


この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
はじめに
会議って憂鬱ですよね。そして拍車をかけるように『この無秩序な議事録を作成するのかぁ』と思うと憂鬱を通り越して絶望感が湧き出でてきます。
ならば勉強がてらAWS Transcribeをつかって、自動議事録を自分で構築してみようと思い立ち今回のハンズオンに至りました。
あくまで学習用という側面が強く、機密性というものをどこまで担保するかなどは考慮してないので、実際の会議では利用できないと思っています。ただし無料アプリなどを利用して知らないサーバにアップロードするくらいならLambdaを利用したサーバレスの方が安全かな?程度の、人によってはお叱りを受けるような認識で構築をスタートしていきます。
参考資料
各種参考にしたURLです
AWS
AWSハンズオン-音声を文字起こしする
AWSドキュメント-Lambda_チュートリアル: Amazon S3 トリガーを使用して Lambda 関数を呼び出す
Boto3
Boto3ドキュメント-TranscribeService-start_transcription_job
参考記事
S3 → Lambda → Transcribe → S3 で文字起こしパイプラインを作成する
【Amazon Connect】
コンタクトセンターで使える?
Amazon Transcribeで会話をテキスト化!
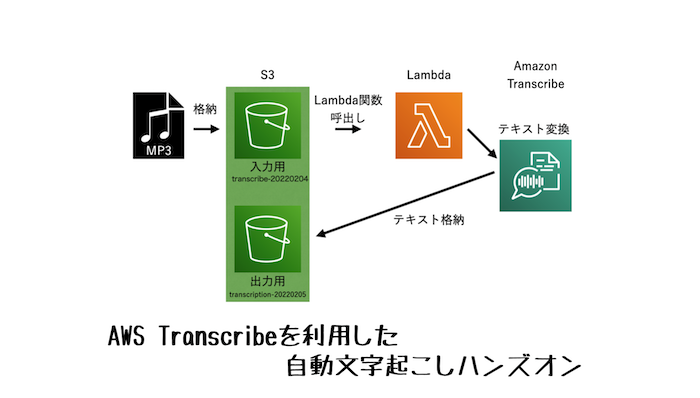
構成図


ハンズオン
1:Amazon S3バケット(入力・出力)の2つを作成する
1.1 Amazon S3に遷移して『バケットを作成』を押下する


1.2 バケット名を入力して『バケットを作成』を押下する

1.3 バケットが作成される(音声ファイルを格納する入力用)

1.4 1.1〜1.2同様の手順でバケットを作成する(Amazon Transcribeで音声をテキスト化して出力されたファイルを格納する用)

2:AWS LambdaでS3バケットを取得する関数を作成する
2.1 AWS Lambdaに遷移して『関数の作成』を押下する

2.2 『関数作成』から『設計図の使用』を選択、『s3-get-object-python』を選択して右下の『設定』を押下する

2.3 基本的な情報に関数名を入力、Lambdaに付与するロール名を入力する

2.4 Lambdaを起動するトリガーとなる、S3のバケット名を入力(サフィックスとして音声ファイルであっても『.mp3』でなければ動作しないようにしています)

※キャプチャを撮り忘れて再度『2.1~2.4』の手順を実行した際に発生したエラーについて
Lambda 関数「Transcribe_function」は正常に作成されましたが、トリガーの作成時にエラー Configuration is ambiguously defined. Cannot have overlapping suffixes in two rules if the prefixes are overlapping for the same event type. (Service: Amazon S3; Status Code: 400; Error Code: InvalidArgument; Request ID: XXXXXXXXXX; S3 Extended Request ID: XXXXXXXXXX Proxy: null) が発生しました。[AWS Lambda関数の「Configuration is ambiguously defined」エラーへの対応] (https://qiita.com/cobot00/items/140835a759055522c523)を参考にしてエラー対応をしました
2.5 Lambda関数が構築されていることを確認する
既に自動でpythonのコードが生成されいることを確認します


3:Lambda関数でAmazon Transcribeのジョブを実行をする
3.1 2で作成したLambda関数を押下して『設定』を選択、『アクセス権限』の実行ロールの『編集』を押下する


3.2 2.3で作成したロールを押下して、IAMへ遷移する

3.3 『AmazonS3FullAccess』と『AmazonTranscribeFullAccess』の2つのポリシーを付与する


※『AmazonS3FullAccess』:S3バケットへ書き込むをするために付与
※『AmazonTranscribeFullAccess』:Amazon Transcribeを呼び出すために付与
3.4 Lambda関数のコードを修正する

上記赤枠のコード該当部分
import json
import urllib.parse
import boto3
import datetime
s3 = boto3.client('s3')
transcribe = boto3.client('transcribe')
def lambda_handler(event, context):
#print("Received event: " + json.dumps(event, indent=2))
# Get the object from the event and show its content type
bucket = event['Records'][0]['s3']['bucket']['name']
key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8')
try:
transcribe.start_transcription_job(
TranscriptionJobName= datetime.datetime.now().strftime('%Y%m%d%H%M%S') + '_Transcription',
LanguageCode='ja-JP',
Media={
'MediaFileUri': 'https://s3.ap-northeast-1.amazonaws.com/' + bucket + '/' + key
},
OutputBucketName='transcription-20220205'
)
except Exception as e:
print(e)
print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this function.'.format(key, bucket))
raise e参考
Boto3ドキュメント-TranscribeService-start_transcription_job
利用するサービス名を記述

AWS Transcribeを参考にして(赤枠部分)を各自修正して記述する

※ファイル名に日付を利用するためにimport datetime
3.5 Lambda関数をデプロイする

これで構築は終了です

4:挙動の確認
4.1 S3バケット『transcribe-20220204』に『.mp3』形式の音声ファイルを保存する

4.2 S3バケット『transcription-20220205』に『.json』形式で音声をテキスト化したファイルが保存されている

4.3 『.json』をS3よりダウンロードして音声化した台本と比較する

さいごに
勿論最初から完璧な文章になるとは思ってもないので、これくらい(肌感覚6割くらい)補完してくれれば議事録作成も今までよりも簡単になるのではないかと思いました。今回S3に格納するファイルを『.mp3』などに絞ってしまいましたが、音声ファイルに類するものを格納した場合にはAWS側で『.mp3』形式に変換させるなどの仕組みも構築できれば、また拡張性が上がるのかもという自分なりの課題も見つけられました。
それに議事録と言っても今回は1人しか話していないので、複数人になった場合なども考える必要はありそうです。
それはまた来週の構築などに活かしていければいいかと思います(問題の先送りともいう)。