




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
前提
・AWS CloudShellよりCLI実行すること
・RDS構築(Aurora PostgreSQL グローバル)を構築済みであること
※構築手順を下記の記事を参照
CloudFormationでRDS構築(Aurora PostgreSQL グローバル)を構築する
フィルオーバー手順
コンソールの場合
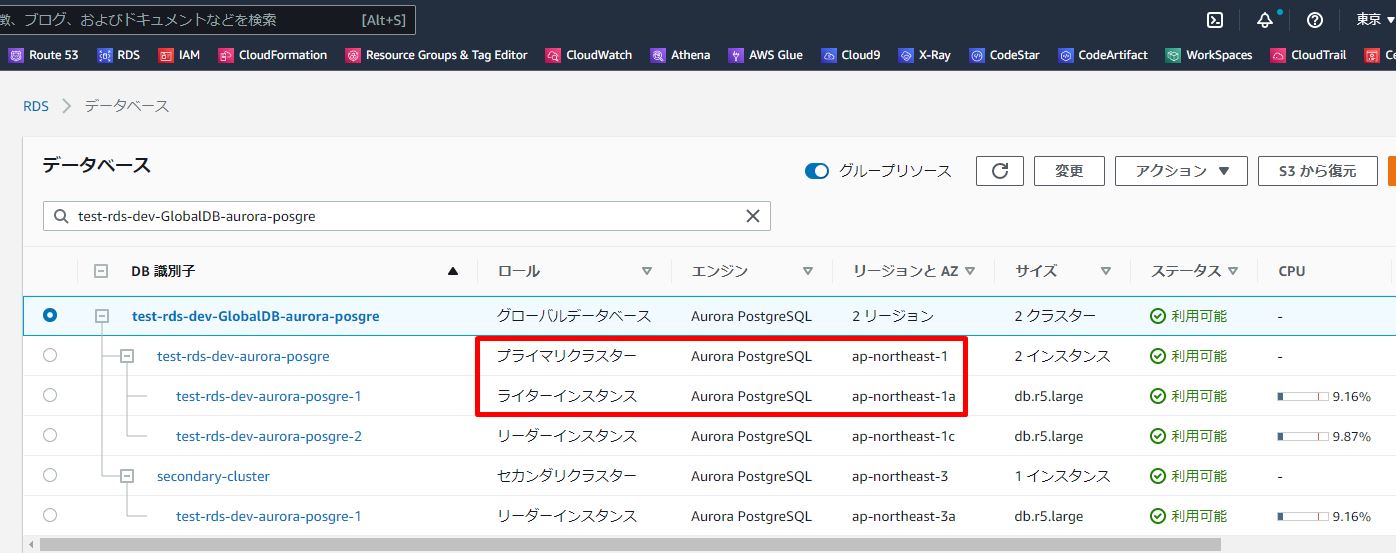
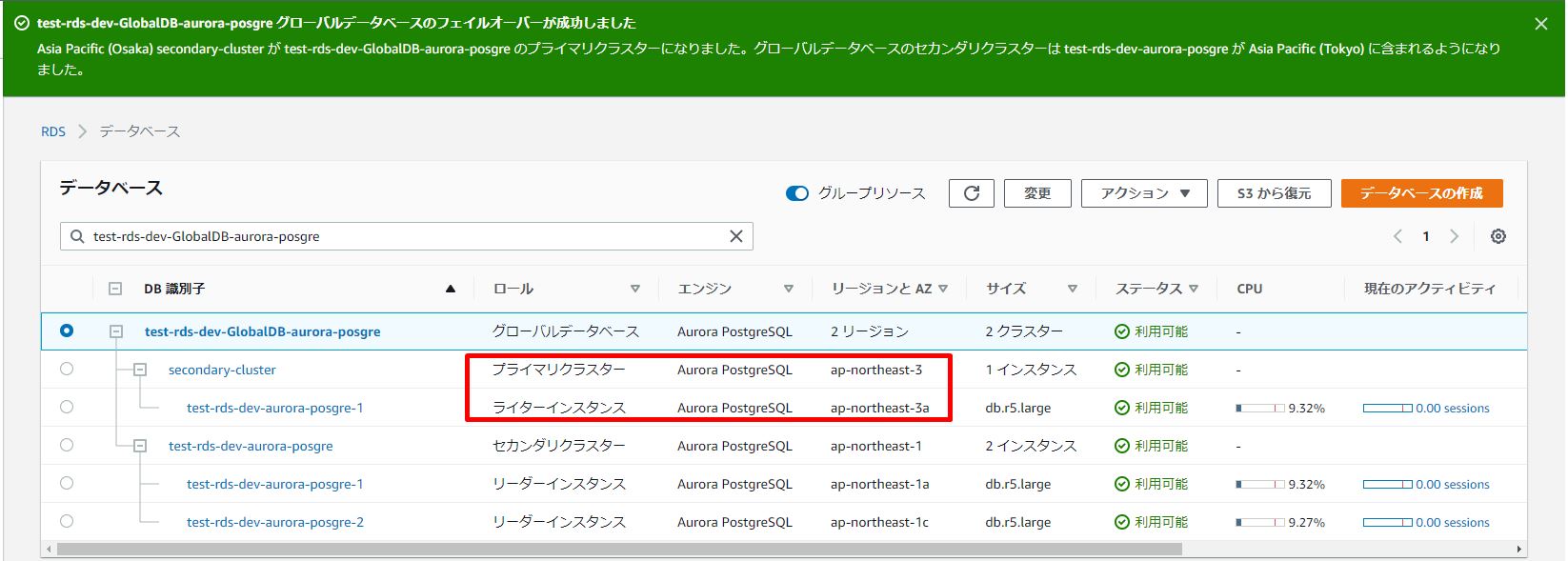
1.フェイルオーする前にプライマリクラスター及びライターインスタンスを確認します。
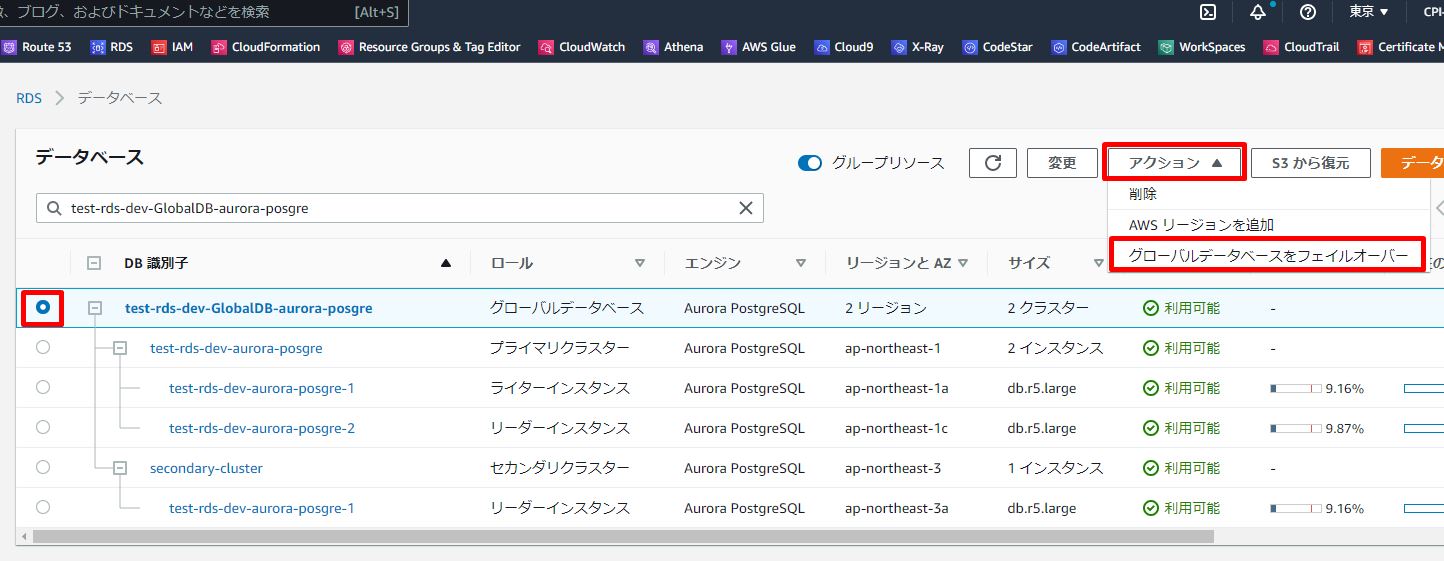
2.Aurora Global Database を選択し、[アクション] メニューから [グローバルデータベースをフェイルオーバー] を選択します。
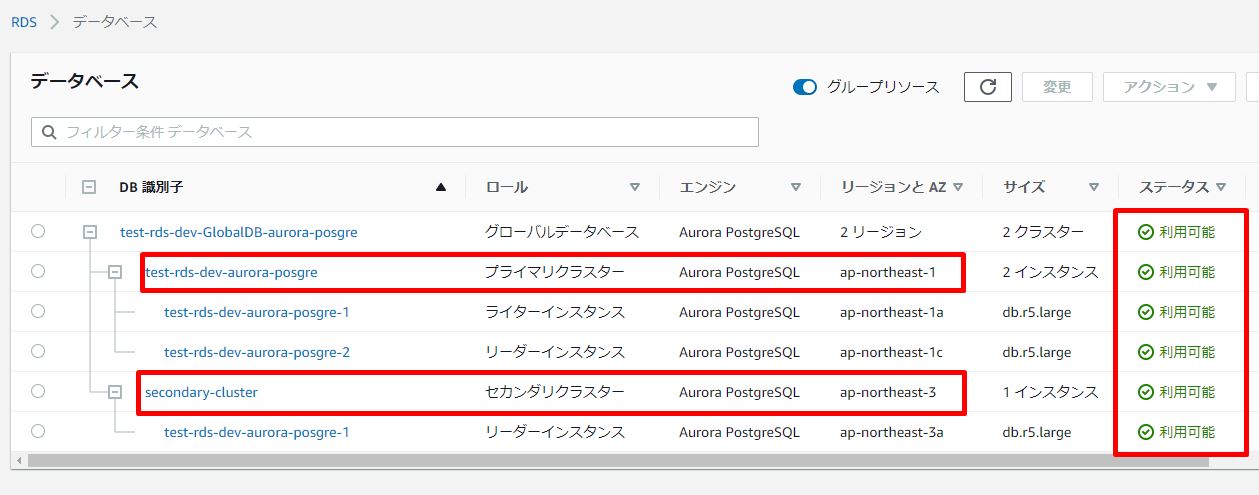
3.プライマリに昇格させたいセカンダリ Aurora DB クラスターを選択し、[グローバルデータベースをフェイルオーバー] をクリックします。
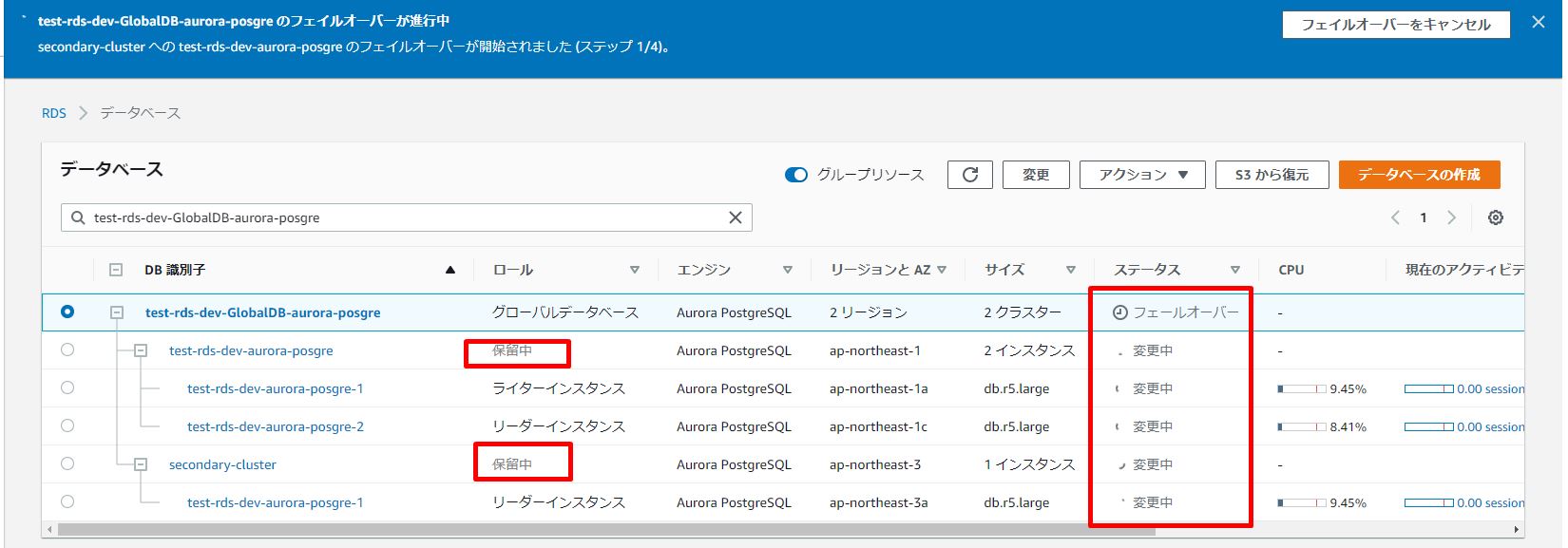
a.ステータス変更中
[Databases (データベース)] リストの [Status (ステータス)] 列には、フェイルオーバープロセス中の各 Aurora DB インスタンスと Aurora DB クラスターの状態が表示されます。
b.ステータス変更済み
[Databases (データベース)] リストの [Status (ステータス)] 列には、フェイルオーバープロセス中の各 Aurora DB インスタンスと Aurora DB クラスターの状態が[利用可能]になります。
AWS CLIの場合
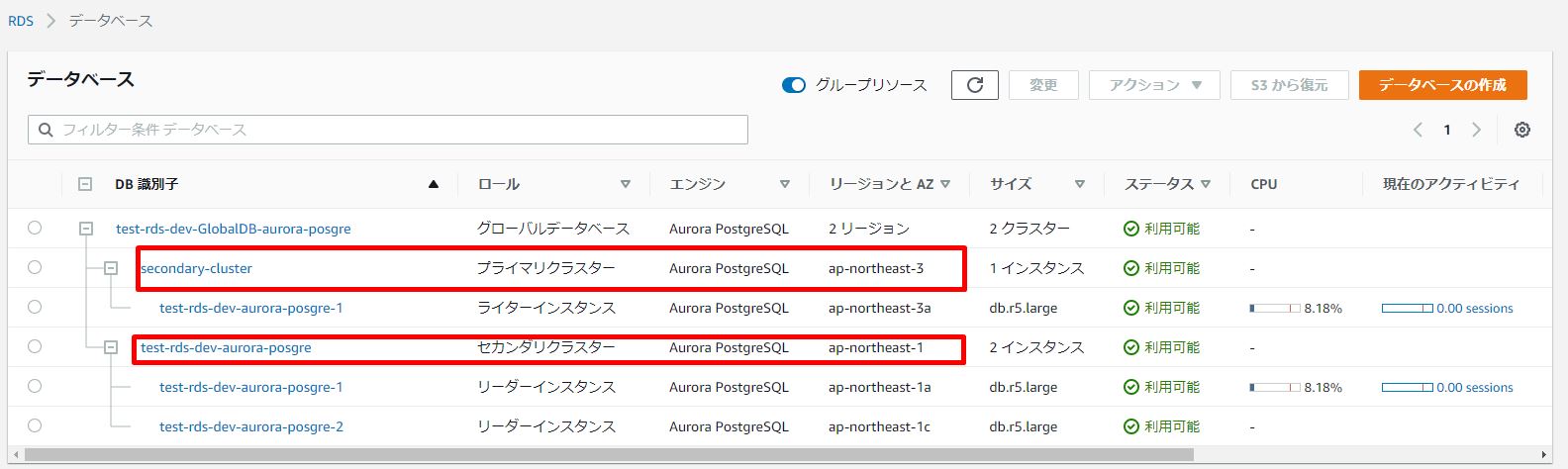
1.フェイルオーする前にプライマリクラスター及びライターインスタンスを確認します。
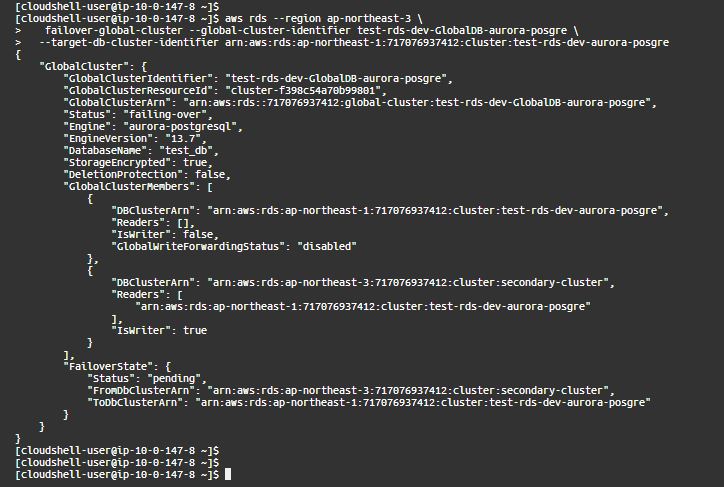
2.failover-global-cluster CLI コマンドを使用して、Aurora Global Database をフェイルオーバーします。
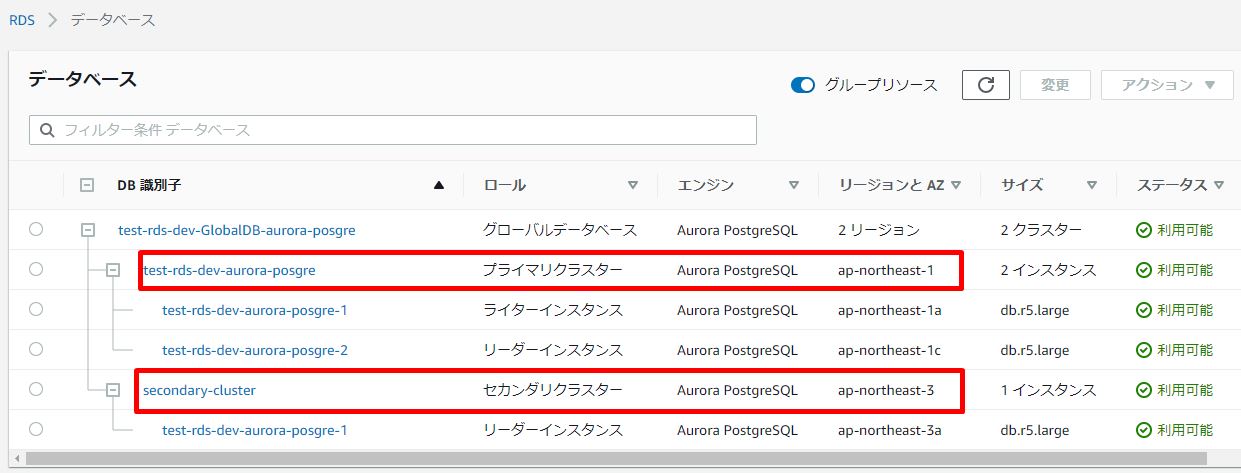
3.ステータスがが[利用可能]であることを確認します。
まとめ
前回の記事を続けて、グローバルDBのフィルオーバーを実施してみました。
注意点としては、フェイルオーバープロセスが完了すると、昇格された Aurora DB クラスターは Aurora Global Database の書き込み操作を処理できます。アプリケーションのエンドポイントを変更して、新しいエンドポイントを使用してください。