




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
以前RDSを停止するのを忘れていたため、RDS自動停止機能を実装しました。
EventBridgeとLambda関数(Boto3)を使って指定時間に起動中のRDSリソース(RDSインスタンス,RDSクラスター)自動停止機能を構築していきます。
Lambdaとは
AWS Lambda は、サーバーをプロビジョニングまたは管理せずにコードを実行できるようにするコンピューティングサービスです。Lambda は可用性の高いコンピューティングインフラストラクチャでコードを実行し、コンピューティングリソースに関するすべての管理を行います。これには、サーバーおよびオペレーティングシステムのメンテナンス、容量のプロビジョニングおよび自動スケーリング、さらにログ記録などが含まれます。Lambda を使用すると、実質どのようなタイプのアプリケーションやバックエンドサービスに対してもコードを実行できます。必要なのは、Lambda がサポートするいずれかの言語でコードを指定することだけです。
引用:AWS Lambda
Boto3とは
AWS SDK for Python (Boto3) を使用すると、AWS の使用を迅速に開始できます。Boto3 を使用することで、Python のアプリケーション、ライブラリ、スクリプトを AWS の各種サービス(Amazon S3、Amazon EC2、Amazon DynamoDB など)と容易に統合できます。
EventBridgeとは
EventBridge は、イベントを使用してアプリケーションコンポーネントを接続するサーバーレスサービスです。これにより、スケーラブルなイベント駆動型アプリケーションを簡単に構築できます。これを使用して、自社開発アプリケーション、AWS サービス、サードパーティソフトウェアなどのソースから組織全体のコンシューマアプリケーションにイベントをルーティングできます。EventBridge では、イベントの取り込み、フィルタリング、変換、配信をシンプルかつ一貫性のある方法で行うことができるため、新しいアプリケーションをすばやく構築できます。
RDSクラスターとは
あるマルチ AZ DB クラスターの配置は、2 つの読み取り可能なスタンバイ DB インスタンスを持つ Amazon RDS の高可用性の配置モードです。マルチ AZ DB クラスターには、同じAWSのリージョンに 3 つの別々のアベイラビリティーゾーンに 1 つのライター DB インスタンスと 2 つのリーダー DB インスタンスがあります。マルチ AZ DB クラスターは、マルチ AZ DB インスタンスの配置と比較して、高可用性、読み取りワークロードの容量の増加、および書き込みレイテンシーの低減を提供します。
RDSインスタンスとは
DB インスタンスはクラウドで実行される独立したデータベース環境です。これは、Amazon RDS の基本的な構成要素です。DB インスタンスには、ユーザーが作成した複数のデータベースを含めることができ、スタンドアロンデータベースインスタンスにアクセスする場合と同じクライアントツールやアプリケーションを使用してアクセスできます。
LambdaでRDS自動停止を作成
構成図
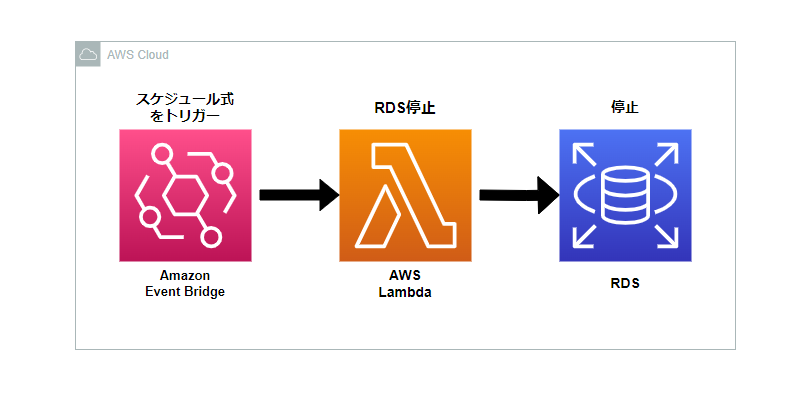
Lambdaの作成
Lambda関数の全体のソースコードです。
# coding:utf-8
import json
import boto3
def rds_db_instance_all_region_stop(region):
"""
regionを受け取り、全リージョンにあるRDSインスタンスを停止させ、、
停止していないなら現在の状態を出力する。
"""
rds = boto3.client('rds', region_name=region)
all_db_instance = rds.describe_db_instances().get('DBInstances')
for each_db_instance in all_db_instance:
db_instance_identifier = each_db_instance['DBInstanceIdentifier']
db_instance_status = each_db_instance['DBInstanceStatus']
if db_instance_status == "available":
rds.stop_db_instance(DBInstanceIdentifier=db_instance_identifier)
print(f"RDS DBInstanceを停止しました。 InstanceID:{db_instance_identifier}")
else:
print(f"{db_instance_identifier} のインスタンスの状態は {db_instance_status} です")
def rds_db_cluster_all_region_stop(region):
"""
regionを受け取り、全リージョンにあるRDSクラスターを停止させ、、
停止していないなら現在の状態を出力する。
"""
rds = boto3.client('rds', region_name=region)
all_db_cluster = rds.describe_db_clusters().get('DBClusters')
for each_db_cluster in all_db_cluster:
db_cluster_identifier = each_db_cluster['DBClusterIdentifier']
db_cluster_status = each_db_cluster['Status']
if db_cluster_status == "available":
print(f"RDS DBClusterを停止しました。 ClusterID:{db_cluster_identifier}")
rds.stop_db_cluster(DBClusterIdentifier=db_cluster_identifier)
else:
print(f"{db_cluster_identifier} インスタンスの状態は{db_cluster_status} です")
def lambda_handler(event, context):
ec2 = boto3.client('ec2')
regions = list(map(lambda x: x['RegionName'], ec2.describe_regions()['Regions']))
for region in regions:
rds_db_cluster_all_region_stop(region)
rds_db_instance_all_region_stop(region)
print("-------Proccessing complete!----------")関数def rds_db_instance_all_region_stopの説明
初めにdef rds_db_instance_all_region_stopの説明をしたいと思います。
regionを受け取り、全リージョンにあるインスタンスを停止させ、
停止してないなら現在の状態を出力しています。
関数のソースコードの下に詳しく書いてありますので参照ください。
def rds_db_instance_all_region_stop(region):
rds = boto3.client('rds', region_name=region)
all_db_instance = rds.describe_db_instances().get('DBInstances')
for each_db_instance in all_db_instance:
db_instance_identifier = each_db_instance['DBInstanceIdentifier']
db_instance_status = each_db_instance['DBInstanceStatus']
if db_instance_status == "available":
rds.stop_db_instance(DBInstanceIdentifier=db_instance_identifier)
print(f"RDS DBInstanceを停止しました。 InstanceID:{db_instance_identifier}")
else:
print(f"{db_instance_identifier} のインスタンスの状態は {db_instance_status} です")
- 1行目
def rds_db_instance_all_region_all_stop(region):は
関数を定義し、regionを受け取ります。 - 2行目
rds = boto3.client('rds', region_name=region)は
使いたいサービスの名前を文字列で渡してあげています。今回はRDSなので'rds'を渡しています。
region_nameは引数で設定した、regionを受け取ります。 - 3行目
all_db_instance = rds.describe_db_instances().get('DBInstances')は
describe_db_instancesで取得した結果(json)の中にあるDBInstancesを.get('DBInstances')を使って取り出し、all_db_instanceに代入しています。 - 4行目
for each_db_instance in all_db_instance:はall_db_instanceをeach_db_instanceに入れてfor文を実行しています。 - 5行目~6行目
db_instance_identifier = each_db_instance['DBInstanceIdentifier']
db_instance_status = each_db_instance['DBInstanceStatus']
は共にall_db_instanceが代入されたeach_db_instanceを使って、DBInstanceIdentifierとDBInstanceStatusを取得しています。
DBInstanceIdentifierはRDSのリソース名で、DBInstanceStatusはインスタンスの状態を示しています。 - それ以下の行
if db_instance_status == "available": rds.stop_db_instance(DBInstanceIdentifier=db_instance_indentifier) print(f"RDS DBInstanceを停止しました。 InstanceID:{db_instance_identifier}") else: print(f"{db_instance_identifier} のインスタンスの状態は {db_instance_status} です")はif文でavailableかそれ以外かを判別しています。
もしavailableだったらavailableのRDSインスタンスを停止します。
availableではなかった場合はインスタンス名と現在の状態を出力しています。
関数rds_db_cluster_all_region_stopの説明
次にrds_db_cluster_all_region_stopの説明をしたいと思います。
こちらも同様にregionを受け取り、全リージョンにあるクラスターを停止させ、
停止してないなら現在の状態を出力しています。
同様に関数のソースコードの下に詳しく書いてありますので参照ください。
def rds_db_cluster_all_region_stop(region):
rds = boto3.client('rds', region_name=region)
all_db_cluster = rds.describe_db_clusters().get('DBClusters')
for each_db_cluster in all_db_cluster:
db_cluster_identifier = each_db_cluster['DBClusterIdentifier']
db_cluster_status = each_db_cluster['Status']
if db_cluster_status == "available":
print(f"RDS DBClusterを停止しました。 ClusterID:{db_cluster_identifier}")
rds.stop_db_cluster(DBClusterIdentifier=db_cluster_identifier)
else:
print(f"{db_cluster_identifier} インスタンスの状態は{db_cluster_status} です")- 1行目
def rds_db_cluster_all_region_stop(region):は
関数を定義し、regionを引数として指定しています。 - 2行目
rds = boto3.client('rds', region_name=region)は
先ほどと同じように、使いたいサービスの名前を文字列で渡してあげています。
region_nameに引数で指定したregionを同じく指定しています。 - 3行目
all_db_cluster = rds.describe_db_clusters().get('DBClusters')は
describe_db_clustersで取得した結果(json)の中にあるDBClustersを.get('DBClisters')を使って取り出し、all_db_clusterに代入しています。 - 4行目
for each_db_cluster in all_db_cluster:は
all_db_clusterをeach_db_clusterに入れてfor文を実行しています。 - 5行目~6行目
db_cluster_identifier = each_db_cluster['DBClusterIdentifier']
db_cluster_status = each_db_cluster['Status']
は共にall_db_clusterが代入されたeach_db_clisterを使ってDBClusterIdentifierとStatusを取得しています。 - それ以下の行
if db_cluster_status == "available": print(f"RDS DBClusterを停止しました。 ClusterID:{db_cluster_identifier}") rds.stop_db_cluster(DBClusterIdentifier=db_cluster_identifier) else: print(f"{db_cluster_identifier} インスタンスの状態は{db_cluster_status} です")はif文でavailableかそれ以外かを判別しています。
もしavailableだったらavailableのRDSクラスターを停止します。
availableがなかった場合はクラスター名と現在の状態を出力しています。
関数lambda_handlerの説明
最後にlambda_handlerの説明をしたいと思います。
lambda_handlerは少し特殊なので公式から引用したいと思います。
Lambda 関数ハンドラーは、イベントを処理する関数コード内のメソッドです。関数が呼び出されると、Lambda はハンドラーメソッドを実行します。ハンドラーによってレスポンスが終了するか、レスポンスが返ったら、別のイベントを処理できるようになります。
def lambda_handler(event, context):
ec2 = boto3.client('ec2')
regions = list(map(lambda x: x['RegionName'], ec2.describe_regions()['Regions']))
for region in regions:
rds_db_cluster_all_region_stop(region)
rds_db_instance_all_region_stop(region)
print("-------Proccessing complete!----------")- 1行目
def lambda_hamdler(event, context):は
関数名はLambda ハンドラー関数が配置されているファイルの名前を反映しています。Lambda 関数の作成時に指定される Lambda 関数ハンドラー名は、以下から取得されます。
- Lambda ハンドラー関数が配置されているファイルの名前
- Python ハンドラー関数の名前
引数のeventは
イベントオブジェクト です。イベントは、処理する Lambda 関数のデータを含む JSON 形式のドキュメントです。 Lambda ランタイム は、イベントをオブジェクトに変換し、それを関数コードに渡します。これは通常 Python dict タイプです。また list、str、int、float、または NoneType タイプを使用できます。
イベントオブジェクトには、呼び出し元のサービスからの情報が含まれます。関数を呼び出すときは、イベントの構造とコンテンツを決定します。AWS のサービスで関数を呼び出す場合、そのイベントはサービスによって定義されます。
contextは
2番目の引数は コンテキストオブジェクト です。コンテキストオブジェクトは、ランタイムに Lambda によって関数に渡されます。このオブジェクトは、呼び出し、関数、およびランタイム環境に関する情報を示すメソッドおよびプロパティを提供します。
引用:Python の Lambda 関数ハンドラー 仕組み
- 2行目
ec2 = boto3.client('ec2')は
使いたいサービスの名前を文字列で渡してあげています。
今回はEC2を使いたいのでec2を渡しています。 - 3行目
regions = list(map(lambda x: x['RegionName'], ec2.describe_regions()['Regions']))は
ec2.describe_regionsでは利用可能なリージョン名と各リージョンのエンドポイントが返ってきます。
その中からリージョン名を抜き出して、mapでlistにしています。 -
それ以下の行
for region in regions: rds_db_instance_all_region_stop(region) rds_db_cluster_all_region_stop(region) print("-------Proccessing complete!----------")はregionにreionを代入してfor文を実行しています。
for文の中には先ほど説明した関数が入っており、関数が実行されていきます。
for文が終了後printの内容が出力されます。IAMロールの作成
Lambda関数に適応するIAMロールを作成していきます。
許可ポリシーは以下の画像の通りです。

- AmazonRDSFullAccessはRDSの停止やRDSの現在の状態を取得するのに使うのでFullAccessにしてあります。
- amazonEC2ReadOnlyAccessは全リージョンを取得するために使うだけなのでReadOnlyにしてあります。
- CloudWatch-Logs-Lambda-AllRegion-Stop-RoleはCloudWatchLogsの書き込み権限(CreateLogGroup,CreateLogStream,PutLogEvents)を許可しています。

EventBridgeの作成
次にEventBridgeを作成していきます。
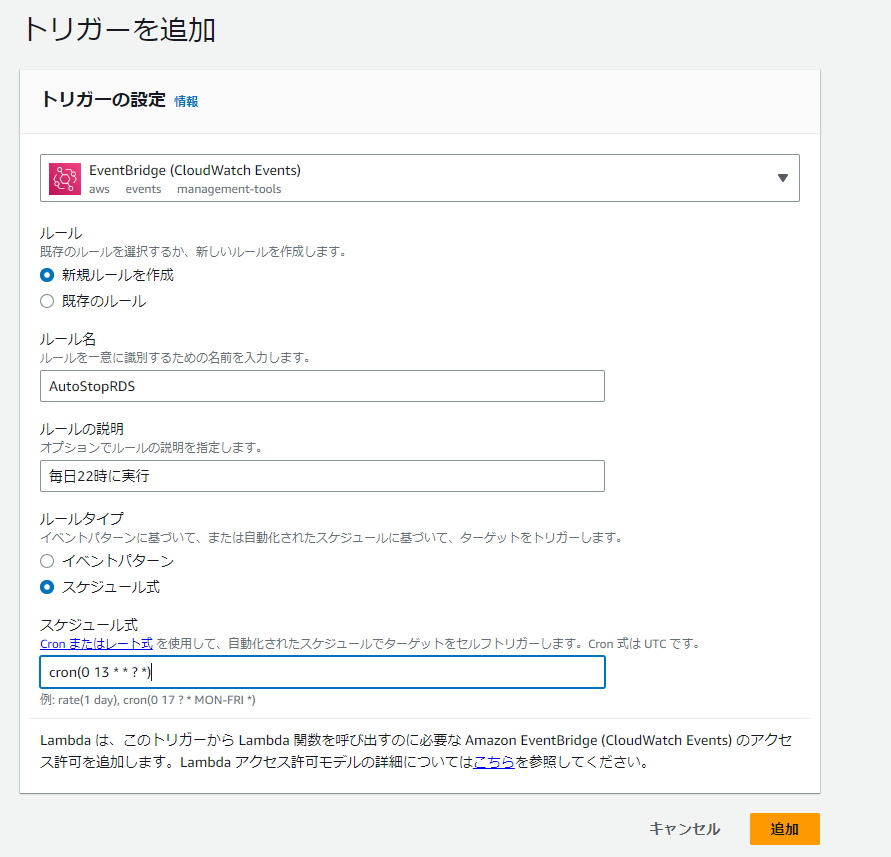
※日本時間と9時間ずれているので13に設定しています。
cron式は毎日22時に実行されるように設定しています。
- cron式は左から分、時、日、月、曜日、年となっています。
今回はcron(0 13 ? *)なので日本時間22:00に毎日実行ということになります。
cron式にはワイルドカードがあり、説明は以下となっています。
- ワイルドカード [,] (カンマ) には追加の値が含まれます。月フィールドの、「JAN,FEB,MAR」は、1 月、2 月、3 月を含みます。
- ワイルドカード [-] (ダッシュ) は範囲を指定します。日フィールドの、「1-15」は、指定した月の 1 日から 15 日を含みます。
- ワイルドカード [] (アスタリスク) にはフィールドのすべての値が含まれます。時間フィールドの、 にはすべての時間が含まれています。[*] を日および曜日フィールドの両方に使用することはできません。一方に使用する場合は、もう一方に [?] を使用する必要があります。
- ワイルドカード [/] (スラッシュ) で増分を指定します。分フィールドで、「1/10」と入力して、その時間の最初の分から始めて、10 分毎を指定できます (11 分、21 分、31 分など)。
- ? (疑問符) ワイルドカードは任意を意味します。[日] フィールドに 7 と入力し、7 日が何曜日であってもかまわない場合、[曜日] フィールドに ? を入力できます。
- Day-of-month フィールドまたは Day-of-week フィールドの、ワイルドカード L は月または週の最終日を指定します。
- Day-of-month フィールドのワイルドカード W は、平日を指定します。Day-of-month フィールドで、3W は月の 3 日目に最も近い平日を指定します。
挙動の確認
挙動の確認のためRDSクラスターとRDSインスタンスを起動しておきます。

Lambda関数を実行します。

Lambda関数実行後、しっかりRDSインスタンスとクラスターが停止しているかを確認します。

しっかり停止しています。
次はEventBridgeがしっかり機能しているか確認します。
※テストのためCron式を19:40に指定しています
上と同様にRDSとクラスターを起動しておきます。
EventBridgeで指定した時刻になるとしっかり停止されることを確認します。

CloudTrailでも指定時間に停止ログが確認できました。

まとめ
Lambda関数とEventBridgeで指定時間で自動実行できる便利なサービスというのを確認しました。
Lambda関数を作成時にboto3の知識とpythonの理解が深まりました。
また機会があればLambda関数とEventBridgeを使って何か作ろうと思います。