



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
今回は、scriptコマンドを利用して、コンソール上の操作(作業)ログを自動取得するシェルスクリプトの作成手順を紹介していきます。
■目的
操作ログを記録することで、予期せぬエラーが表示された場合やオペレーションミスが起こってしまった際の詳細な記録を残しておくことができます。
作業終了後に記録を見返し手順書などを修正することで、次回以降の作業を滞りなく進めることが出来ます。
■前提条件
-
PuTTYをインストールしていること。
RHEL9はOpenSSHに8.7p1バージョンを採用しており、RSA/SHA-1がデフォルトで非推奨になっており、Tera Termからログインできない為。 -
パブリックサブネットのあるVPCを作成していること。
-
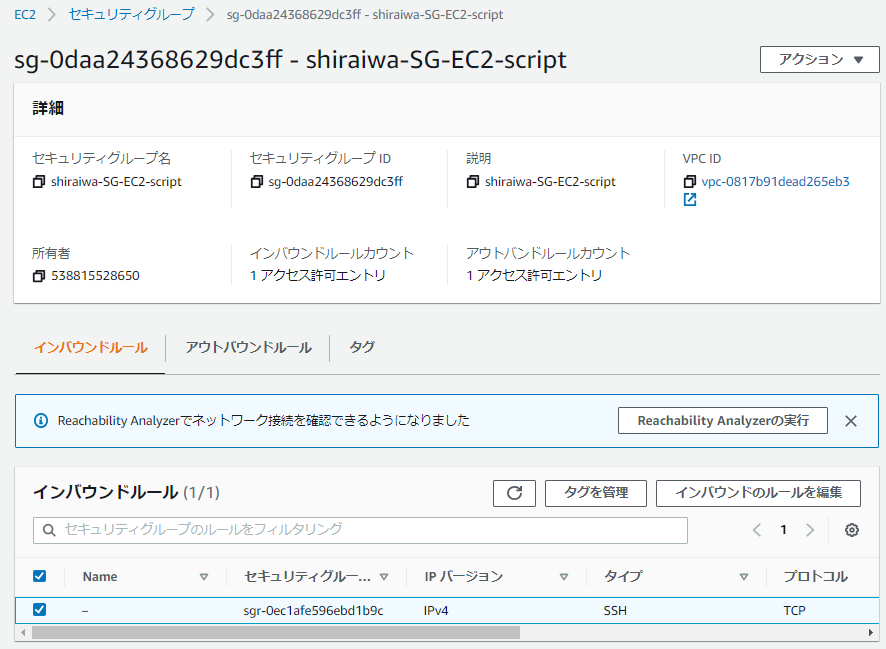
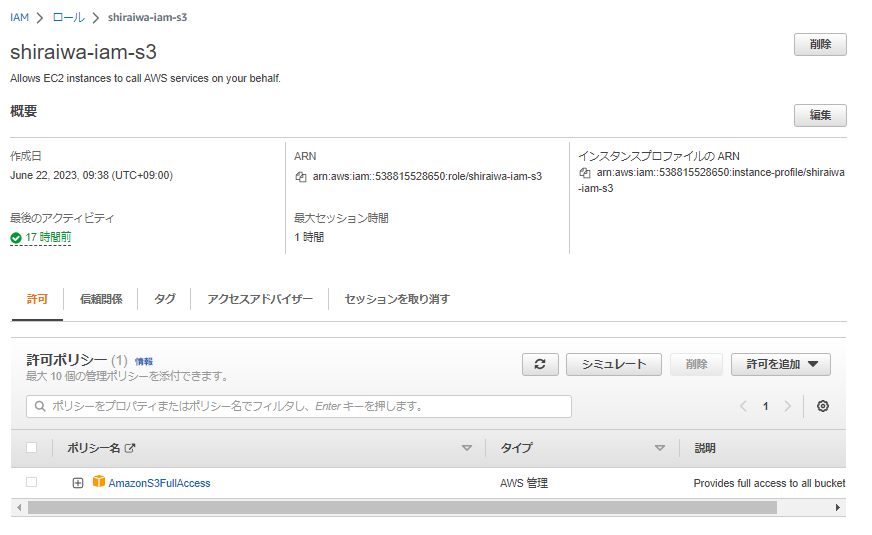
EC2に付与するSGとIAMロールを作成していること。
↓SG(SSH)
↓IAMロール(AmazonS3FullAccess)
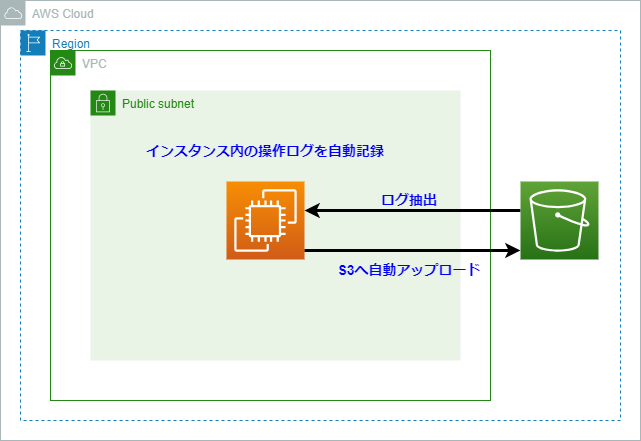
■構成図
■手順
1.S3バケット作成
まず初めにシェルスクリプトで取得した操作ログのバックアップ先となる、S3バケットを作成します。
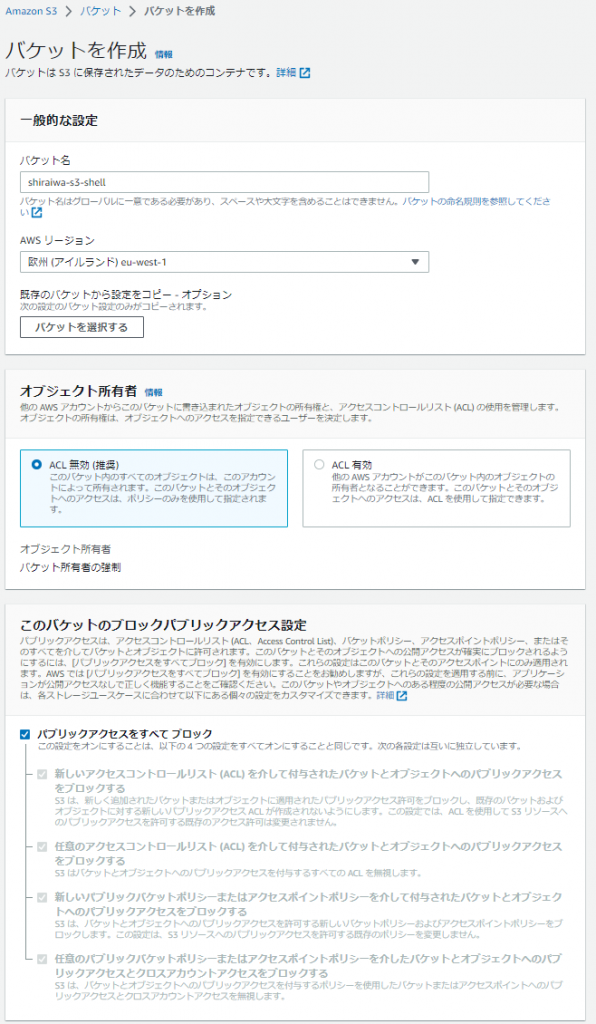
1.サービスからS3、サイドメニューからバケットを選択し、「バケットを作成」を押下します。
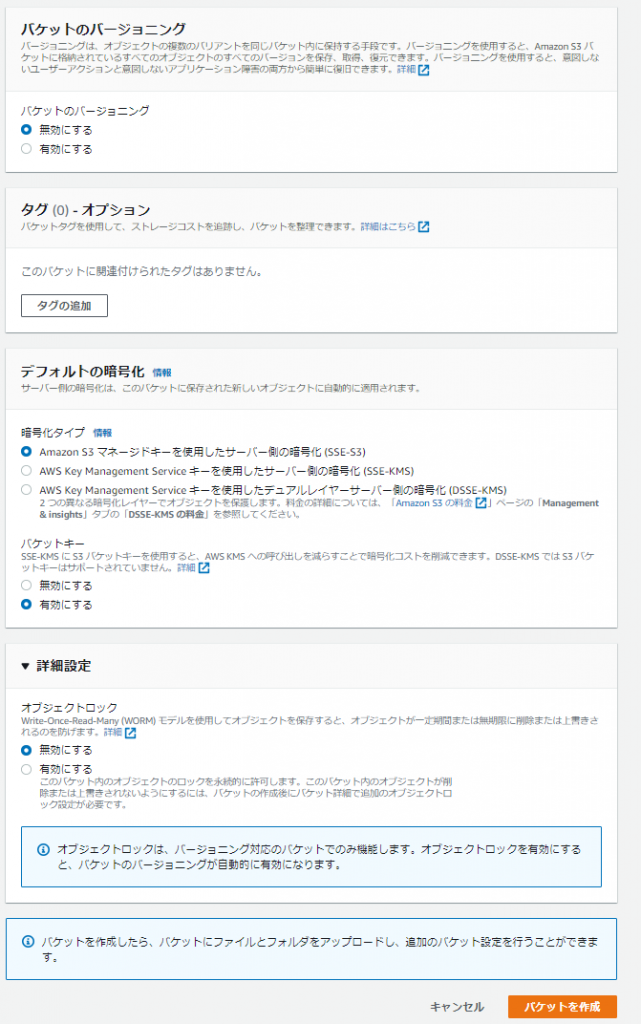
2.以下の設定値を入力します。
| 設定項目 | 入力値 | 備考 |
|---|---|---|
| バケット名 | 任意 | 大文字が使えず、バケット名は世界で一意である必要がある |
| リージョン | eu-west-1 | 遠隔に保管する必要がないのでVPCと同一のリージョンとします |
| オブジェクト所有者 | ACL無効 | 検証用で自身が利用する為 |
| パブリックアクセス制限 | すべてブロック | パブリックアクセスを行わない為 |
| バージョニング | 無効 | 要件がないのでコストを考慮し無効 |
| 暗号化キータイプ | SSE-S3 | 要件がないので、デフォルト値とします |
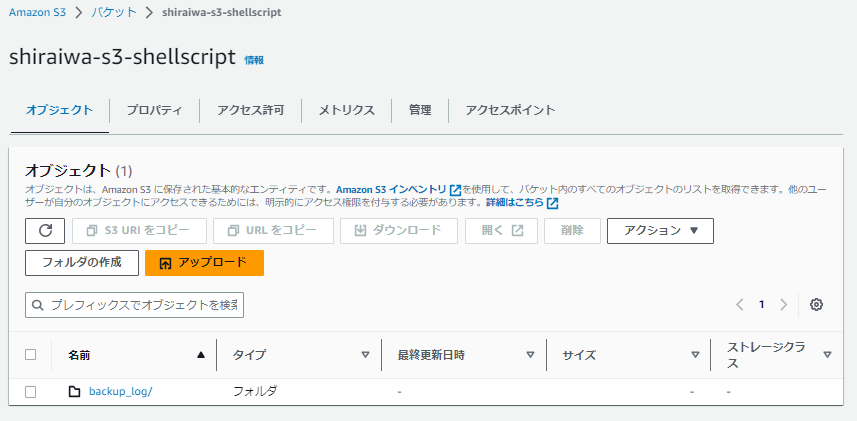
3.作成したS3バケット内に、backup_logフォルダを作成します。
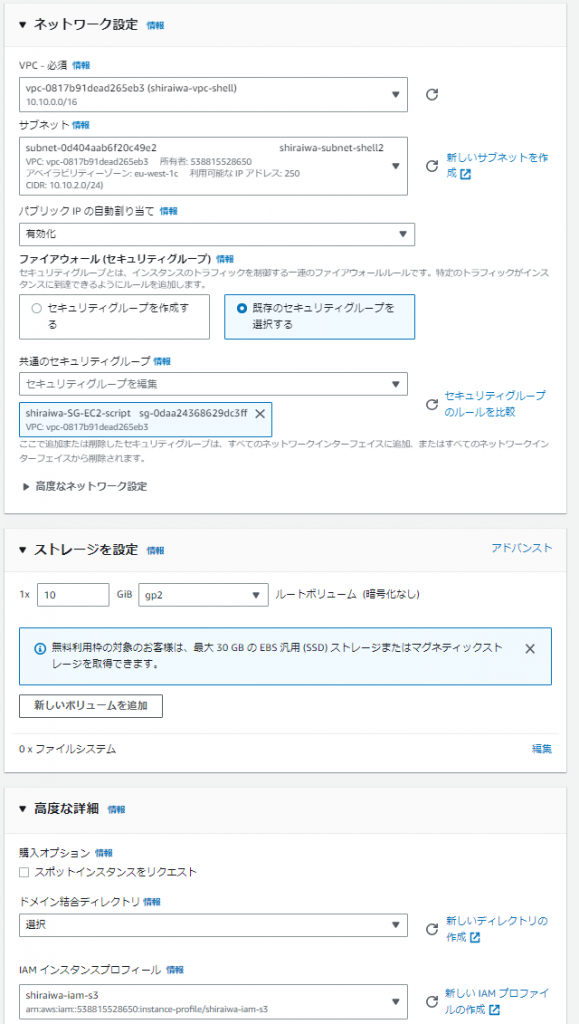
2.EC2インスタンスの作成
シェルスクリプトを実行し、コンソール上の操作ログを取得する為に、EC2を作成します。
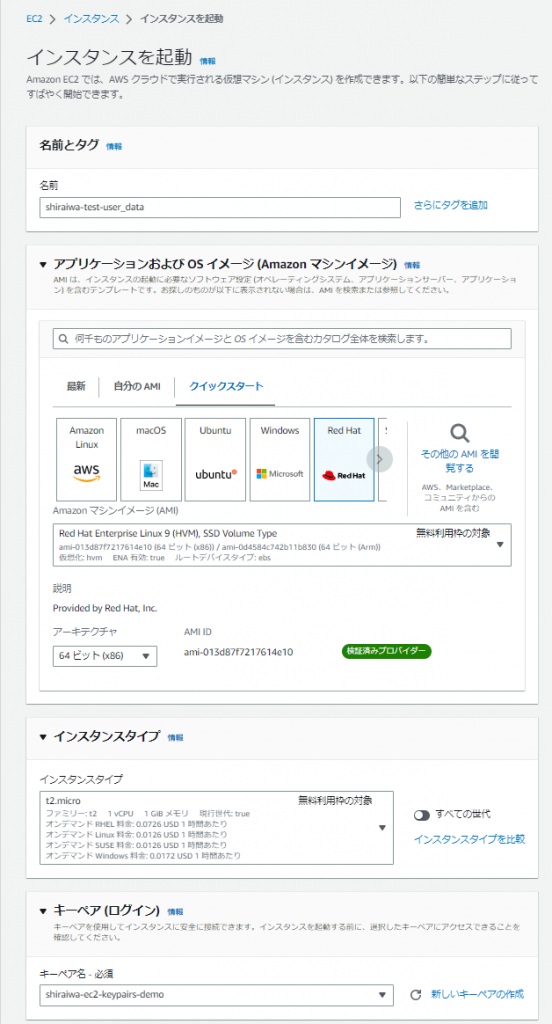
1.サービスからEC2、サイドメニューからインスタンスを選択し、「インスタンスを起動」を押下します。
2.以下の設定値を入力します。
| 設定項目 | 入力値 |
|---|---|
| 名前 | 任意 |
| OS | Red Hat |
| AMI | Red Hat Enterprise Linux 9 (HVM), SSD Volume Type(無料枠) |
| インスタンスタイプ | t2.micro(無料枠) |
| キーペア | 使用しているものを選択 |
| VPC | 事前に作成したもの |
| サブネット | 事前に作成したもの |
| パブリックIP | 有効化 |
| SG | 事前に作成したもの |
| IAMロール | 事前に作成したもの |
3.ユーザーデータに下記スクリプトを記入する。
ユーザーデータを設定することで、インスタンスを起動した段階で自動的に入力しておいたコマンドが実行されます。
※本来はインスタンス起動後に、コンソールからコマンド入力するので、その手間が省けます。

#!/bin/bash
sudo yum install python -y
sudo dnf install -y wget
sudo wget https://bootstrap.pypa.io/get-pip.py
python get-pip.py
sudo curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
sudo yum install zip unzip -y
unzip awscliv2.zip
sudo ./aws/install
source ~/.bash_profile
mkdir /home/ec2-user/temp_folder
mkdir /home/ec2-user/ope_log_folder
sudo chown -R ec2-user /home/ec2-user
sudo chgrp -R ec2-user /home/ec2-user- 1行目
#!/bin/bash
ユーザーデータのシェルスクリプトは、#! の記号と、スクリプトを読み取るインタープリタのパス (通常は /bin/bash) から始める必要があります
起動時に Linux インスタンスでコマンドを実行するより引用
-
2行目
sudo yum install python -y
Pythonのインストールコマンドです。
PythonはAWS CLIの実行に必要なランタイム環境です。
ランタイム環境とは特定のプログラムやアプリケーションを実行する為に必要な実行環境のことです。
プログラムやスクリプトを正常に実行する為には必須となる。 -
3行目
sudo dnf install -y wget
wgetのインストールコマンドです。
Web上からファイルを取得する機能を持つフリーソフトウェアです。
以降で、Web上からファイルを取得する際に必要となる。 -
4~5行目
sudo wget https://bootstrap.pypa.io/get-pip.py
python get-pip.py
pipのインストールコマンドです。
pipはPythonのパッケージ管理システムであり、AWS CLIをインストールする為に利用します。 -
6行目
sudo curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
AWS CLI(Ver2)のインストールファイルをダウンロードするコマンドです。 -
7行目
sudo yum install zip unzip -y
unzipのインストールコマンドです。
6行目でインストールしたzipファイルを解凍する為に利用します。 -
8行目
unzip awscliv2.zip
6行目でインストールしたawscliv2.zipファイルを解凍するコマンドです。 -
9行目
sudo ./aws/install
インストールプログラムを実行するコマンドです。 -
10行目
source ~/.bash_profile
.bash_profileの変更内容を即座に反映させるコマンドです。
変更内容が反映されないと、AWS CLIが利用できません。 -
11行目
mkdir /home/ec2-user/temp_folder
/home/ec2-user配下に、temp_folder(フォルダ)を作成するコマンドです。
S3バケットから操作ログを一時的にダウンロードする際に使用するフォルダーとなります。 -
12行目
mkdir /home/ec2-user/ope_log_folder
/home/ec2-user配下にope_log_folder(フォルダ)を作成するコマンドです。
起動時に作成される操作ログを一か所に格納する為のフォルダーとなります。 -
13~14行目
sudo chown -R ec2-user /home/ec2-user
sudo chgrp -R ec2-user /home/ec2-user
11~12行目で作成したフォルダのユーザーとグループ権限をec2-userに変更する。
3.scriptコマンドとは
scriptコマンドは、Linuxで実行したコマンドと実行日時、出力結果を全てログファイルに記録することが可能です。
実際にscriptコマンドを実施し、記録内容をcatコマンドで確認したものが下の画像となります。
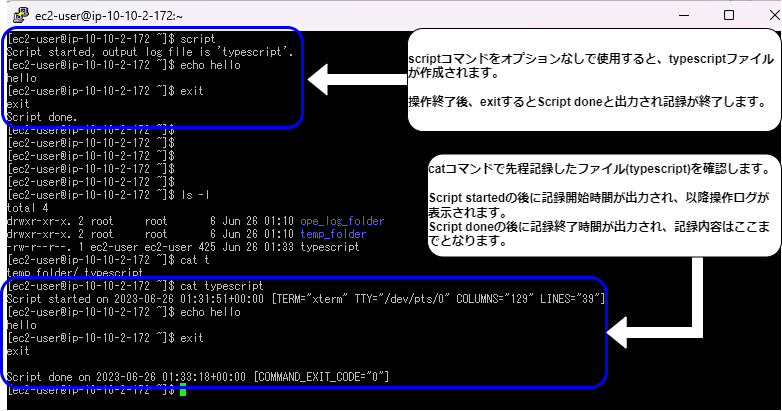
操作ログを記録することで、予期せぬエラーが表示された場合やオペレーションミスが起こってしまった際の詳細な記録を残しておくことができます。
作業終了後に記録を見返し手順書などを修正することで、次回以降の作業を滞りなく進めることが出来ます。
しかし現状の仕様では、作業者がscriptコマンドを実行し忘れる可能性があるため、インスタンスへログインした際に自動で実行されるようにしていきます。
4.ログイン時に、scriptコマンドを自動実行させる
ログイン時に実行される設定用のシェルスクリプトである.bash_profileに、scriptコマンドを追記します。
.bash_profileはログイン時だけ実行されるシェルスクリプトなので、この設定ファイルにscriptコマンドを追記することで、インスタンスにログインした際にコマンドが自動実行されます。
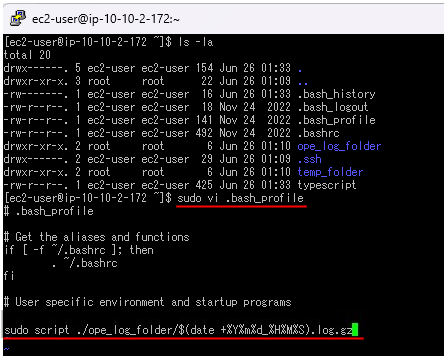
1.ホームディレクトリで、ls -laコマンドを実行し、.bash_profileがあることを確認します。
2.確認後、sudo vi .bash_profileで設定ファイルを開き編集します。
3.ファイルの末尾にscript ./ope_log_folder/$(date +%Y%m%d_%H%M%S).log.gzと追記します。
※追記したコマンドの内容
ホームディレクトリ配下のope_log_folder(フォルダー)へ、ログイン時の日時が記載されたファイルが作成される。
例)20230622_002814.log.gz
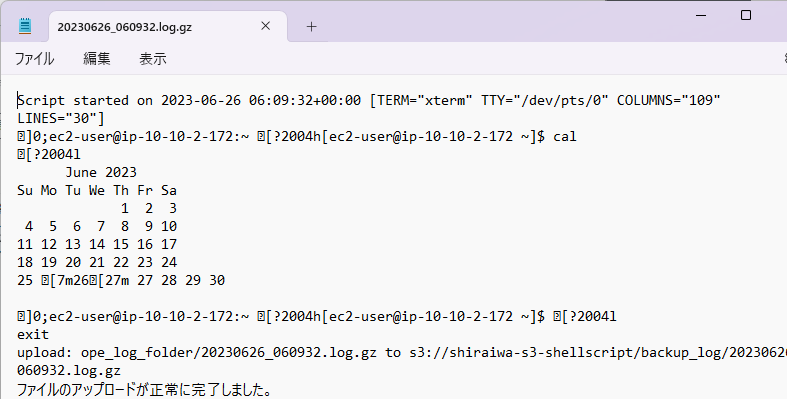
5.scriptコマンドが自動化されていることを確認
実際に項番4で追記した内容が反映されているか一度ログアウトし、再度ログインします。
正常に動作すると、下の画像のようなコメントが表示されます。
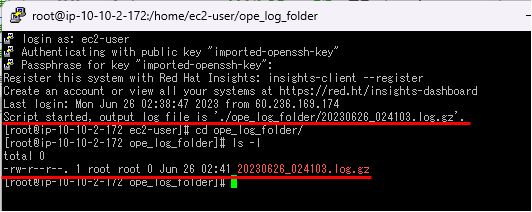
scriptコマンドの自動実行の確認が出来きました。
ls -lコマンドでも、対象のファイルが保存されていることが確認できました。
次はログアウトする際に、S3バケットへログのアップロードを自動化します。
6.ログアウト時のS3バケットへのログのアップロード自動化
まず初めに、S3バケットへのログのアップロードのシェルスクリプト(s3_upload.sh)を作成していきます。
1.ホームディレクトリに移動し、sudo vi s3_upload.shでシェルスクリプトを作成・編集します。
記載内容は以下の通りです。
#!/bin/bash
export PATH=/usr/local/aws-cli/v2/current/bin:$PATH
folder="/home/ec2-user/ope_log_folder"
bucket="項番1で作成したS3バケット名"
s3_folder="backup_log"
latest_file=$(ls -1t "$folder" | head -n 1)
aws s3 cp "$folder/$latest_file" "s3://$bucket/$s3_folder/$latest_file"
result=$?
if [ $result -eq 0 ]; then
echo "ファイルのアップロードが正常に完了しました。"
else
echo "ファイルのアップロード中にエラーが発生しました。エラーコード: $result"
fi-
1行目
#!/bin/bash
ユーザーデータでの説明と同じです。 -
2行目
export PATH=/usr/local/aws-cli/v2/current/bin:$PATH
シェルスクリプトで環境変数 PATH を変更しています。
これにより、AWS CLIのVer2がインストールされている場所を PATH に含めることができ、AWS CLIのコマンドをシェルスクリプトから直接実行できるようになります。 -
3行目
folder="/home/ec2-user/ope_log_folder"
folder(変数)へ、操作ログを保管しているフォルダを指定します。 -
4~5行目
bucket="項番1で作成したS3バケット名"
s3_folder="backup_log"
bucket(変数)へ、項番1で作成したS3バケット名を指定します。
例)bucket="shiraiwa-s3-shellscript"
s3_folder(変数)へ、バックアップ先として作成したフォルダ(backup_log)を指定します。 -
6行目
latest_file=$(ls -1t "$folder" | head -n 1)
latest_file(変数)変数へ、3で指定したファイル内の最新日付を持つファイルを指定します。
ls -1t "$folder"でフォルダ内のファイルが更新日時の新しい順にソートされます。
|でls -1t "$folder"の実行結果をhead -n 1に渡します。
head -n 1で指定されたファイルの最初の行(最新日付を持つファイル)を表示します。 -
7行目
aws s3 cp "$folder/$latest_file" "s3://$bucket/$s3_folder/$latest_file"
awsコマンドで、最新日時のファイルを指定したS3バケット内のフォルダへアップロードします。 -
8~13行目
result=$?
if [ $result -eq 0 ]; then
echo "ファイルのアップロードが正常に完了しました。"
else
echo "ファイルのアップロード中にエラーが発生しました。エラーコード: $result"
fi
アップロードの結果を出力します。
2.作成後、sudo chmod +x s3_upload.shでスクリプトに実行権限を与えます。
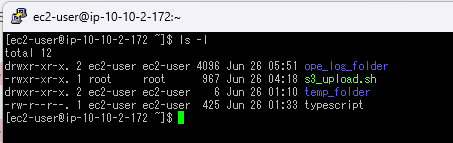
3.ホームディレクトリでls -laコマンドを実行し、.bashrcファイルがあることを確認します。
※.bashrcは、bashを使用する際に必要な設定が記載されているファイルになります。
4.sudo vi .bashrcでファイルを開き、ファイル末尾にtrap "/home/ec2-user/s3_upload.sh" exitと追記します。
追記することで、ログアウトをトリガーとしs3_upload.shを実行します。
コンソール上でexit又はctrl dでログアウトする際に追記したスクリプトが実行されます。
※ログアウト前にスクリプトが実行され、自動アップロードすることで操作ログの取り忘れを防げます。
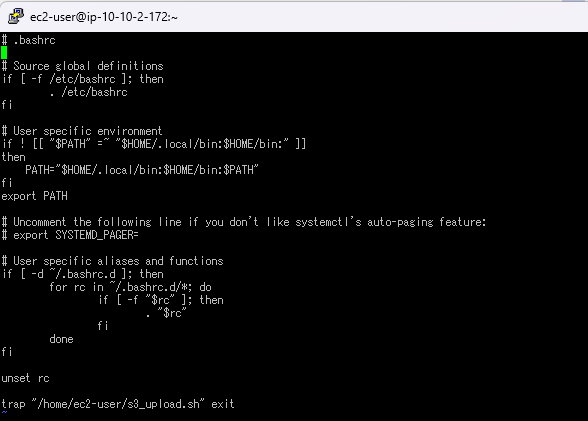
7.S3バケットへのアップロードが自動化されていることを確認
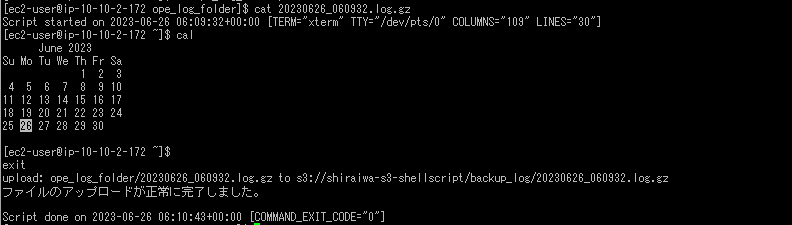
実際にexit又はctrl dでログアウトしようとすると、下の画像のように「ファイルのアップロードが正常に完了しました」と出力されていればS3バケットへアップロードされています。
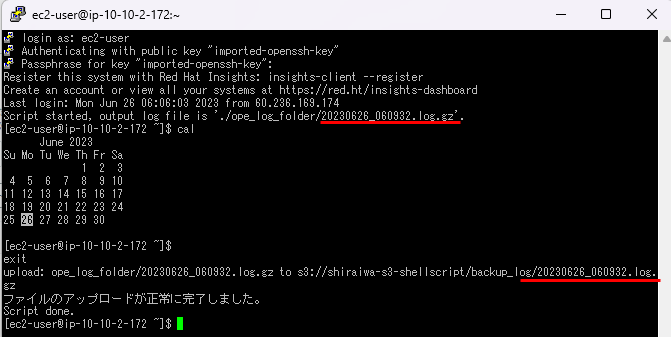
マネジメントコンソールで、指定したS3バケット内のbackup_logフォルダを確認してみると、アップロードされたファイルと同じ名前のファイルがありました。
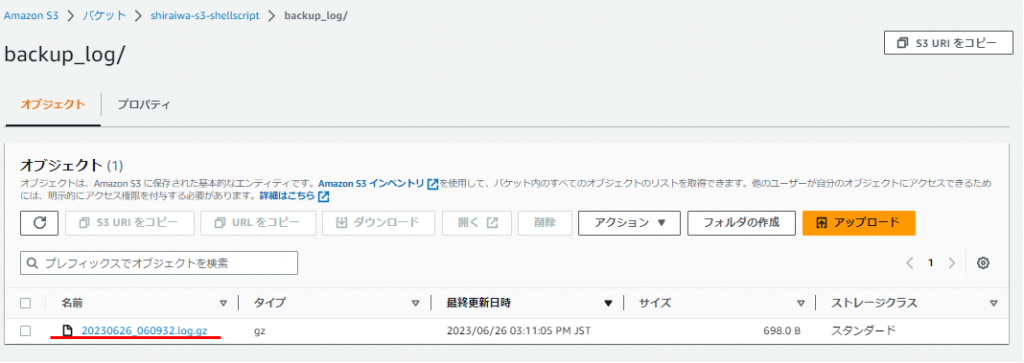
対象のファイルをS3バケットからダウンロードし、メモ帳などで開いて中身を比較すると内容が同じであることが分かったので、正常にアップロードできていることが確認できました。
※少し文字化けしていますが、操作ログの開始・終了時間、実行コマンド・実行結果が全て同じです。
8.S3バケットにバックアップしている複数のファイルからログ抽出を実施
シェルスクリプトの引数で日時と文字列を指定し、S3バケットのバックアップフォルダから、対象のログを抽出します。
1.ホームディレクトリに移動しsudo vi log_xtraction.shでシェルスクリプトを作成します。
記載内容は以下の通りです。
#!/bin/bash
export PATH=/usr/local/aws-cli/v2/current/bin:$PATH
file_name="$1"
search_string="$2"
bucket="項番1で作成したS3バケット名/backup_log"
temp_dir="/home/ec2-user/temp_folder"
aws s3 sync s3://$bucket $temp_dir --exclude "*" --include "*$file_name*"
files=$(find $temp_dir -type f)
PS3="ファイルを選択してください: "
select file in $files; do
if [[ -n $file ]]; then
echo "選択されたファイル: $file"
if grep -q "$search_string" "$file"; then
sed -n "/$search_string/{N;N;p;}" "$file"
else
echo "指定の文字列はファイル内に含まれていません"
fi
break
else
echo "無効な選択です。再度選択してください。"
fi
done
rm -rf $temp_dir/*-
1~2行目
#!/bin/bash
export PATH=/usr/local/aws-cli/v2/current/bin:$PATH
s3_upload.shを作成時の説明と同じです。 -
3~4行目
file_name="$1"
search_string="$2"
file_name(変数)へ、ログ抽出を行いたいファイル名(第一引数)を指定します。
search_string(変数)へ、抽出したい文字列(第二引数)を指定します。 -
5行目
bucket="項番1で作成したS3バケット名/backup_log"
bucket(変数)へ、項番1で作成したS3バケット名とbackup_logフォルダを指定します。
例)bucket="shiraiwa-s3-shellscript/backup_log" -
6行目
temp_dir="/home/ec2-user/temp_folder"
temp_dir(変数)へ、バックアップからの一時保管先としてtemp_folderフォルダを指定します。 -
7行目
aws s3 sync s3://$bucket $temp_dir --exclude "*" --include "*$file_name*"
awsコマンドで、backup_logフォルダ(同期元)から第一引数を含むファイルをtemp_folderフォルダ(同期先)に同期します。 -
8行目
files=$(find $temp_dir -type f)
findコマンドで、temp_dir配下のファイルを検索します。 -
9行目
PS3="ファイルを選択してください: "
この変数の値はselect文のプロンプトとして使われます。 -
10行目
select file in $files; do
select文を使用すると、簡易的な対話メニューをプロンプトに表示させることができます。 -
11~12行目と19~21行目
if [[ -n $file ]]; then
echo "選択されたファイル: $file"
else
echo "無効な選択です。再度選択してください。"
fi
fileが存在するかどうかを確認し、存在する場合は選択されたファイルが表示され、13行目のif分が実行されます。
存在しない場合は、無効な選択と表示され、指定されたファイルから再度選択するよう表示されます。 -
13~16行目
if grep -q "$search_string" "$file"; then
sed -n "/$search_string/{N;N;p;}" "$file"
else
echo "指定の文字列はファイル内に含まれていません"
fi
break
指定したファイル内に第二引数で指定した文字列がある場合、指定した文字列を含むその次の2行が出力されます。
文字列がない場合は、文字列が含まれていないことを表示し、breakでselect文から抜けます。 -
22行目
done
done は対応する制御構造のブロックの終了を示し、ループの条件式の評価に戻ることを意味します。
select文がループ処理を行っていました。 -
23行目
rm -rf $temp_dir/*
temp_dir配下のファイルをすべて消去します。
2.sudo chmod +x log_xtraction.shで、実行権限を与えます。
9.ope_log_folderフォルダとログ抽出した内容が同じか確認
1.事前にecho scriptコマンドを実施した操作ログをS3バケットへアップロードします。
※実行するコマンドは分かりやすいものであれば、何でも大丈夫です。
2.sudo ./log_xtraction.sh 第二引数 第二引数を実行します。
例)sudo ./log_xtraction.sh 20230626 echo
※第一引数と第二引数へ入れる値は、項番9-1で実施したコマンドとアップロードしたファイル名により異なります。
3.cd ope_log_folder/で移動し、cat 20230626_075455.log.gzを実行し、内容を比較します。
出力した内容が一致しているため、ログ抽出が出来ていることが確認できました。
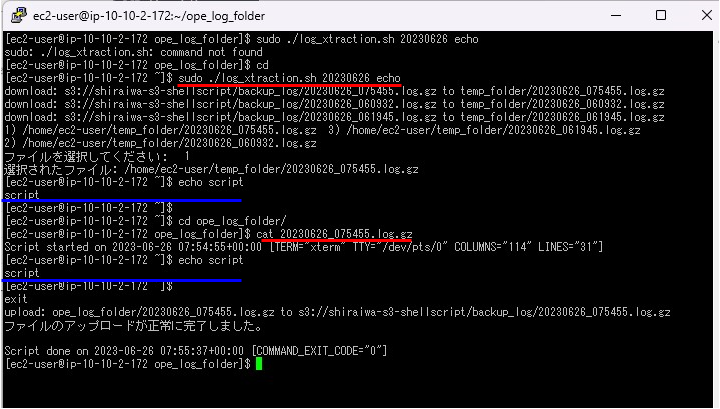
まとめ
今回は設定ファイルである.bash_profileと.bashrcにコマンドを追記してS3バケットへアップロードやscriptコマンドの自動化を行いました。
各設定ファイルを使いこなすことで、出来ることが増えてきそうですね。
それぞれ設定ファイルの違いをまとめたのでご参考までに。
| ファイル | 概要 |
|---|---|
| ~/.bash_profile | ログイン時のみ読み込ませたい設定 |
| ~/.bashrc | bash起動の度に読み込ませたい設定 |
| ~/.bash_logout | ログアウント時に読み込ませたい設定 |
| ~/.bash_history | 実行したコマンドの履歴を記録するファイル |