


この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
どうも、クラ本部の黒田です。
梅雨明けの連日高温日となりますが、
熱中症対策しっかりしましょうね。
今日は、ByteByteGoがまとめているシステムスケーリング戦略について、アウトプットしていきます。

はじめに:
分散システムのスケーラビリティは、現代のソフトウェアアーキテクチャにおいて最も複雑かつ重要な課題の一つです。本稿では、大規模分散システムの設計と運用において克服すべき技術的挑戦と、それに対する高度なスケーリング戦略について深掘りします。
背景と目的:
ビッグデータ、IoT、AIの台頭により、システムに求められる処理能力と複雑性は指数関数的に増大しています。本稿の目的は、これらの課題に直面するシステムアーキテクトやエンジニアに、理論的基盤と実践的な戦略を提供することです。
システム拡張について:
システム拡張は単なる「より多くのリソースの追加」ではありません。それは、システムの構造的な再設計、データフローの最適化、そして分散アルゴリズムの適用を含む、多面的なアプローチです。ここでは、CAP定理とPALCELCの原理を念頭に置きつつ、実際のシステム設計における trade-off について議論します。
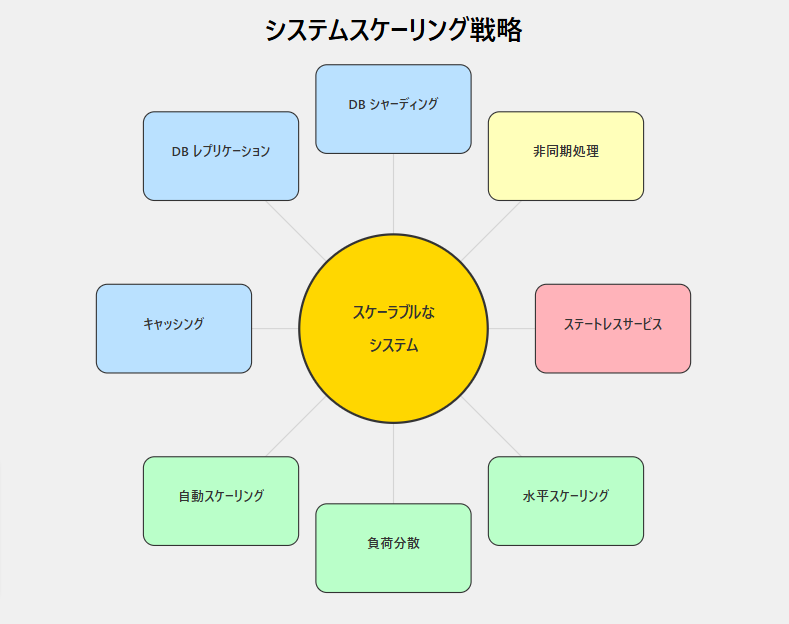
システムをスケーリングするための8つの重要な戦略:
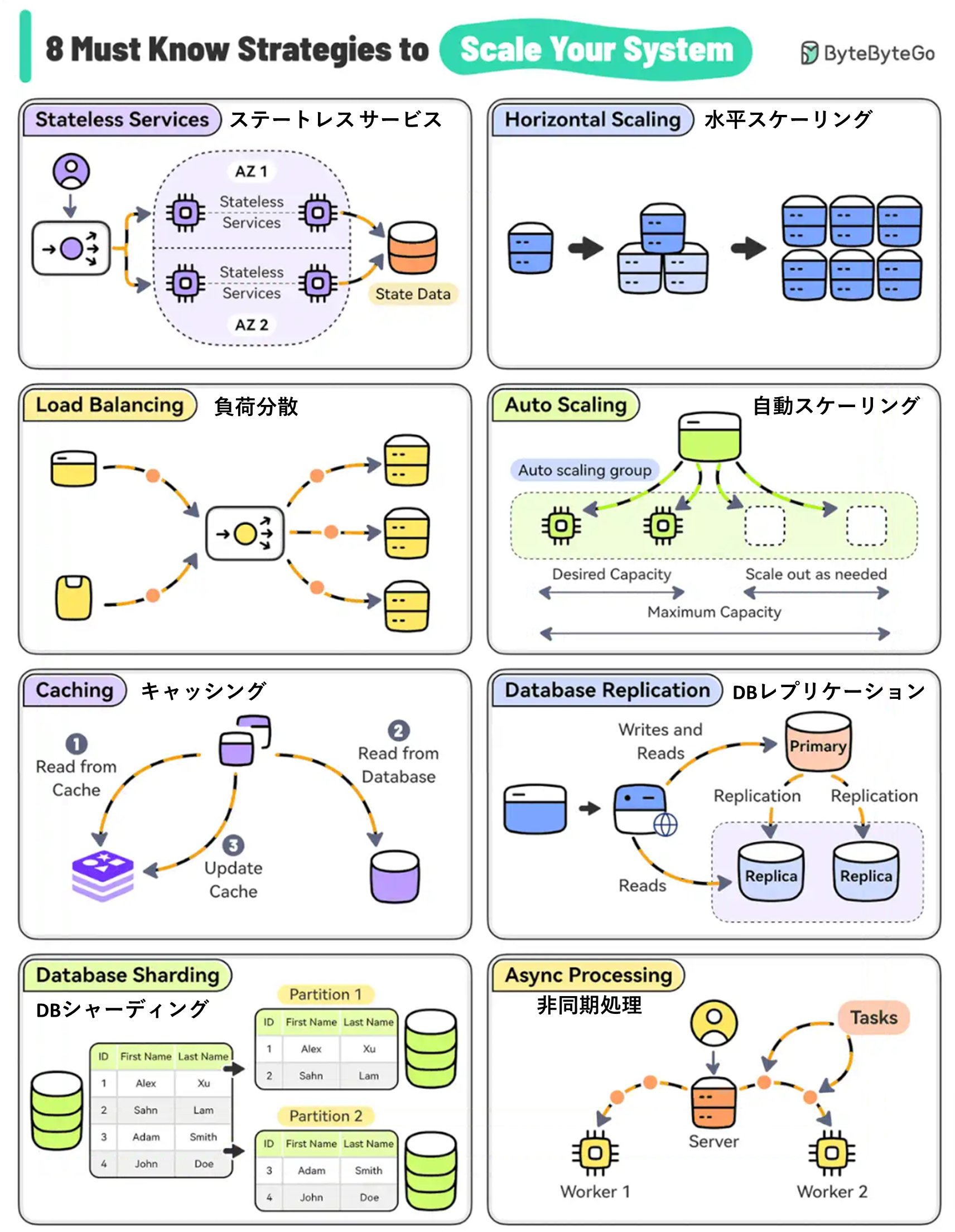
1. Stateless Services (ステートレスサービス):
理論: 分散システム理論におけるステートレス性の重要性
実例: Netflix のマイクロサービスアーキテクチャ
Netflix は、ユーザーセッション情報を EVCache(Memcached ベースの分散キャッシュシステム)に保存し、個々のサービスをステートレスに保っています。これにより、サービスの水平スケーリングが容易になり、障害時の復旧も迅速に行えます。
重要ポイント: イベントソーシングとCQRSパターンの適用
注意事項: 結果整合性モデルの採用とその影響
2. Horizontal Scaling (水平スケーリング):
理論: Amdahlの法則とスケーラビリティの限界
実例: Amazon DynamoDB のパーティショニング
DynamoDB は、データをパーティションキーに基づいて複数のノードに分散させます。各パーティションは独立してスケールし、全体のスループットを線形に向上させます。
重要ポイント: シャーディングとパーティショニング戦略
注意事項: ネットワーク分断時の挙動 (Split-Brain 問題)
3. Load Balancing (負荷分散):
理論: キューイング理論とLittle’s Law
実例: Google の Maglev ソフトウェア負荷分散器
Maglev は、一貫性ハッシュを使用して数百万の接続を効率的に分散させます。障害時には数秒で他のMaglevインスタンスに負荷を移転できます。
重要ポイント: 動的負荷分散アルゴリズムの実装
注意事項: ホットスポット問題とその緩和策
4. Auto Scaling (自動スケーリング):
理論: 制御理論の応用と予測的スケーリング
実例: Uber の Peloton リソーススケジューラ
Uber は Peloton を使用して、需要予測に基づき動的にコンピューティングリソースを割り当てます。機械学習モデルを用いて、将来の需要を予測し、プロアクティブにスケーリングを行います。
重要ポイント: リアクティブとプロアクティブスケーリングの組み合わせ
注意事項: オーバープロビジョニングとコスト最適化のバランス
5. Caching (キャッシング):
理論: 情報エントロピーとキャッシュ効率
実例: Facebook の Memcache インフラストラクチャ
Facebook は、数千台のサーバーにまたがる大規模 Memcached クラスタを運用し、読み取り負荷を大幅に軽減しています。地理的に分散したデータセンター間でのキャッシュ一貫性も維持しています。
重要ポイント: コンテンツデリバリーネットワーク (CDN) の最適化
注意事項: キャッシュの整合性と無効化戦略
6. Database Replication (データベースレプリケーション):
理論: 分散コンセンサスアルゴリズム (Paxos, Raft)
実例: LinkedIn の Espresso 分散文書ストア
Espresso は、マルチマスターレプリケーションを採用し、地理的に分散したデータセンター間で低レイテンシの読み書きを実現しています。Helix を使用して、レプリカ間の一貫性を管理しています。
重要ポイント: マルチマスターレプリケーションの実装
注意事項: 分散トランザクションとデータ整合性の保証
7. Database Sharding (データベースシャーディング):
理論: 一貫性ハッシュとRendezvous ハッシング
実例: Instagram のユーザーデータシャーディング
Instagram は、ユーザーIDに基づいてデータを数千の論理シャードに分割し、これらを物理サーバー群にマッピングしています。動的シャーディングを採用し、データの増加に応じて自動的にリバランシングを行います。
重要ポイント: 動的シャーディングと再バランシング戦略
注意事項: クロスシャードクエリの最適化とN+1クエリ問題
8. Async Processing (非同期処理):
理論: アクターモデルと Communicating Sequential Processes (CSP)
実例: Twitter のストリーム処理パイプライン
Twitter は、Apache Kafka と自社開発の Heron を使用して、リアルタイムのツイート処理と分析を行っています。バックプレッシャーメカニズムを実装し、システムの過負荷を防いでいます。
重要ポイント: バックプレッシャーメカニズムの実装
注意事項: 非同期システムにおけるデバッグと監視の複雑性
各戦略設計する際の重要ポイントと注意事項:
- 分散システムの根本的な課題(ネットワーク遅延、部分的障害、一貫性vs可用性のトレードオフ)を常に考慮する。
- システムの境界条件と障害モードを明確に定義し、カオスエンジニアリングを通じてシステムの回復力を継続的にテストする。
- 監視、ログ集約、分散トレーシングを統合し、複雑な分散システムの可観測性を確保する。
- パフォーマンステストとキャパシティプランニングを定期的に実施し、スケーリング戦略の有効性を検証する。
まとめ:
高度なスケーリング戦略の実装は、深い理論的理解と実践的経験の両方を要する複雑な課題です。本稿で紹介した8つの戦略は、互いに独立したものではなく、相互に補完し合う要素として捉えるべきです。実際のシステム設計では、これらの戦略を適切に組み合わせ、システムの特性と要件に応じてカスタマイズすることが重要です。
さらに、技術の急速な進化に伴い、新たなパラダイム(例:サーバーレスアーキテクチャ、エッジコンピューティング)が登場しています。これらの新技術が従来のスケーリング戦略にどのような影響を与えるか、継続的に評価し適応していく必要があります。
最後に
スケーラビリティは単なる技術的課題ではなく、組織の文化や開発プロセスとも深く関わっています。DevOpsプラクティスの採用、継続的デリバリーの実践、そして組織全体でのシステム思考の醸成が、真に拡張性の高いシステムを構築・運用する上で不可欠です。
この分野に携わる我々エンジニアは、常に学び、実験し、そして知見を共有し続けることで、次世代の大規模分散システムの基盤を築いていく責任があります。