




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
こんにちは、きおかです。
現在オンライン英会話を受講しているのですが、教材が全てpdfであり少し使いにくいです。
なのでOCRでテキスト抽出したいと思い、AWSでOCRが使えるAmazon Textractというサービスを見つけたので試してみました。
Amazon Textractの使い方
非常にシンプルです。
まずAmazon Textractを開き、ナビゲーションメニューから一括ドキュメントアップローダーを選択します。
画面下部のドキュメントをアップロードを選択し、アップロード画面に遷移します。

今回はコンピュータからドキュメントをアップロードします。今回は1つのpdfファイルのみですが、複数アップロード可能です。料金については後述します。

アップロードすると自動的にS3バケットが作成されます。
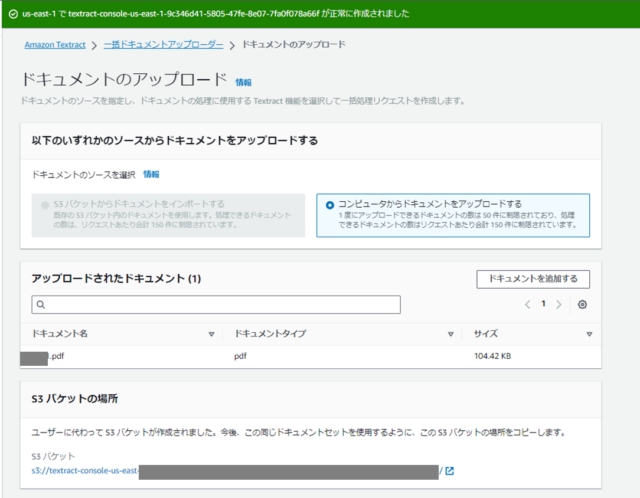
今回はテキスト抽出をしたいのでDetectDocumentText - OCRを選択し、作成します。

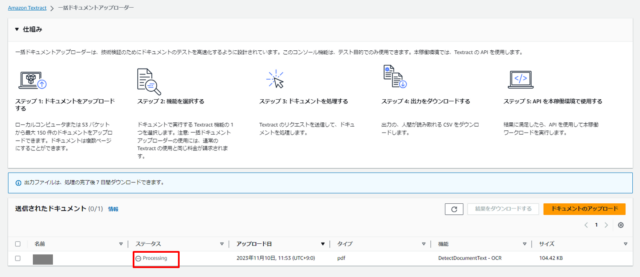
しばらくするとアップロードが完了し、Processingのステータスと共に表示されます。
Ready For Downloadと表示されたらダウンロードします。
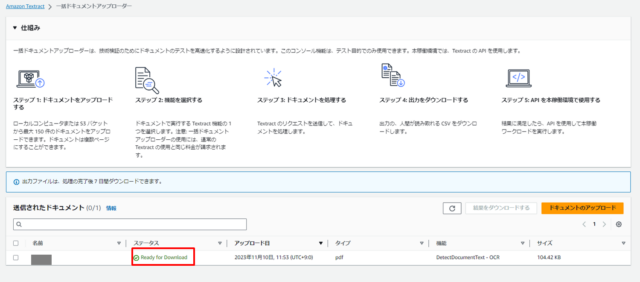
テキスト抽出ファイルだけでなく、OCRの精度やJSON形式でOCR抽出情報が入ったファイルも一緒にzipファイルでダウンロードされます。
XXX.zip
├─detectDocumentTextResponse.json
├─rawText.txt
└─rawText.csvきおかがそこまでOCRサービスを知らないのですが、一括でアップロードして処理してくれるのは強力だなと感じました。
料金
今回使ったDetect Document Text - OCRというサービスの、最初の3か月間有効な無料利用枠のみご紹介しておきます。
他の料金については、下記リンクから飛べます。
Detect Document Text API: 1,000 ページ/月
余談:Pythonでzipファイルから特定のファイルのみを取り出す方法
Amazon Textractと全く関係ないですが、最近OS周りの勉強もしてまして、少しずつプログラミング言語も使え始めてきたのでご紹介。
import zipfile
zipfile.ZipFile("zipファイルの相対パスまたは絶対パス", 'r').extract("取り出したいファイル名", "取り出したいファイルがあるディレクトリ")ちなみにbashシェルだとunzipでできるようです。
unzip -p "zipファイルの相対パスまたは絶対パス" "取り出したいファイル名" > "取り出したいファイル名"
chatGPTに聞いたところ、Powershellだとそう簡単にいかないようで、WindowsでやるならPythonがよさそうでした。
さいごに
簡単にAmazon Textractをご紹介してみました。
OCRなので何かややこしい設定がいるのかと思いきや、マネコン上でも使えるようになっていて感動しました。
これからも英会話は続けていくので、お世話になりそうです。
それではまた!