




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
みなさまお疲れ様です!
先日投稿したブログ記事でAWSCURを使用してレポートの取得とクエリの実行を検証してみたのですが、その際はCURのレガシータイプのレポートを使用して検証していました。
今回は、DataExportで作成できるようになったCUR2.0のレポートを作成、クエリするところまで検証してみて違いを調査していきたいと思います。
■構成図
また、作成してわかりましたが、AWSCUR2.0については「.yml」ファイルが出力されないため自分でリソースを作成する必要があります。
今回は、以下のような構成図でレポート出力・クエリを実行してみたいと思います。
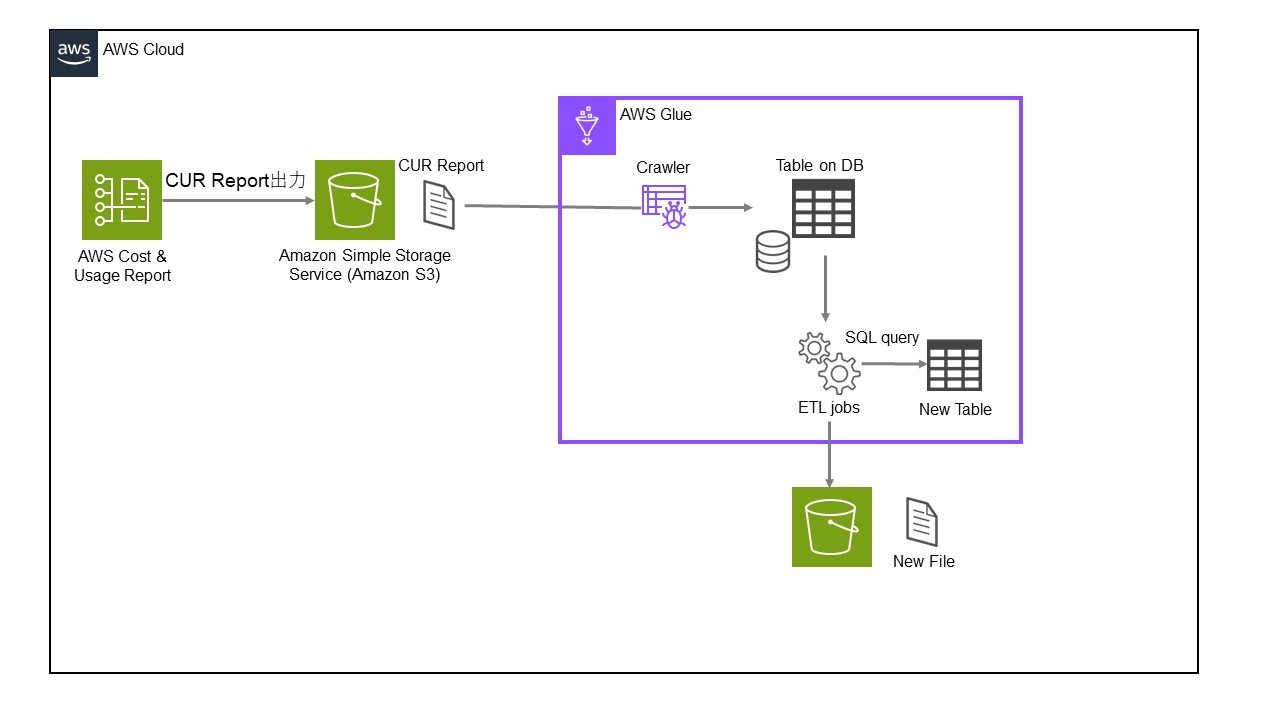
■構築の流れ
各リソースは、以下の流れで構築していきます。
①CUR2.0レポート作成
②AWS Glue Clawlerでレポートをもとにテーブル作成
③ETL Jobsでテーブルに対してクエリ実行
④結果確認
①CUR2.0レポート作成
まず、レポートの作成から実施していきます。
マネジメントコンソールにて、「請求とコスト管理」に移動します。
※検索の場合は、「Billing and Cost Management」と検索すれば出てきます。
コスト分析の欄からデータエクスポートを選択します。
画面が切り替わったら「エクスポートとダッシュボード」から「作成」を押下します。
「作成」画面に繊維したらパラメータを入れながらレポート作成していきます。
「エクスポートタイプ」については、画面のように「標準データエクスポート」を選択します。
それ以外の項目については、以下のようになっています。
・エクスポート名
→任意
・リソースIDを含める
→該当する行項目の一意のAWSリソースIDを含む列を含めます。
個々のリソースIDをエクスポートに含めると、ファイルサイズが大きくなる可能性がありますので環境に合わせて設定をお願いします。
・コスト配分データを分割
→コスト割り当てのために共有リソースの詳細なコストと使用状況を含めます。(Amazon ECSおよびEKSAmazon ECSの場合)
これらのリソースを含めるとコストと使用状況レポートに新しい行と列が追加され、ファイルサイズが大きくなる可能性がありますので環境に合わせて設定をお願いします。
・時間粒度
→エクスポートの行項目を集計する時間の単位を「時間単位」「日次」「月次」から選択できます。
・列選択
→ここが従来のレガシーレポートと大きく違うところになります
列選択を押下すると、以下のように請求項目が一覧化されて、それぞれ個別にチェックをすることができるようになっています。
従来は「Athena」を使用して項目を絞って再度出力していたのがこの設定一発でできるのはとても便利ですね!

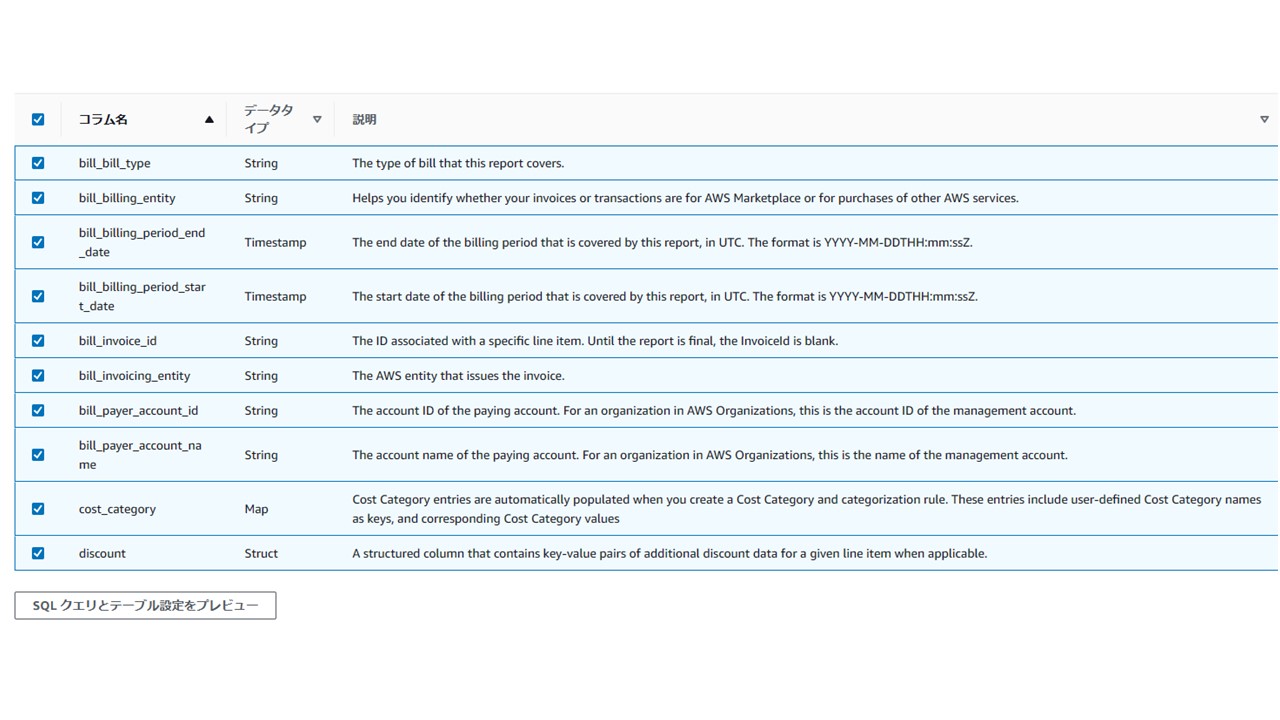
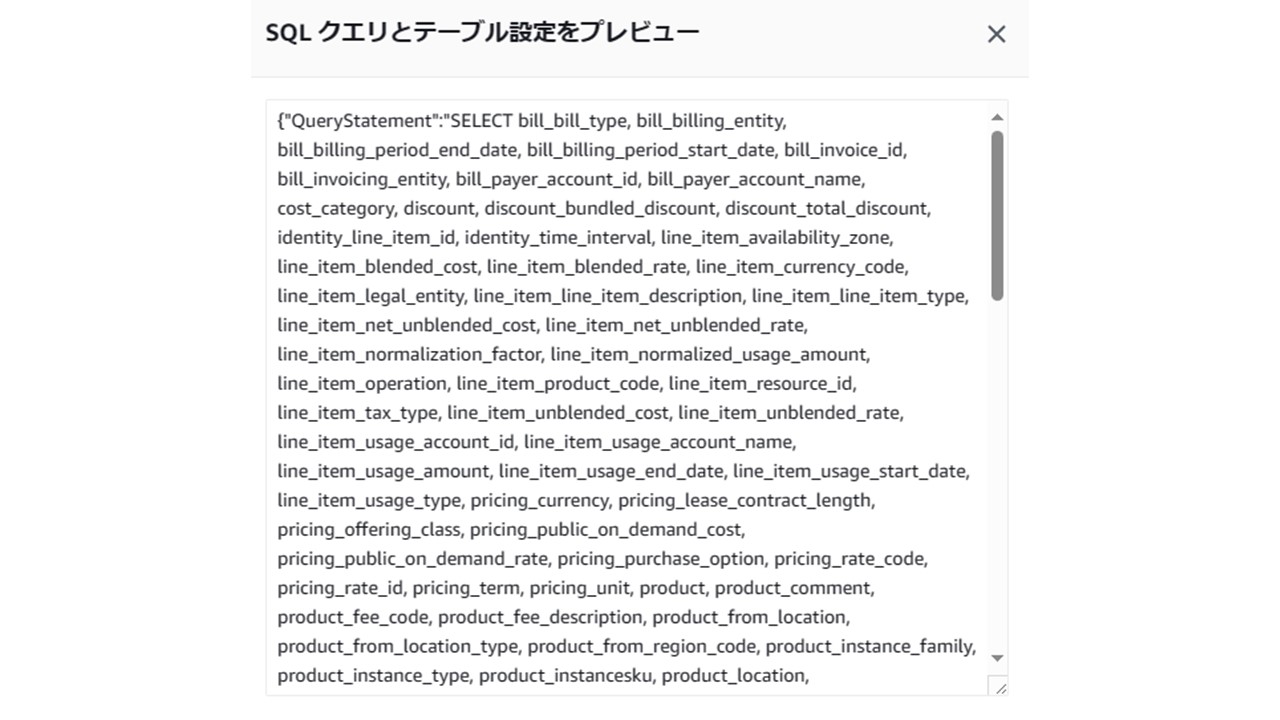
ちなみに、「SQLクエリとテーブル設定をプレビュー」を押下すると
チェックを入れ終わった状態のものをSQLライクに表示することもできます。
・圧縮タイプとファイル形式
→「Parquet」形式か、「gzip(テキスト/csv)」形式か選択します。
・ファイルのバージョニング
→「既存のデータエクスポートファイルを上書き」
「新しいデータエクスポートファイルを作成」の2つから選択できますが、S3のコストを考えるとおすすめは前者の既存を上書きです。
・データエクスポートストレージ設定
→レポートの出力先となるS3のパスを設定してあげます。
ここまで設定できたら、設定は完了なので「作成」を押下します。

しばらくすると、上記で定義した設定にしたがって請求データが指定したS3へエクスポートされます。
プレフィックス以下は下記のようなディレクトリ構造になっております。
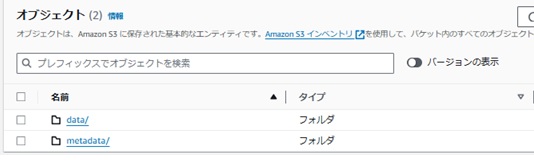
それぞれのディレクトリに格納されているファイルは以下のような特徴があります。
・metadata
「Manifest.json」ファイルとして格納されております。
このファイルはデータがエクスポートされる都度更新され、以下の情報を含みます。
■エクスポートした全ての列情報
■エクスポートしたファイルパス
■エクスポート日付
・data
エクスポートデータ本体が格納されます。
1つの実行結果を1ファイルとして、またはデータが大きい場合は複数のチャンクに配信されます。
■gzip/csv形式の場合(-.csv .gz)
■Parquet形式の場合(-.snappy .parquet)
ここまで確認できれば、次のテーブル作成へ移ります。
②AWS Glue Clawlerでレポートをもとにテーブル作成
先ほど作成したレポートをもとにAWS Glue Clawlerを使用してテーブルを作成していきます。
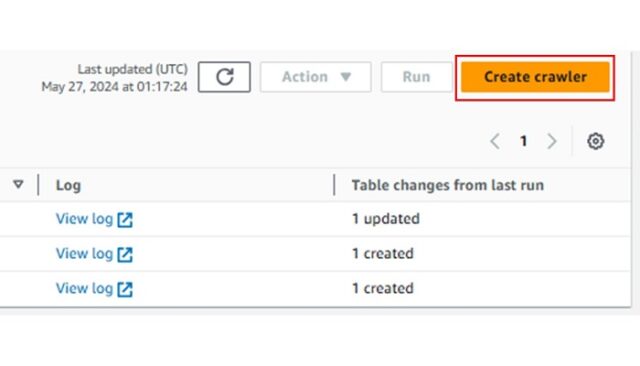
まず、AWS Glueコンソールに移動し「Data Catalog」欄のCrawlersを選択し、「Create crawler」を押下します。
そうすると全5ステップで設定画面に切り替わるのでそれぞれ設定していきます。
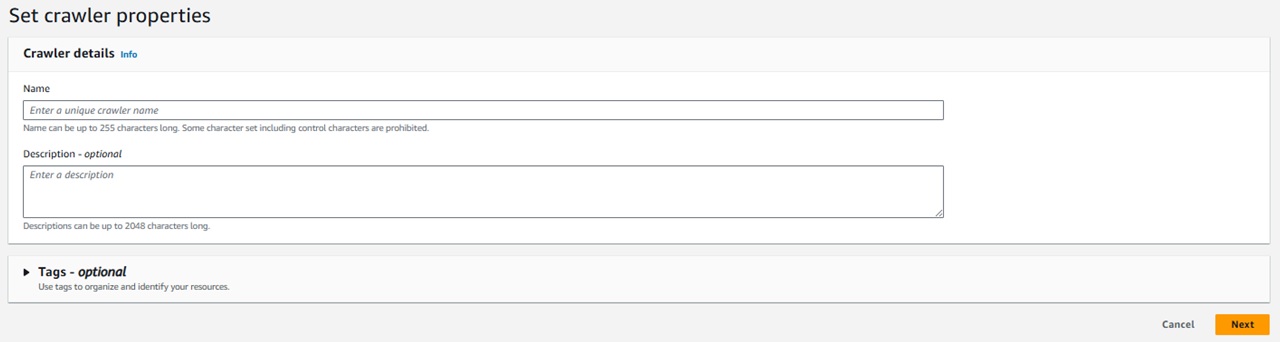
●ステップ1 Set crawler properties
ステップ1では作成するクローラの名前を設定します。
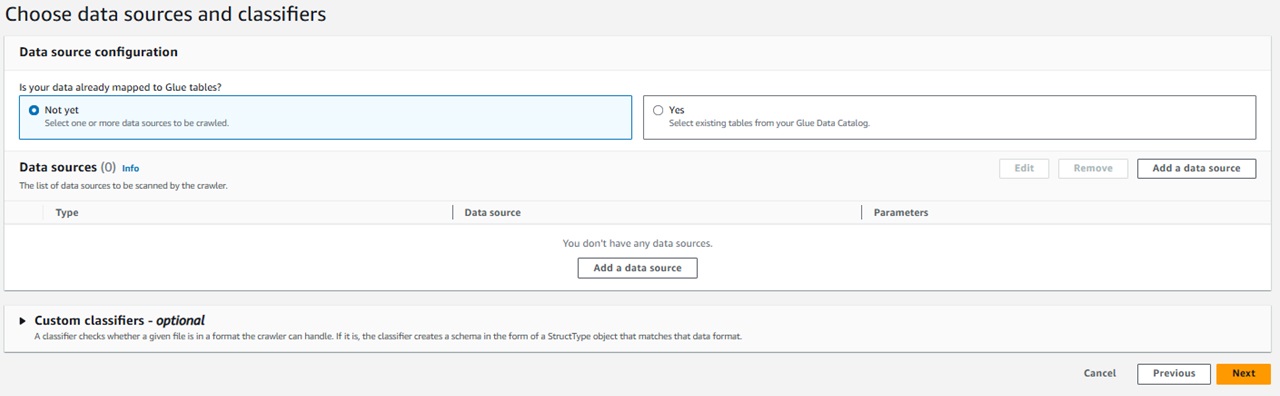
●ステップ2 Choose data sources and classfiers
「Data source configuration」ではデータソースの分類を選択します。
今回は、新規作成のためNot yetを選択します。
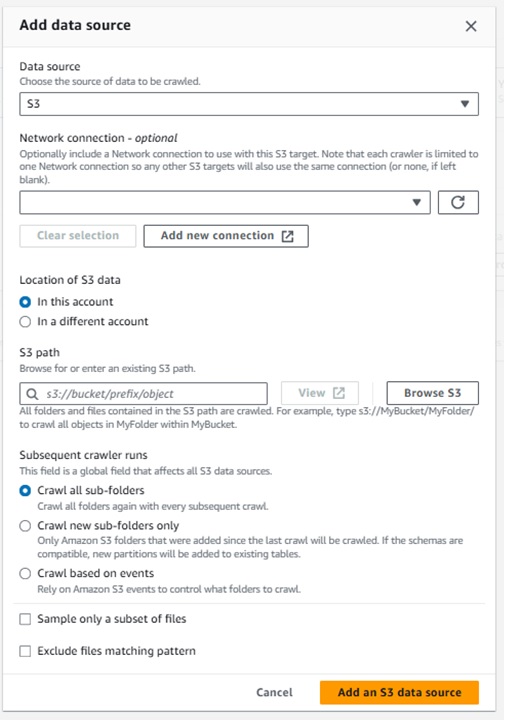
「Data sources」でS3に出力されているレポートを選択します。
※今回は設定していませんが、別アカウントのS3内を参照したり指定したパス配下のフォルダの扱いなどの詳細な設定をすることも可能です。
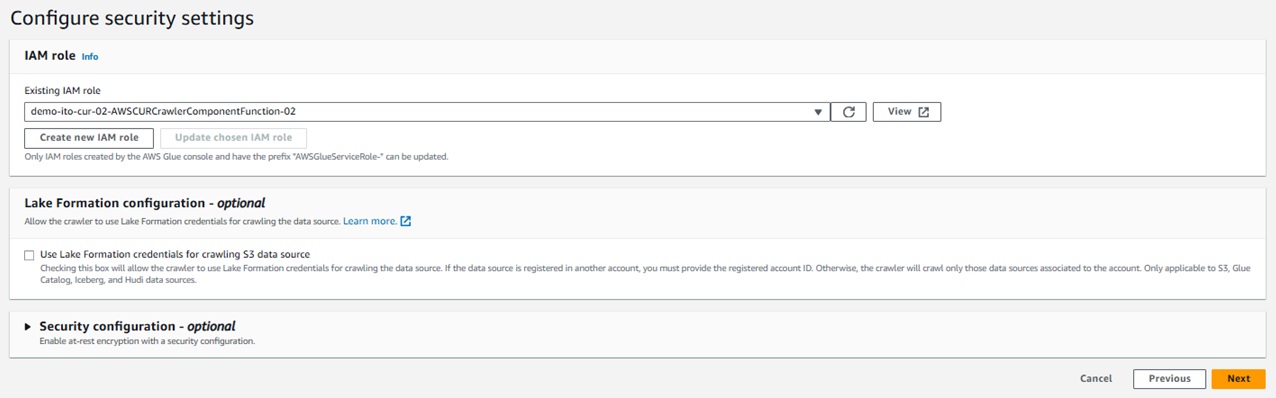
●ステップ3 Configure security settings
Glueクローラに設定するIAMロールを指定します。
ご利用の環境に合わせて設定してみてください。
ご参考までに今回使用したIAMロールに設定しているポリシーを記載しておきます。
・カスタマー管理①
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*",
"Effect": "Allow"
},
{
"Action": [
"glue:UpdateDatabase",
"glue:UpdatePartition",
"glue:CreateTable",
"glue:UpdateTable",
"glue:ImportCatalogToGlue"
],
"Resource": "*",
"Effect": "Allow"
},
{
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": "arn:aws:s3:::ito-test-export-0514/ito-test-export-0514-pathprefix/ito-test-export-0514/data*",
"Effect": "Allow"
}
]
}・カスタマー管理②
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"kms:Decrypt"
],
"Resource": "*",
"Effect": "Allow"
}
]
}・AWS管理「AWSGlueServiceRole」
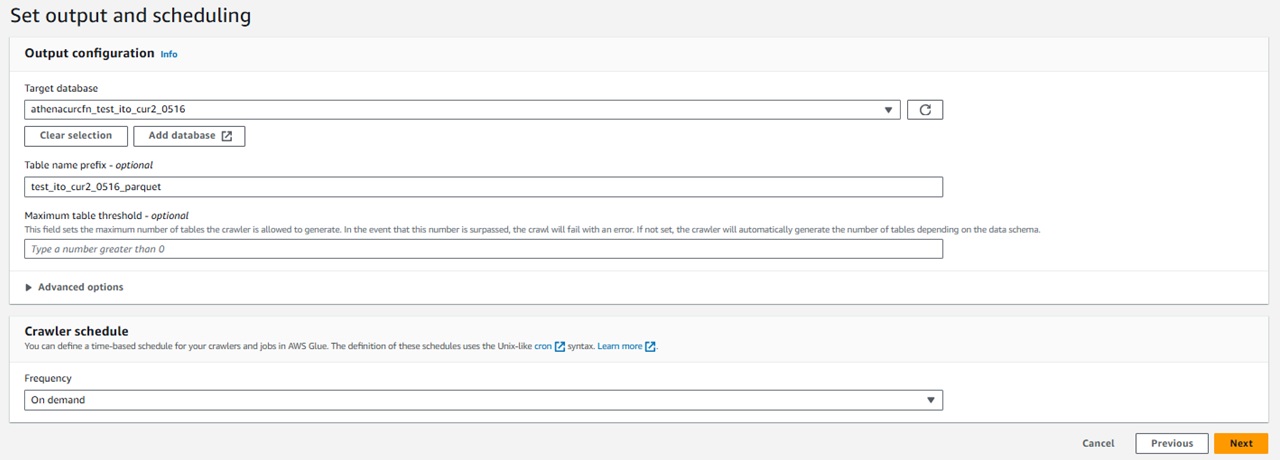
●ステップ4 Set output and scheduling
「Output configuration」では、テーブルを作成するデータベースを選択します。
作成するテーブル名のプレフィックスも設定できます。
「Clawler schedule」ではクローラが実行されるスケジュールを詳細に設定が可能です。
「毎時」「日次」「週次」「月次」「カスタム」から選択できます。
「カスタム」を選択すると、cron式で時刻設定が可能ですので、AWSの請求に合わせて設定したい場合はこちらから設定するのが良いと思います。
※以前は「曜日指定」の欄もあったようですが2024年5月時点では上記5項目でした。
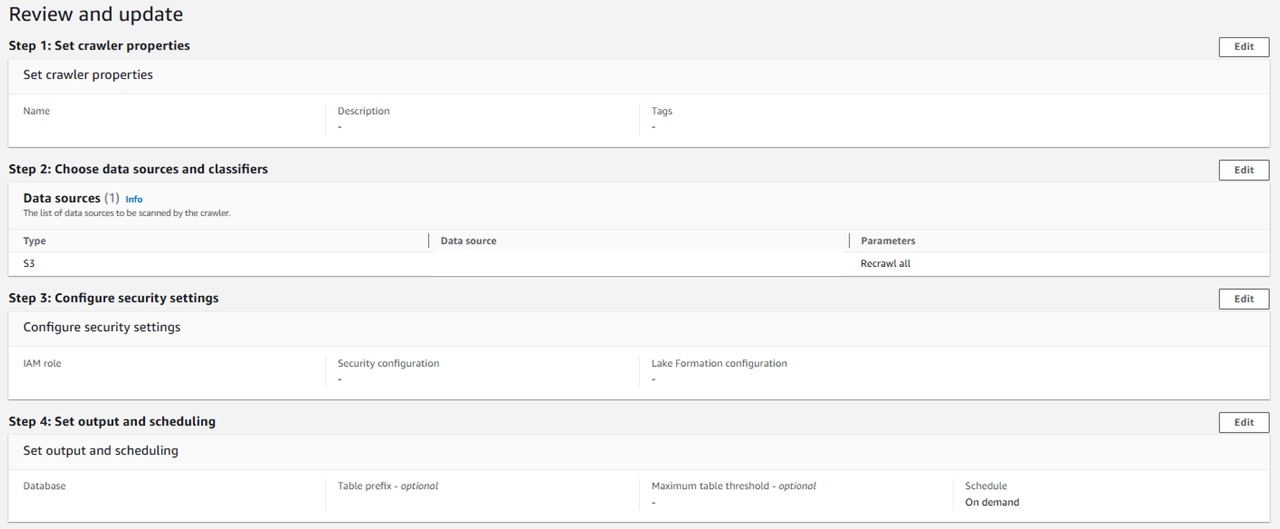
●ステップ5 Review and update
これまでの設定を確認し、問題なければそのまま作成します。
上記がすべて完了したら、ホームに戻り作成されていることを確認します。
今回は、「オンデマンド」で起動するように設定したためクローラを指定して「Run」を押下することでテーブルが作成されます。

テーブルは、AWS Glueホームから「Tables」を選択すると表示されているはずですので、表示されない場合は設定を再度確認してみてください。
ここまでで、標準データエクスポートを使用してレポートを出力し、それをもとにテーブル作成をするところまでできました。
次は、作成したテーブルに対してETL jobからクエリを実行し、それを新たなファイルとして出力する設定をしていきたいと思います。
③ETL Jobsでテーブルに対してクエリ実行
②と同じAWS Glueのコンソールから、「Visual ETL」を選択します。
今回はVisual ETLでジョブを作成するので、オレンジ色の「Visual ETL」を押下します。

すると、画像のようなページに移ります。
ここがジョブ作成ページになります。
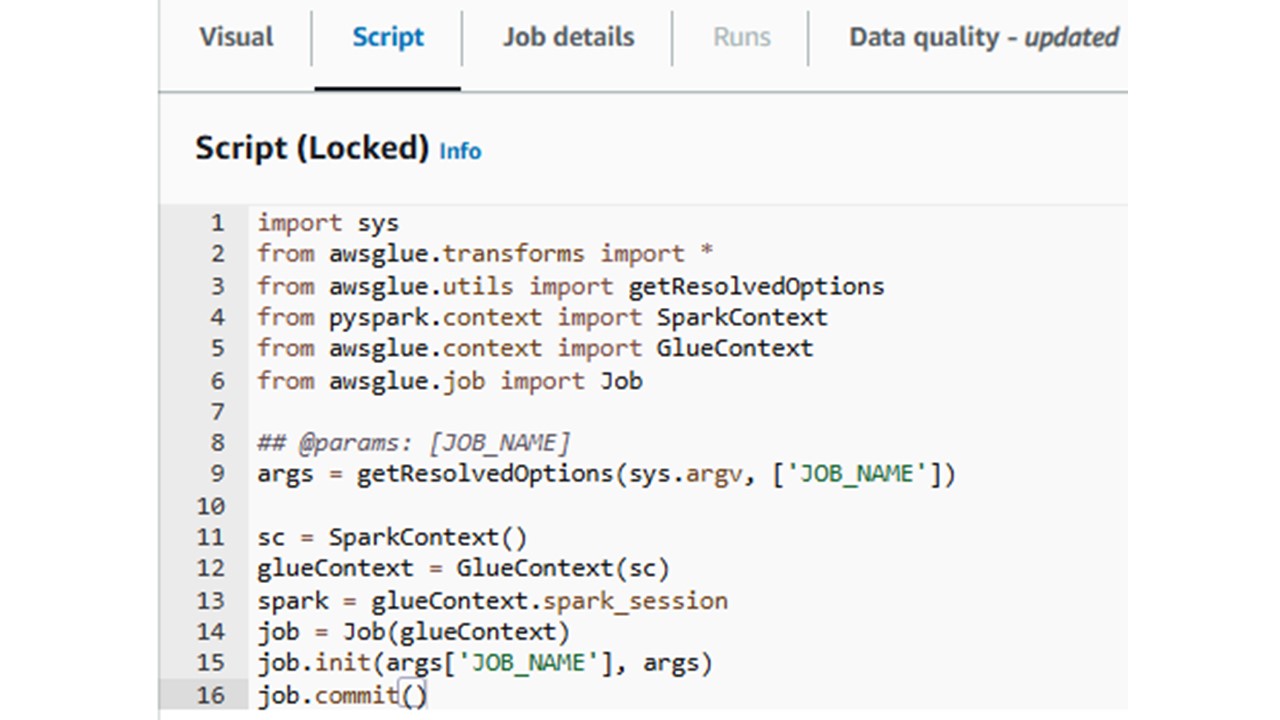
ちなみに、タブの「Script」を選択すると作成したジョブのスクリプト版が見れます。
このスクリプト上でジョブを編集してしまうと、Visualモードでのジョブ閲覧や編集ができなくなってしまうため注意が必要です。
※今回は、Visualモードしか使用しないのでスクリプトはいじりません。
ちなみにジョブ名は、左上の鉛筆マークがあるところで編集可能です。
それでは早速ジョブを作成していきます。
左上の水色の「+マーク」を押下します。
すると、ノード選択ポップアップが出てくるのでここから必要なノードを選択して追加していきます。

改めて、ジョブで実現したい内容は以下の通りです。
①レポートをもとに作成されたテーブルに対してSQLでクエリ
②①のクエリ結果をS3にcsvファイルとして出力、Glueテーブルも作成する
上記内容を加味して作成すると、画像のようなジョブになります。
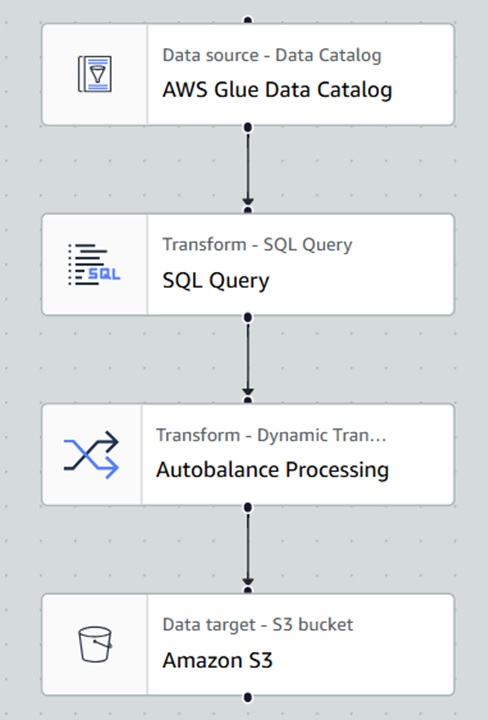
各ノードの設定内容について細かく見ていきます。
※各ノードの設定でノード別に名前が設定できますが、今回は全てデフォルトにしています。
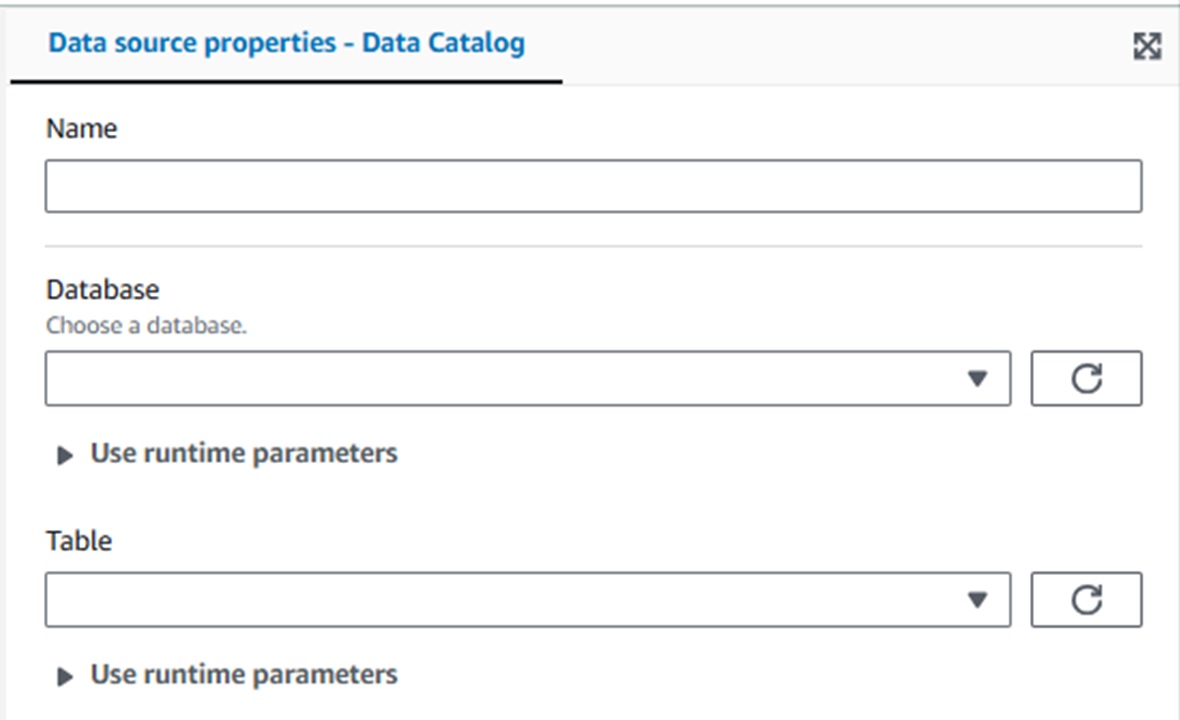
●AWS Glue Data Catalog
[Name] -ノード名
[Database]-対象のテーブルがあるデータベース名を選択
[Table] -クエリを実行するテーブル名を選択
●SQL query
[Name] -ノード名
[Node parents]-どのノード(今回はテーブルを指定しているData Catalog)に実行するか
[Input sources][SQL aliases]-SQLで使用するAliasを設定できます。
[SQL query]-ここに実行したいSQLを書きます。
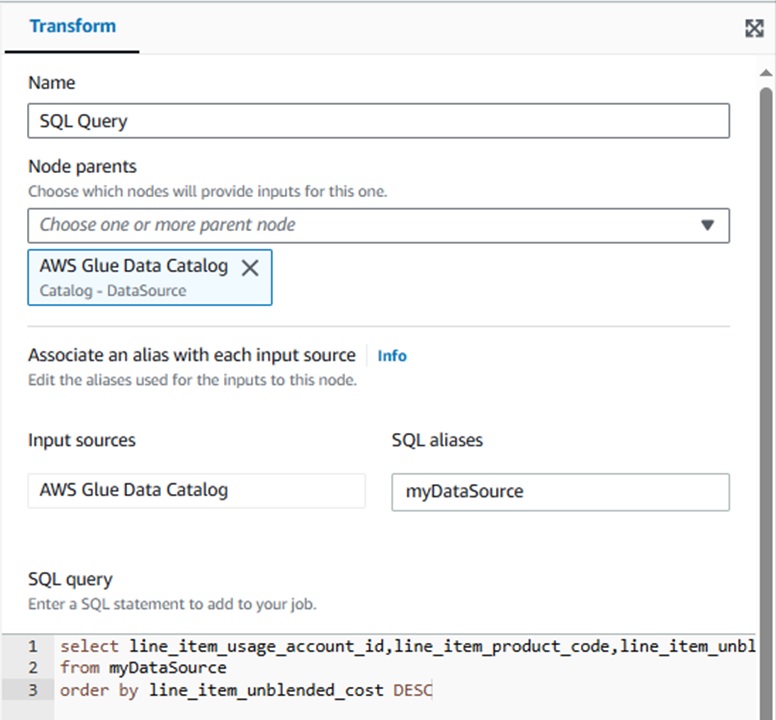
今回は、以下のようなSQL文にしています。
select line_item_usage_account_id,line_item_product_code,line_item_unblended_cost
from myDataSource
order by line_item_unblended_cost DESC
●Autobalance Processing
[Name] -ノード名
[Node parents]-どのノード(今回はSQLを実行しているSQL query)に実行するか
[Number of partitions] -出力ファイル数指定
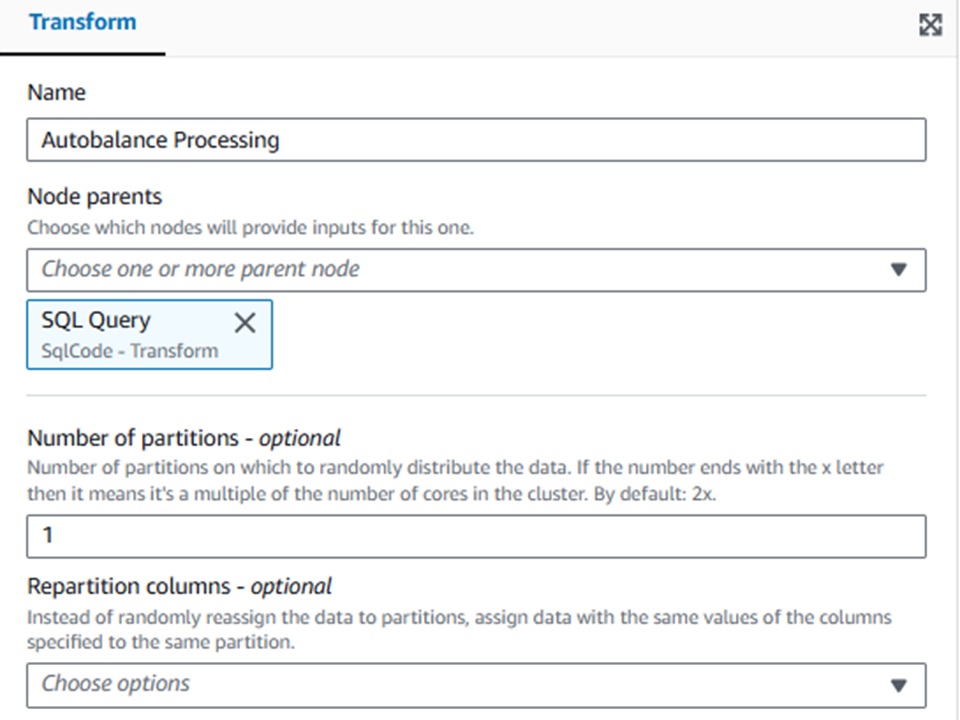
この[Autobalance Processing]ノードを設定してあげないと、S3へ出力されるcsvファイルが分割されてしまいます。
※私の場合は24ファイルに分割されて出力されていました。
●Amazon S3
[Name] -ノード名
[Node parents]-どのノード(今回はAutobalance Processing)に実行するか
[Format]-出力ファイル形式
[Compression Type]-ファイルの圧縮タイプ
[S3 Target Location]-出力先のS3パス
[Data Catalog update options]-データカタログのデータを更新するかどうかの設定ができます。
※今回は、S3への出力と合わせてクエリ結果を新規テーブルへも反映させたいので、
2番目の「Create a table in the Data Catalog and on subsequent runs , update the schema and add a new partitions」を選択しました。
その場合は、出力するデータベースと作成するテーブル名を選択、記入します。
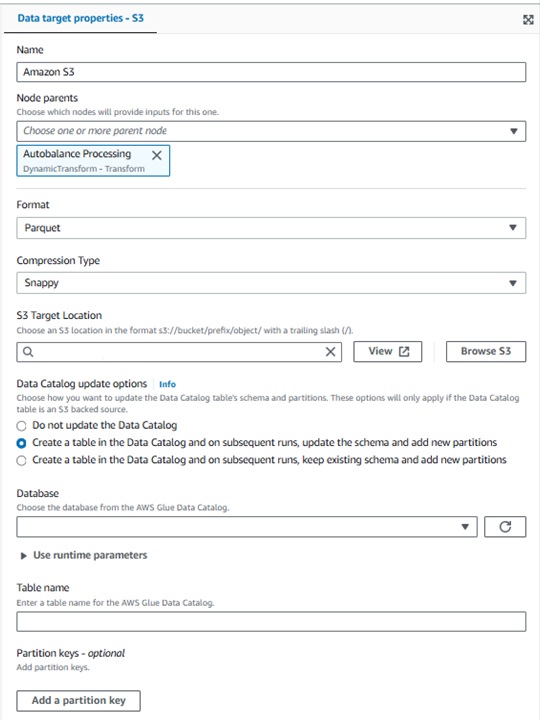
ここまでできたら先ほどの画像のような流れのジョブが完成しました!
完成したら右上のSaveを押下し、保存します。

保存したら最初のVisual ETL画面に映ると、作成したジョブが表示されています。
作成したジョブを起動するには、同じ画面で対象ジョブを選択した状態で「Run job」を押下します。

④結果確認
③で実行したジョブの結果を確認する方法ですが、AWS Glueのコンソール上で「Job run monitoring」を選択します。
画面が遷移したら、「Job runs」の項目に実行中のジョブの結果が反映されています。
下の画像では、成功後の「Successed」になっていますが、実行中は「Running」と表示されているはずです。
ジョブ実行が成功したら、実際にクエリ実行後の結果がS3へファイルが出力されているかどうかと、テーブルが作成されたかどうか確認してみます。
こちらがS3へ出力されたファイルの中身で、
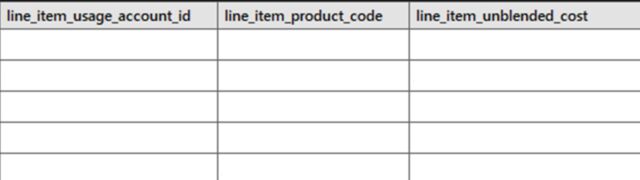
こちらが作成されたテーブルの詳細です!
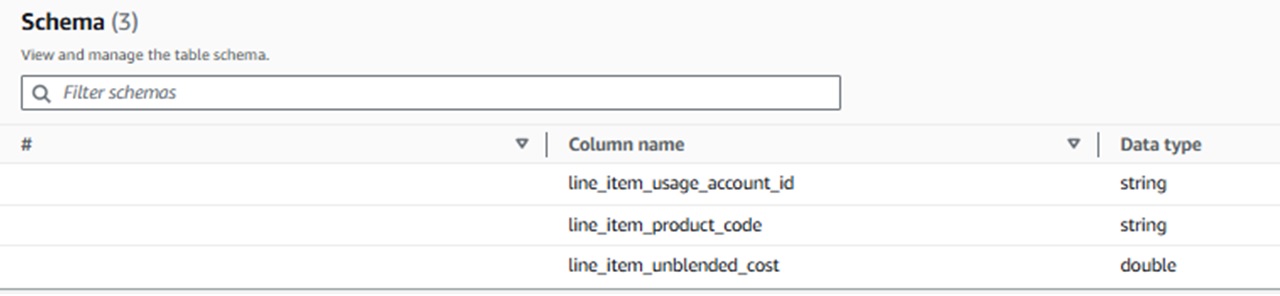
両方ともクエリ実行後の状態で出力・作成されたことを確認することができました!
まとめ
これまで、あまり使用自体してこなかったAWS CURやGlueといったサービスについて、AWSのリソースのコスト確認という名目で調査・検証できたのでとても勉強になりましたし、ジョブの仕組みを知ることができて検証中も楽しみながら学習できました!
この記事をもとにAWSのコスト計算について皆様のお役に少しでもたてれば光栄です。
ありがとうございました!