」のカラムが重複しています⇒パーティションキー列と非パーティションキー列

これはAWS仕様上の問題だと思われますので、サポートにも問合せたのですが、現時点で回避対策しか提供できません。
回避対策をここで共有します:






- マネジメントコンソールの Glue データカタログの画面より Glue クローラにより作成された 対象のテーブルを選択し、詳細画面を開く。
- "スキーマの編集"を選択する。
- 列名の"resourcetype"(非パーティションキー列)を"resource_type"などの別名に変更するか、削除する。
- "保存"を選択する。
- マネジメントコンソールの Glue クローラの画面より作成したクローラを選択する。
- "編集"を選択する。
- 画面左の"出力"を選択する。
- "設定オプション(任意)"を開き、"クローラがデータストアのスキーマ変更を検出した場合に、AWS Glue はデータカタログでテーブルの更新をどのように取り扱いますか?"の項目で"変更を無視して、データカタログのテーブルを変更しません。"を選択する。
- "次へ"を選択したあと"完了"を選択し、クローラを更新する。
また、以上の手順の 5-9 を実施してからクローラを実行すると、新しいパーティションについてもテーブルに追加できることを確認しました。
- 回避対策を実施しましたら、エラーが解消しました。クエリ実行できました!
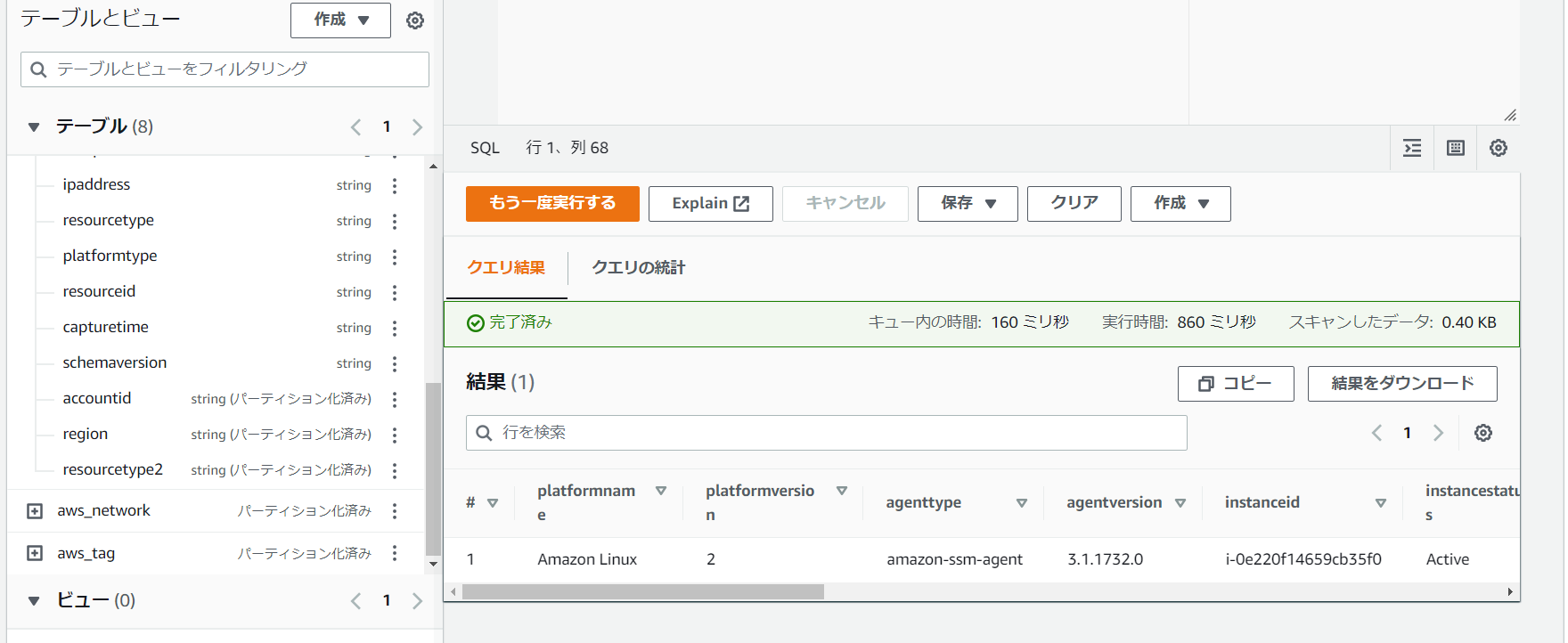

これで SSM から S3 に対してリソースデータの同期が行われ、さらに AWS Glue カタログに登録された状態になりました。
7.Lambda作成
定期的にインベントリ情報帳票を作成するLambda関数を作りましょう。
-
Lambda 用の AWS Identity and Access Management (IAM) サービスロールを作成します。次に、Athena、Amazon Simple Storage Service (Amazon S3)、および Amazon CloudWatch Logs へのアクセスを許可するポリシーをアタッチします。例えば、AmazonAthenaFullAccess と CloudWatchLogsFullAccess をロールに追加できます。 AmazonAthenaFullAccess は Athena へのフルアクセスを許可し、Amazon S3 の基本的なアクセス許可を含みます。CloudWatchLogsFullAccess は CloudWatch Logs へのフルアクセスを許可します。
(IAM Roleの設定詳細はここでは割愛) -
Lambda コンソールを開いて、[関数の作成] を選択します。
-
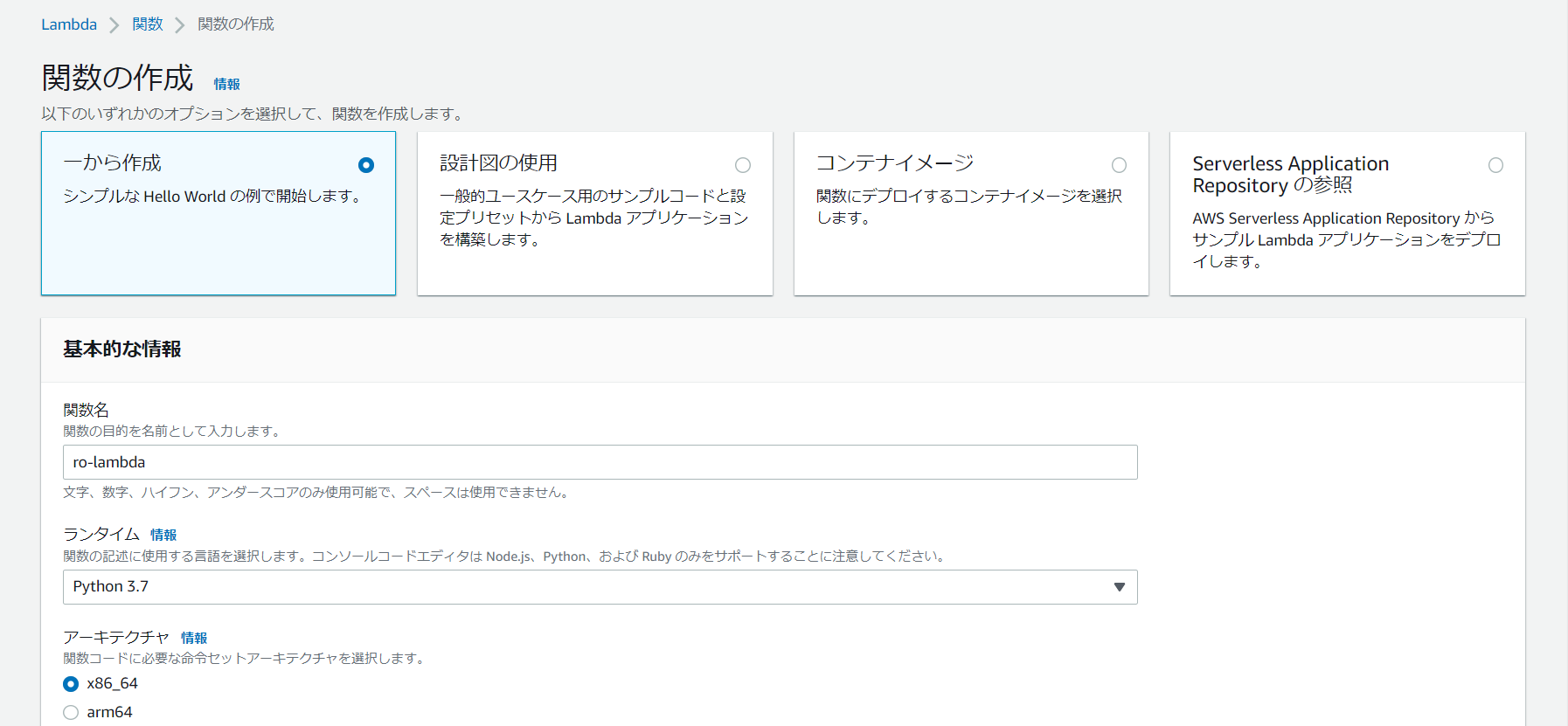
[一から作成] が選択されていることを確認し、次のオプションを設定します。
[名前] に関数の名前を入力します。
[ランタイム] で、Python オプションのいずれかを選択します。
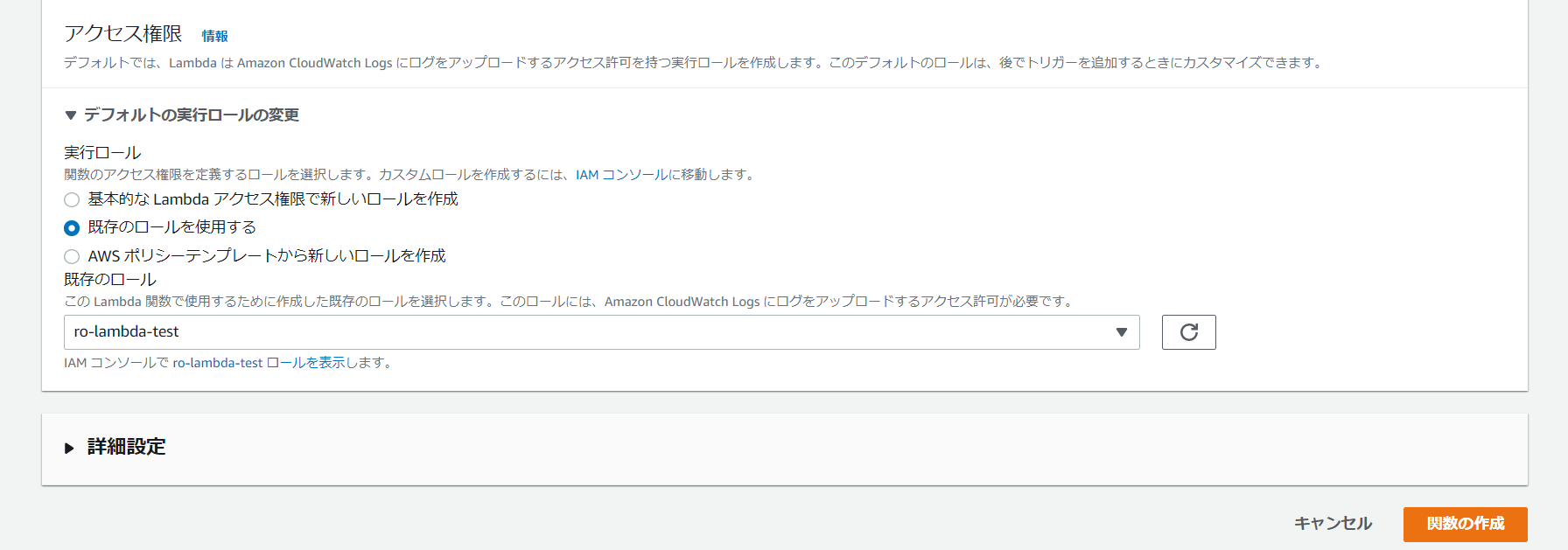
[ロール] で、[既存のロールを使用する] を選択し、ステップ 1 で作成した IAM ロールを選択します。
-
[(関数を作成)] を選択します。
-
[関数コード] セクションにコードを貼り付けます。次の例では Python 3.7 を使用します。例にある次の値を置き換えます。
default: Athena データベース名
*SELECTFROM default.tb: クエリ
s3://AWSDOC-EXAMPLE-BUCKET/**: クエリ出力のための S3 バケット



import time
import boto3
query = 'SELECT * FROM default.tb'
DATABASE = 'default'
output='s3://AWSDOC-EXAMPLE-BUCKET/'
def lambda_handler(event, context):
query = "SELECT * FROM default.tb"
client = boto3.client('athena')
# Execution
response = client.start_query_execution(
QueryString=query,
QueryExecutionContext={
'Database': DATABASE
},
ResultConfiguration={
'OutputLocation': output,
}
)
return response
return- [Deploy] を選択します。
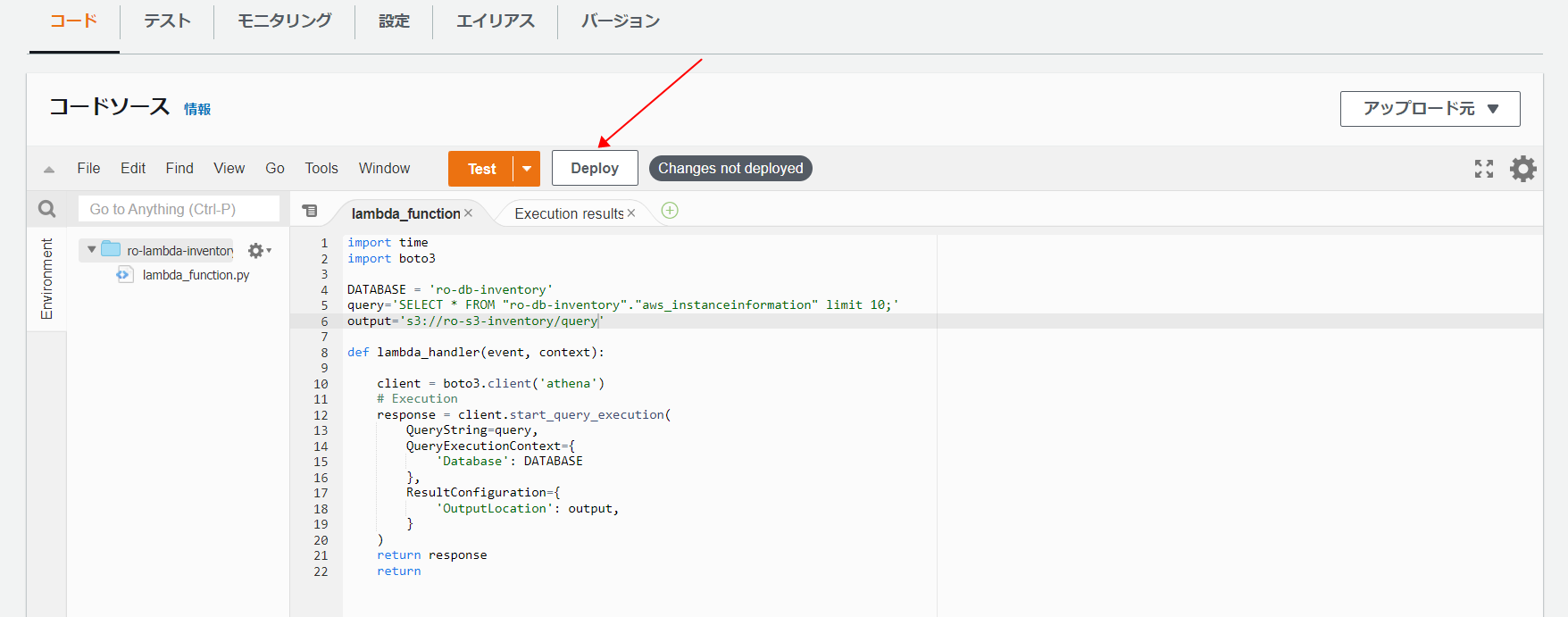

これでlambdaの設定が終わりました。
8.イベントルールを作成
Amazon EventBridge ルールを作成して、Lambda 関数をスケジュールします。
8.1.イベントルールの作成
-
Amazon EventBridge コンソールを開きます。
ナビゲーションペインで [ルール]を選択し、続いて [ルールを作成] を選択します。
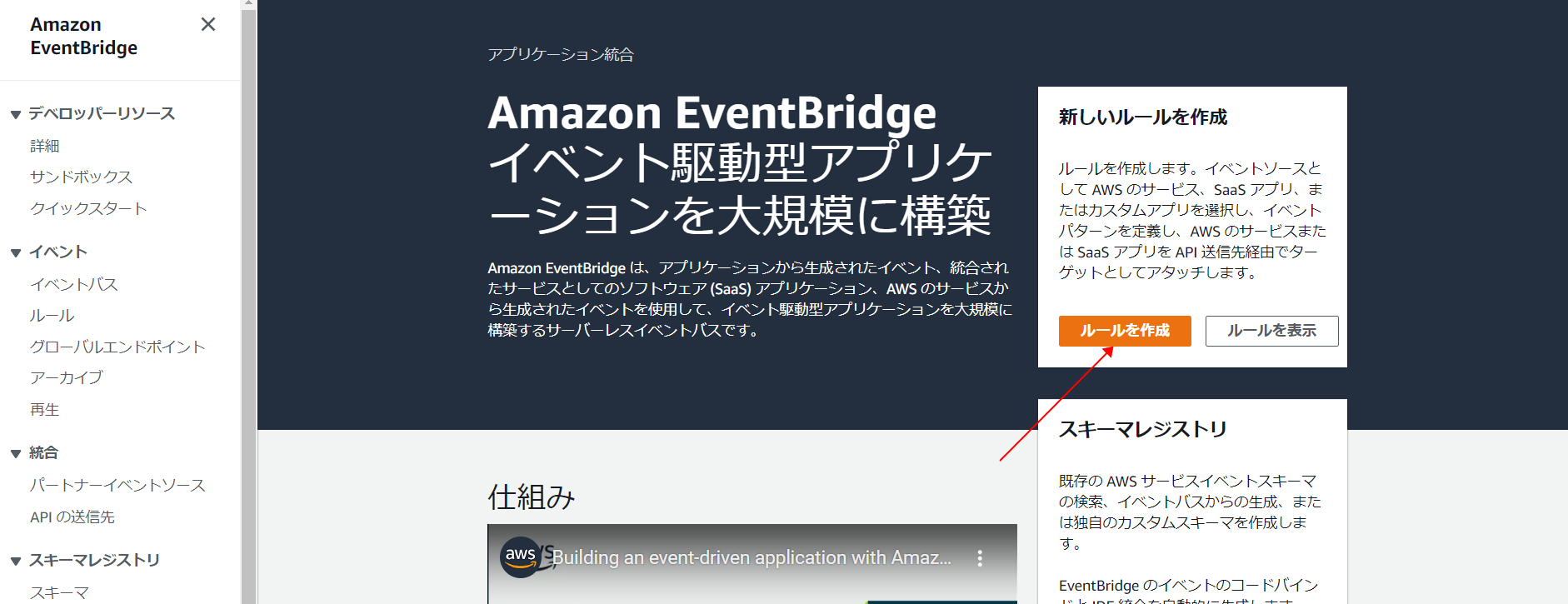
-
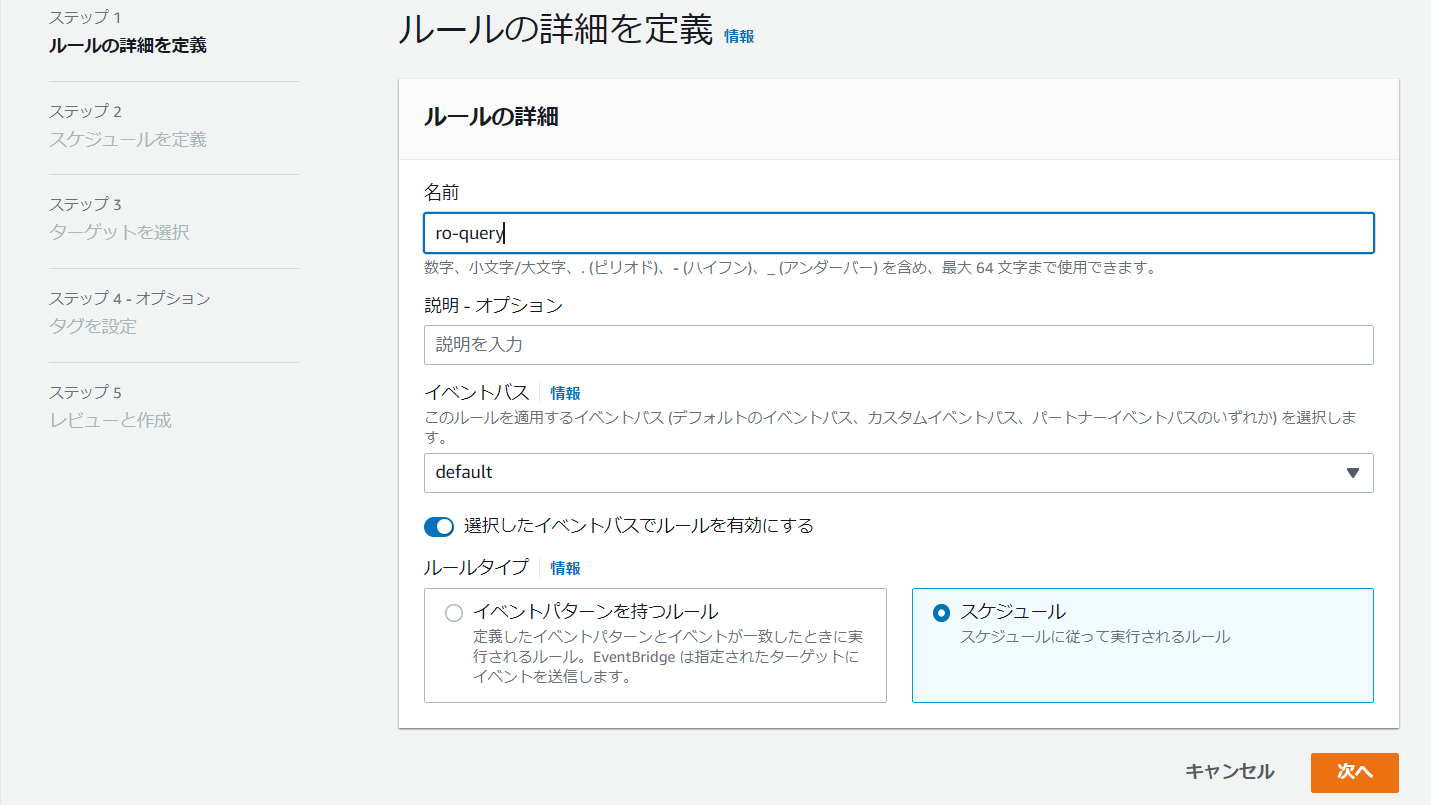
ルールの名前と説明を入力します。
[パターンを定義]で、[スケジュール]を選択します。
-
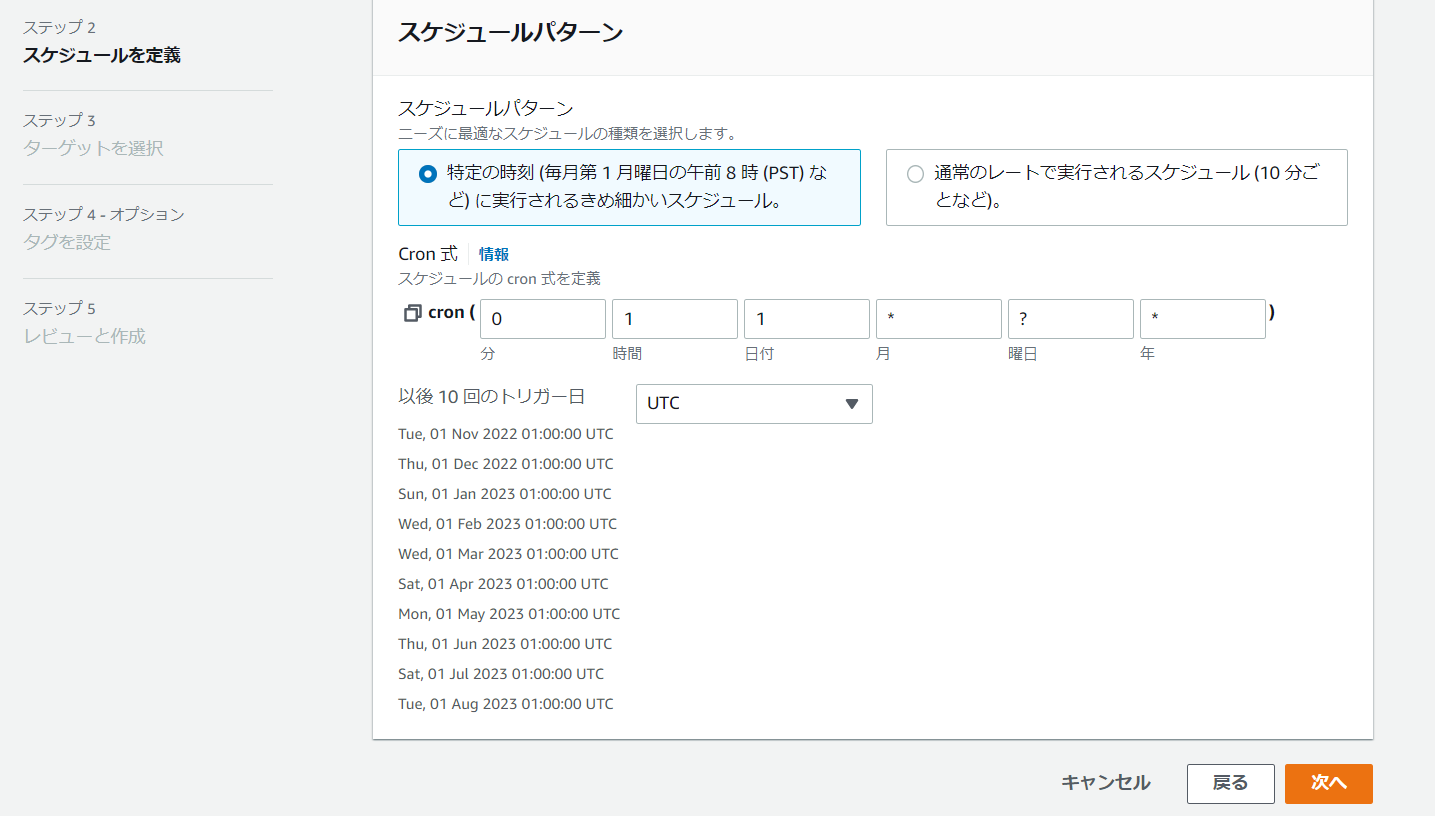
cron 式を入力します。
-
「ターゲットタイプ」が「AWSのサービス」を選択して、[ターゲット] で、ドロップダウンリストから 「Lambda 関数」 を選択します。「関数」で、ドロップダウンリストから Lambda 関数の名前を選択します。
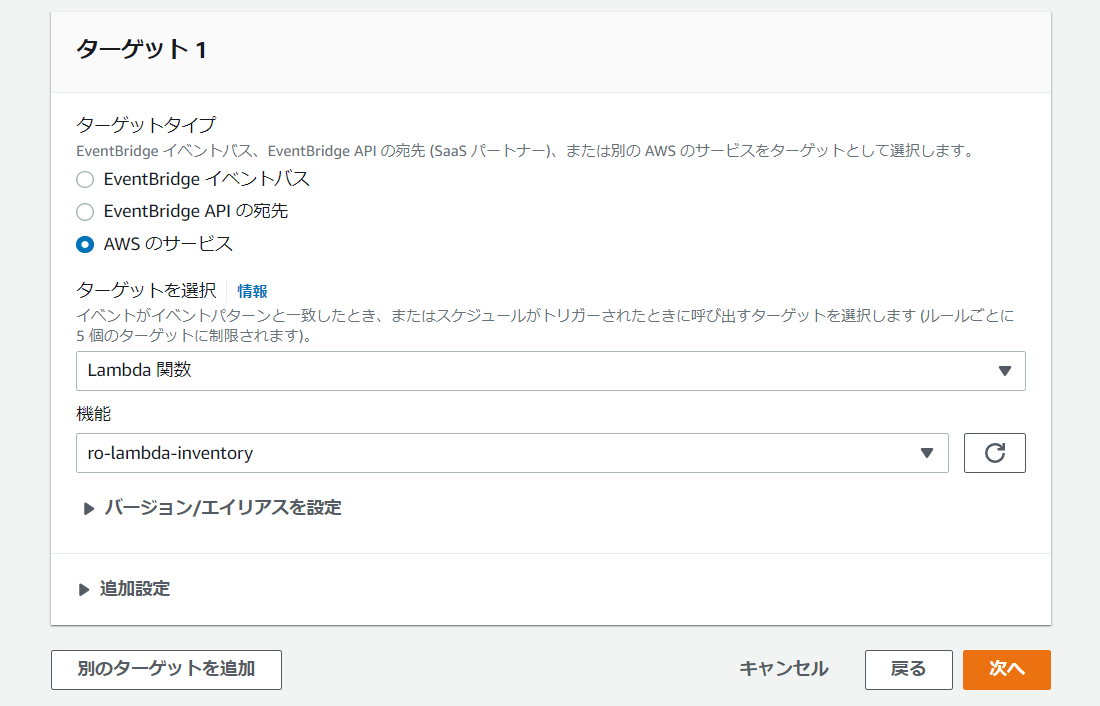
-
「次へ」をクリックし、最後に「ルールの作成」を押します。画面が遷移して作成されていることが確認できました。





8.2.テスト
テストとして実際にイベントルールからLambdaを呼び出します。
-
先作成したのイベントルールを選択して、ルールの詳細画面が表示されます。「編集」ボタンをクリックします。
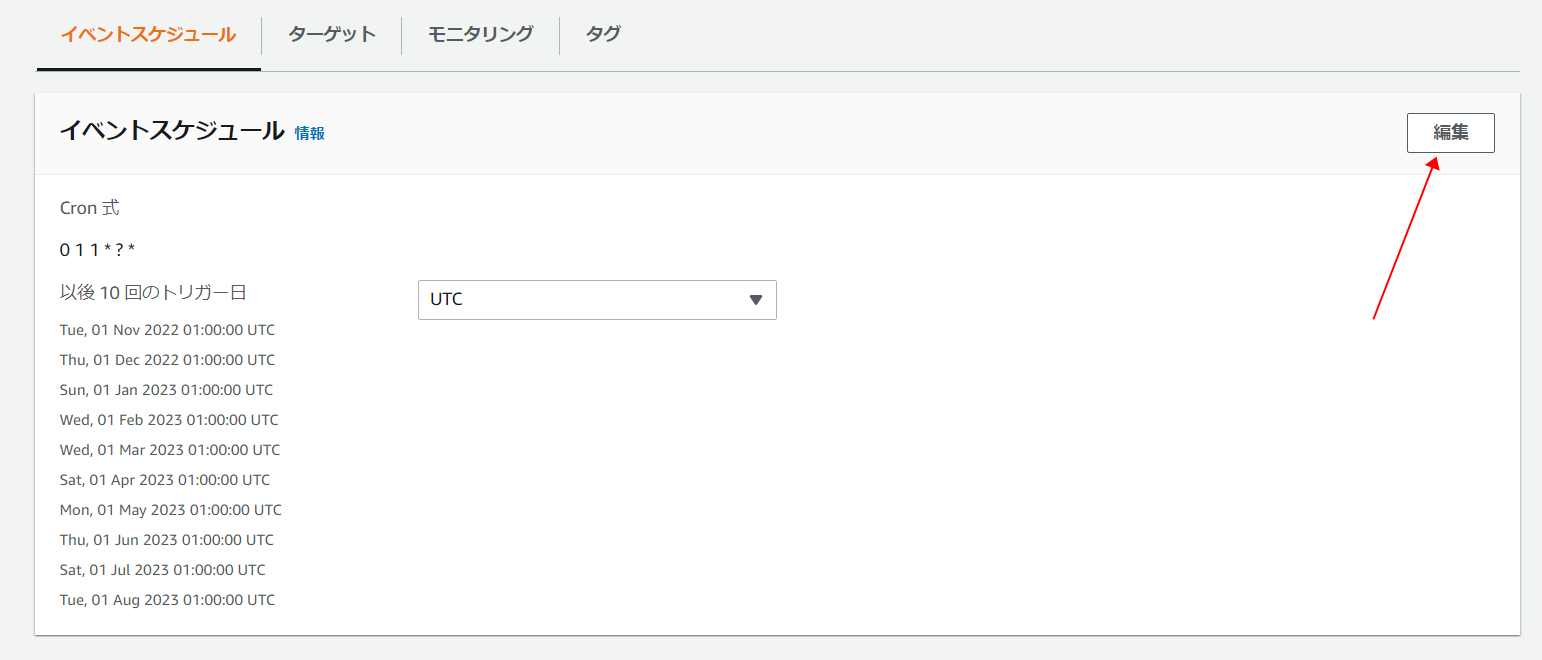
-
イベントルールのCron式設定をテスト実施予定の時間に変更します。(注意点:UTC時間変換)
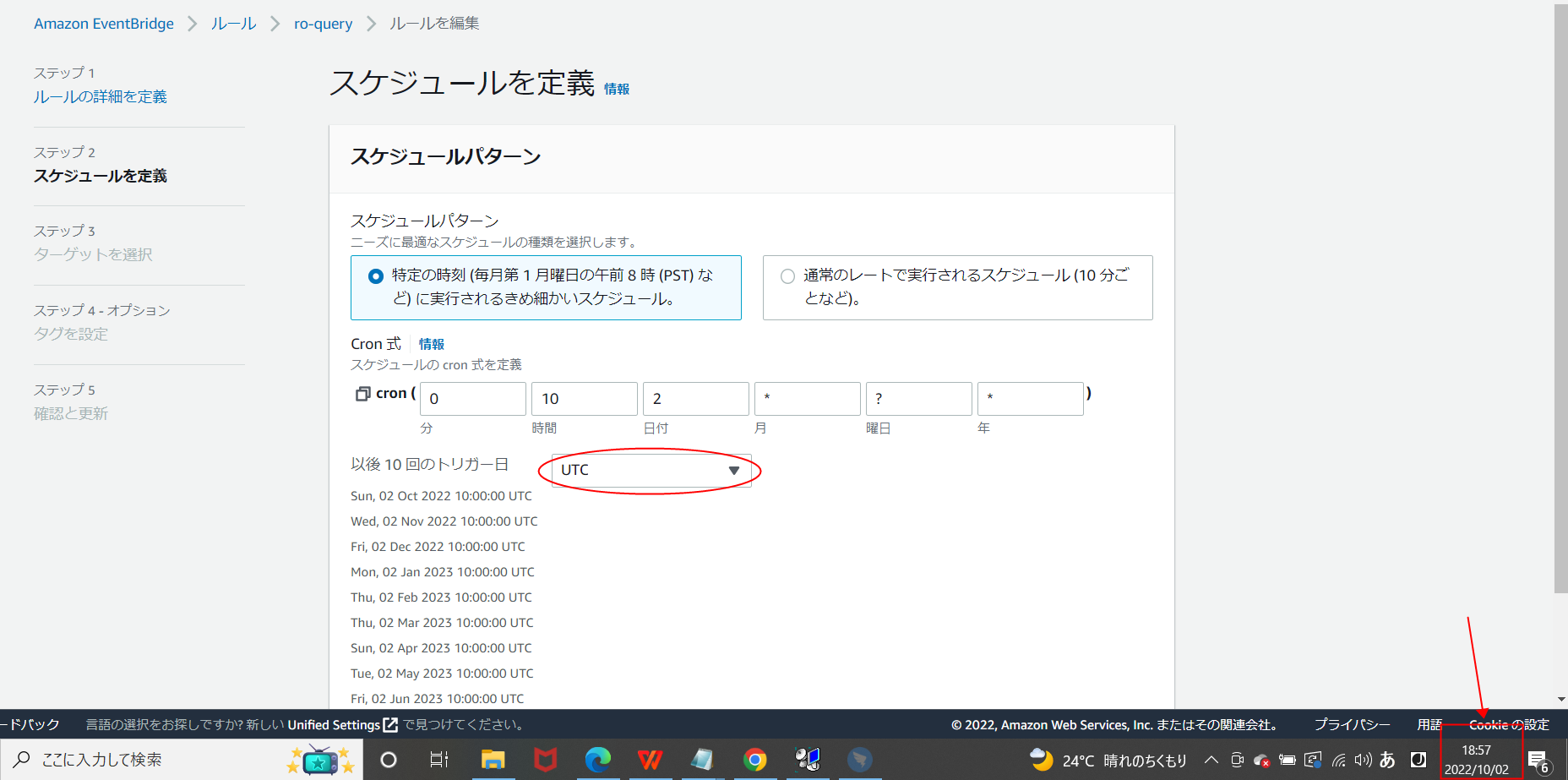
-
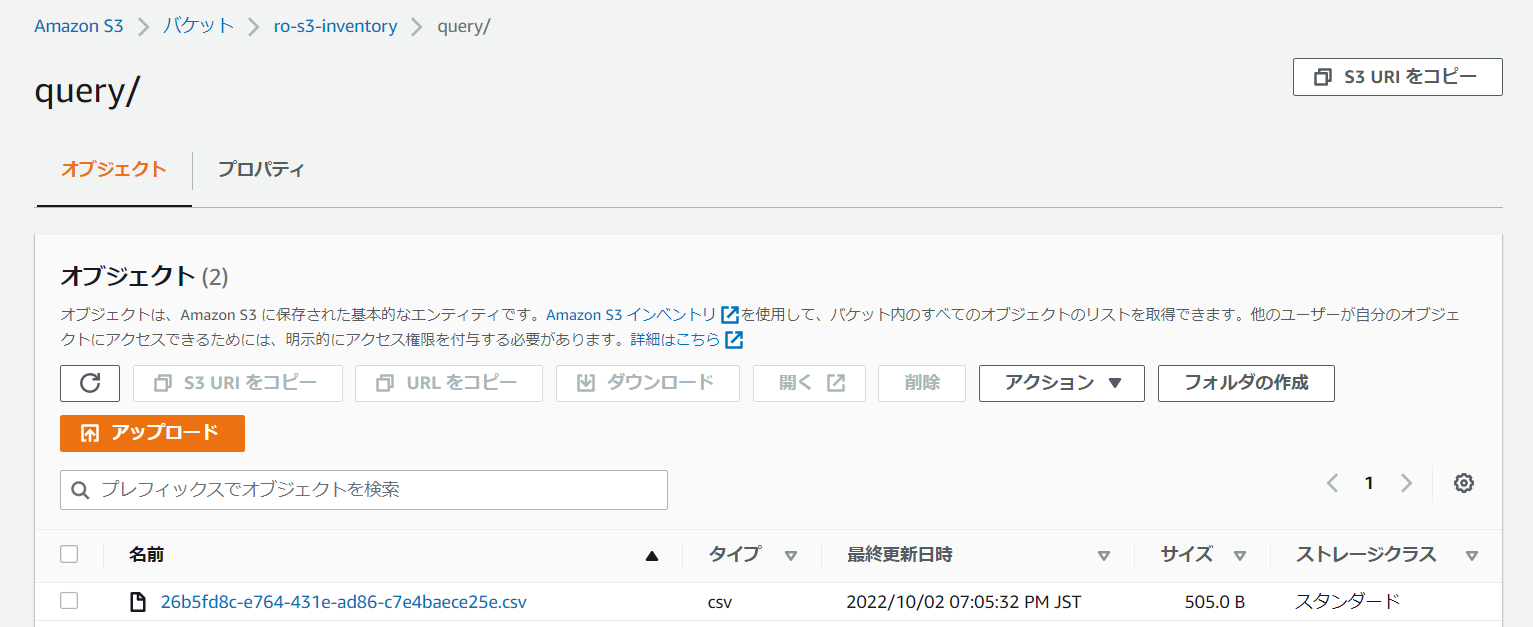
時間になりましたら、テスト結果を確認します。帳票の出力先S3に移動します。
帳票が出力されたことを確認できました!



※テスト終了後イベントルールのスケジュール設定を戻すことを忘れないようご注意ください。
おわりに
インベントリはEC2インスタンスへ直接入ることなく、各種メタデータを収集してくれる便利機能です。ぜひ活用してみてください。
以上、SSMインベントリの活用例でした。 少しでも参考になれば幸いです。