




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
今回、自主学習のため QuickSight を使ったデータの分析・可視化を行う基盤構築を実施しました。
Amazon QuickSight とは
Amazon QuickSight はAWSで使える高速クラウドBIサービスツールの事です
Amazon QuickSight はクラウド内のデータに接続し、さまざまなソースのデータを結合します。QuickSight は、単一のデータダッシュボードに AWS データ、サードパーティーデータ、ビッグデータ、スプレッドシートデータ、SaaS データ、B2B データなどを含めることができます。QuickSight は、フルマネージド型のクラウドベースのサービスとして、エンタープライズグレードのセキュリティ、グローバルな可用性、組み込みの冗長性を提供します。また、10 ユーザーから 10,000 ユーザーに拡張する際に必要となるユーザー管理ツールも備えており、インフラストラクチャをデプロイまたは管理する必要がないサービスです
全体像
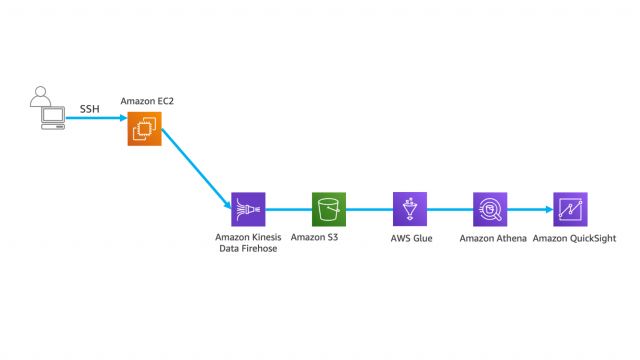
構築の流れ
- CloudFormation で VPCとEC2 構築
- ストリームデータを Kinesis Data Firehose に送信
- データをS3に保存
- Athena を用いて分析
- QuickSight で可視化
事前準備
-
ZIPファイルをダウンロード (今回はlab1→lab4の順で実施してます)
参照サイト : https://github.com/aws-samples/amazon-s3-datalake-handson -
キーペアを作成
1. CloudFormationを使ってVPCとEC2の作成
CloudFormationを 使い VPC を作成し、作成された VPC にログを出力し続ける EC2 を構築します。
ログは2分おきに10件前後出力され、10分おきに300件のエラーログが出力されます。
※ 事前準備で用意したキーペアを使用します
- スタックの作成
スタック作成画面のテンプレート指定において事前に準備していたテンプレートを指定します。
テンプレートのyamlファイルは以下のように設定しています
※今回はQuickSightを使ったデータの可視化が目的なので詳細は省きます
Parameters:
KeyPair:
Description: Name of an existing EC2 KeyPair to enable SSH access to the instance
Type: "AWS::EC2::KeyPair::KeyName"
MinLength: '1'
MaxLength: '255'
AllowedPattern: '[\x20-\x7E]*'
ConstraintDescription: can contain only ASCII characters.
RoleName:
Description: Set role name
Type: String
MinLength: '1'
MaxLength: '255'
AllowedPattern: '[\x20-\x7E]*'
Resources:
# Create VPC
MyVPC:
Type: AWS::EC2::VPC
Properties:
CidrBlock: 10.0.0.0/24
EnableDnsSupport: 'true'
EnableDnsHostnames: 'true'
InstanceTenancy: default
Tags:
- Key: Name
Value: handson-minilake
# Create Public RouteTable
PublicRouteTable:
Type: AWS::EC2::RouteTable
Properties:
VpcId: !Ref MyVPC
Tags:
- Key: Name
Value: handson-minilake
# Create Public Subnet A
PublicSubnetA:
Type: AWS::EC2::Subnet
Properties:
VpcId: !Ref MyVPC
CidrBlock: 10.0.0.0/27
AvailabilityZone: "ap-northeast-1a"
Tags:
- Key: Name
Value: handson-minilake
PubSubnetARouteTableAssociation:
Type: AWS::EC2::SubnetRouteTableAssociation
Properties:
SubnetId: !Ref PublicSubnetA
RouteTableId: !Ref PublicRouteTable
# Create InternetGateway
myInternetGateway:
Type: "AWS::EC2::InternetGateway"
Properties:
Tags:
- Key: Name
Value: handson-minilake
AttachGateway:
Type: AWS::EC2::VPCGatewayAttachment
Properties:
VpcId: !Ref MyVPC
InternetGatewayId: !Ref myInternetGateway
myRoute:
Type: AWS::EC2::Route
DependsOn: myInternetGateway
Properties:
RouteTableId: !Ref PublicRouteTable
DestinationCidrBlock: 0.0.0.0/0
GatewayId: !Ref myInternetGateway
MyEIP:
Type: "AWS::EC2::EIP"
Properties:
Domain: vpc
ElasticIPAssociate:
DependsOn: MyEC2Instance
Type: AWS::EC2::EIPAssociation
Properties:
AllocationId: !GetAtt MyEIP.AllocationId
InstanceId: !Ref MyEC2Instance
MyEC2Instance:
Type: 'AWS::EC2::Instance'
Properties:
ImageId: ami-08c23a10b77e0835b
InstanceType: t2.micro
SubnetId: !Ref PublicSubnetA
KeyName :
Ref: KeyPair
SecurityGroupIds:
- Ref: MyEC2SecurityGroup
IamInstanceProfile: !Ref InstanceProfile
Tags:
- Key: Name
Value: handson-minilake
MyEC2SecurityGroup:
Type: 'AWS::EC2::SecurityGroup'
Properties:
GroupName: handson-minilake-sg
GroupDescription: Enable SSH access via port 22
VpcId: !Ref MyVPC
SecurityGroupIngress:
- IpProtocol: tcp
FromPort: '22'
ToPort: '22'
CidrIp:
'0.0.0.0/0'
- IpProtocol: tcp
FromPort: '5439'
ToPort: '5439'
CidrIp:
'0.0.0.0/0'
minilaketestrole:
Type: 'AWS::IAM::Role'
Properties:
AssumeRolePolicyDocument:
Version: '2012-10-17'
Statement:
- Effect: Allow
Principal:
Service:
- ec2.amazonaws.com
Action:
- 'sts:AssumeRole'
Path: /
RoleName: !Ref RoleName
ManagedPolicyArns:
- arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
InstanceProfile:
Type: 'AWS::IAM::InstanceProfile'
Properties:
Path: '/'
Roles:
- !Ref minilaketestrole
Outputs:
AllowIPAddress:
Description: EC2 PublicIP
Value: !Join
- ','
- - !Ref MyEIP
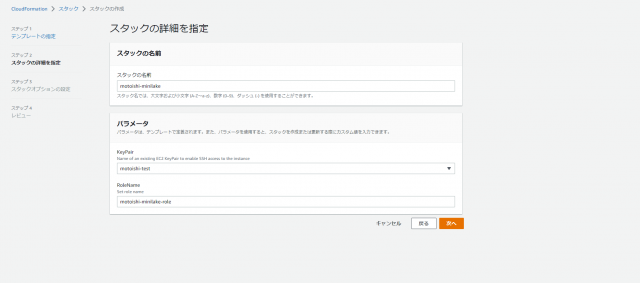
次へをクリックし「スタックの詳細を指定」を以下のように設定しています
「スタックオプションの設定」は何も設定せず、次へ
レビューページで内容を確認して「AWS CloudFormation によって IAM リソースがカスタム名で作成される場合があることを承認します。」にチェックを入れ、スタックを作成します
数分待つとEC2が作成され/root/es-demo/testapp.log にログ出力が始まります。
- EC2 に SSH 接続してログが2分おきに出力していることを確認
※CloudFormationで作成しているので、すでにログ収集ソフトウェア Fluentd がインストールされています
以下のコマンドを実施
sudo su -
tail -f /root/es-demo/testapp.log ・出力ログを10行表示するため
・sudo su - root権限でコマンドを実行するため
・ -f ファイルの追記を監視し、ログが出力された時に表示するため
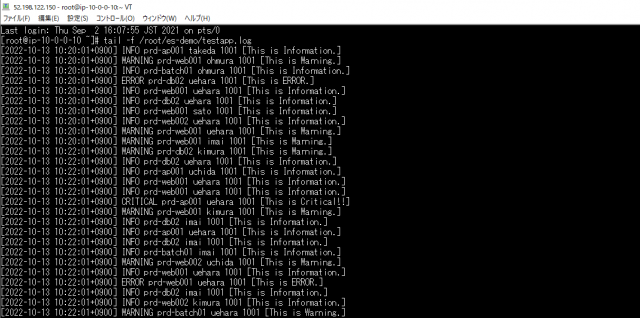
ログが2分ごとに出力されている事が確認できました
2. S3バケットの作成
データを保存するS3バケットを作成します
バケット名は任意で設定、その他はデフォルトでバケットを作成
S3バケットの作成が完了しました。
3. Kinesis Data Firehose の作成
ストリームデータをS3に保存するために配信ストリームを作成していきます
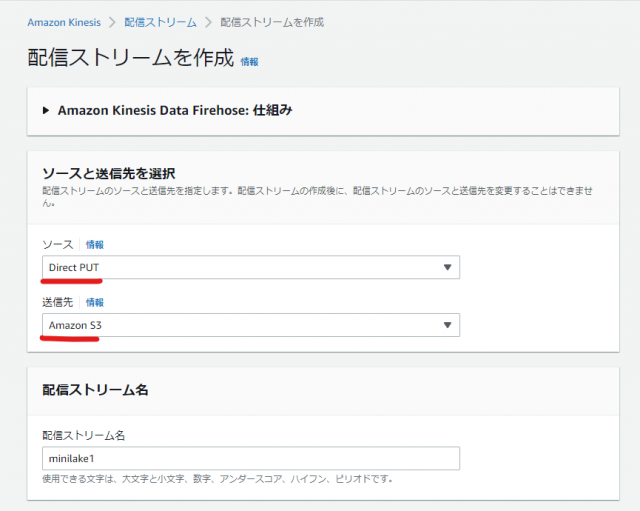
以下のように設定します
| 項目 | 値 |
|---|---|
| ソース | Direct put |
| 送信先 | Amazon S3 |
| 配信ストリーム名 | minilake1 |
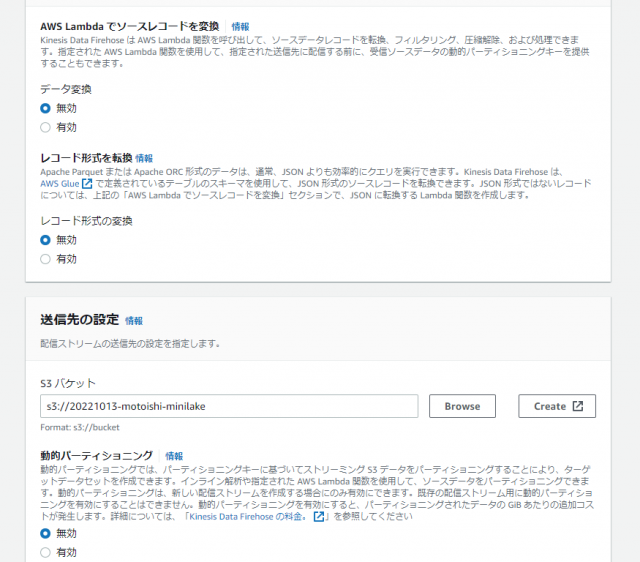
| データ変換 | 無効 |
| レコード形式の変換 | 無効 |
| S3 バケット | 作成したバケットを選択 |
| 動的パーティショニング | 無効 |
| S3 バケットプレフィックス – オプション | minilake -in1/ |
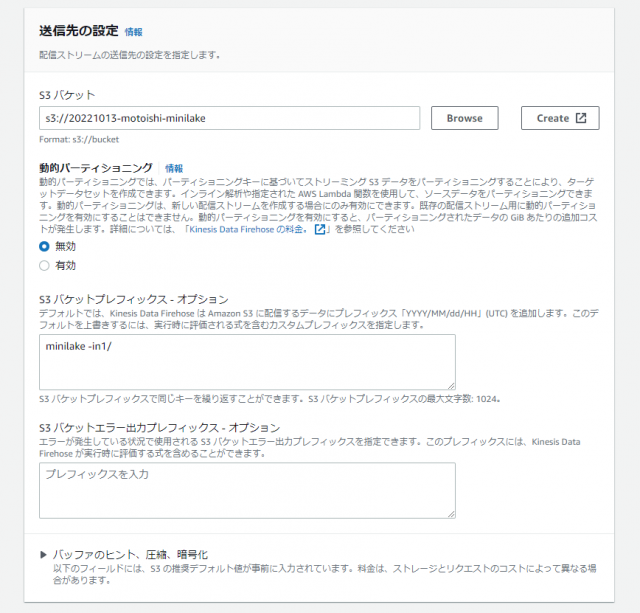
※今回は設定していませんが、データの圧縮、暗号化も可能です。
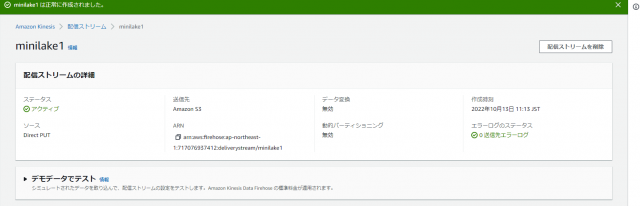
作成できました。ステータスがアクティブになるまで数分かかる場合があります
4. EC2の設定変更
- ストリームデータを Kinesis Data Firehose に送信
- データをS3に保存
- EC2からKinesis Data Firehoseにアクセスするため、作成済のIAMロールに
AmazonKinesisFirehoseFullAccessのポリシーを追加します。
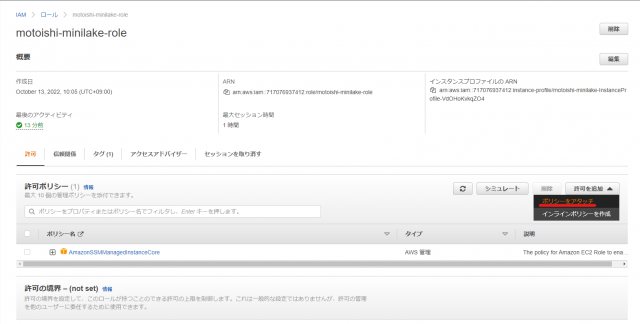
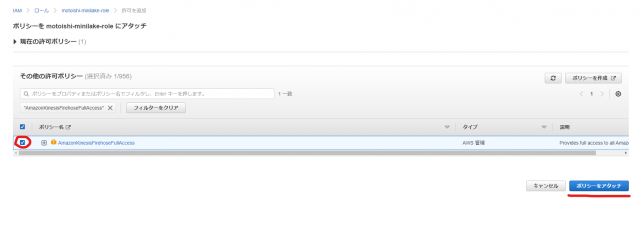
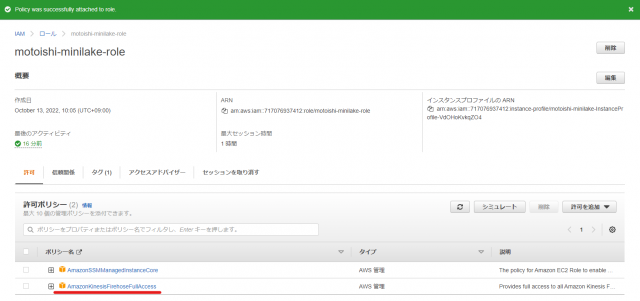
ポリシーが追加できました
- Fluentd から Kinesis Data Firehose にログデータを送信するための設定
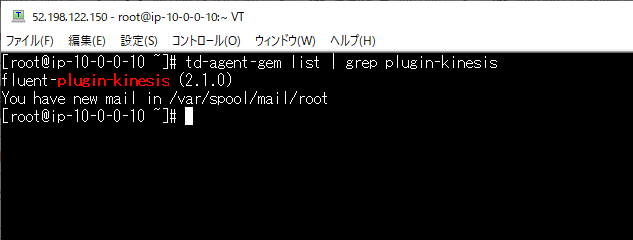
Kinesis Data Firehose のプラグインのインストール状況を確認します。
td-agent-gem list | grep plugin-kinesisを入力
td-agent-gem list の出力した内容を|でgrep plugin-kinesisへ渡し、その値を処理して標準出力へ実行した結果を出力します
- 詳細
・td-agent Fluentd(ログ収集ソフトウェア)
・gem list インストールリストの表示
・| コマンドを実行した結果をさらに別のコマンドを使って処理するため
・grep ファイルから文字列(plugin-kinesis)を検索するため
「/etc/td-agent/td-agent.conf」の中身を事前準備しておいた「4-td-agent2.conf」に置き換えます
「4-td-agent2.conf」は以下の通りです
※今回はQuickSightを使ったデータの可視化が目的なので詳細は省きます
<source>
@type tail
path /root/es-demo/testapp.log
pos_file /var/log/td-agent/testapp.log.pos
format /^\[(?<timestamp>[^ ]* [^ ]*)\] (?<alarmlevel>[^ ]*) *? (?<host>[^ ]*) * (?<user>[^ ]*) * (?<number>.*) \[(?<text>.*)\]$/
time_format %d/%b/%Y:%H:%M:%S %z
types size:integer, status:integer, reqtime:float, runtime:float, time:time
tag testappec2.log
</source>
<match testappec2.log>
@type copy
<store>
@type kinesis_firehose
delivery_stream_name minilake1
flush_interval 1s
</store>
</match>
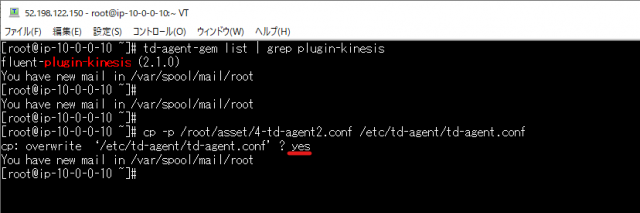
cp -p /root/asset/4-td-agent2.conf /etc/td-agent/td-agent.conf
置き換えますか?の確認が入る為、yesと入力します。
- S3 にデータが出力されていることを確認
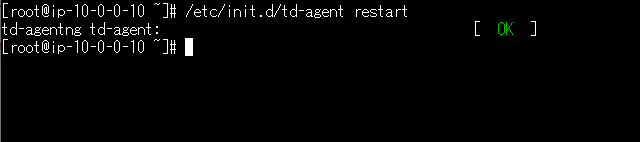
Fluentd を再起動
/etc/init.d/td-agent restart
作成した配信ストリームを選択し、モニタリングをクリック
※反映されるまで数分かかります
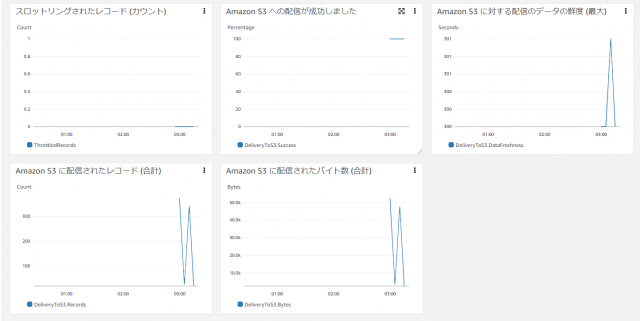
S3 にデータが出力されていることを確認できました
5. Glue Crawler の設定
Athenaで分析を行うにはデータカタログが必要になります。このデータカタログはAWS Glue内で保持されます。今回はデータソースをS3とし、Glue Crawlerにてデータカタログを作成し、Athenaからクエリを実行します。
AWS公式サイト AWS Glue との統合
- IAMロールのポリシー追加
作成済みのIAMロールのポリシーにAWSGlueServiceRoleとAmazonS3ReadOnlyAccessを追加します
AWSGlueServiceRoleS3にGlueからアクセスするためAmazonS3ReadOnlyAccessS3に読み取りアクセスするため
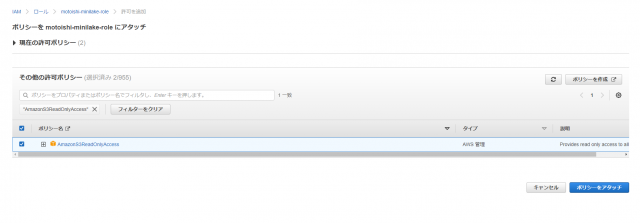
AWSGlueServiceRoleとAmazonS3ReadOnlyAccessがアタッチされていることを確認します
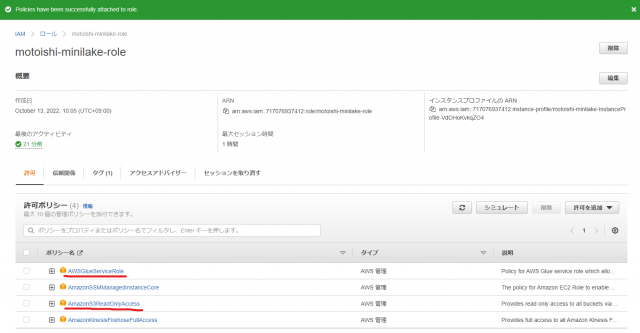
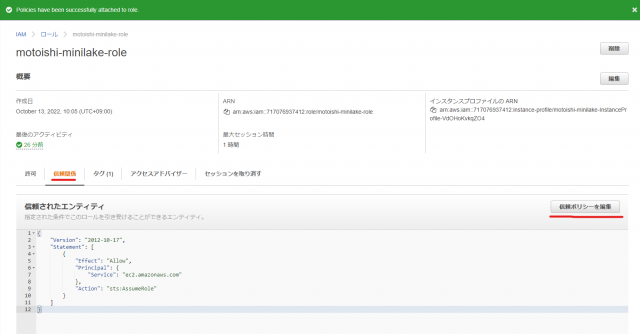
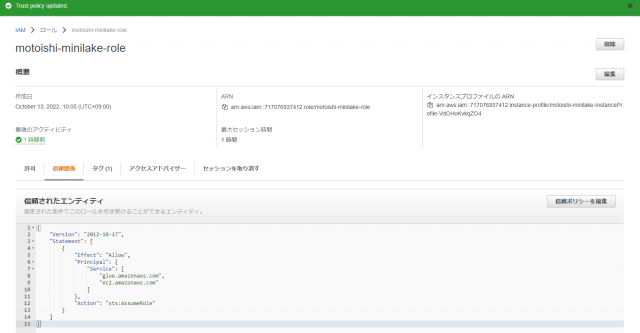
- 信頼ポリシーの編集
信頼関係タブの信頼ポリシーの編集をクリック
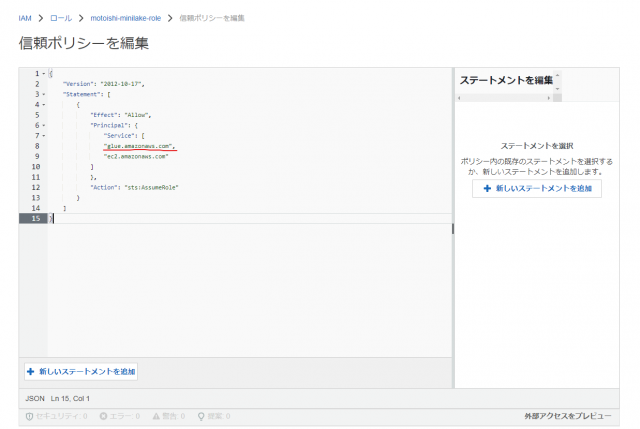
” Service”: “ec2.amazonaws.com”の箇所に"glue.amazonaws.com",を追記します
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"glue.amazonaws.com",
"ec2.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
追記したらポリシーを更新をクリック
↓
- Glue Crawler の作成
サービス AWS Glueを選択 画面左側の Crawlersw をクリック Create crawler クリック
クローラを追加していきます
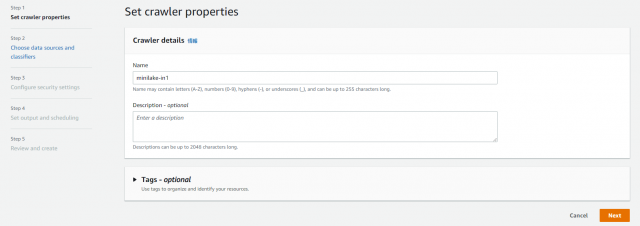
任意でNameを入力
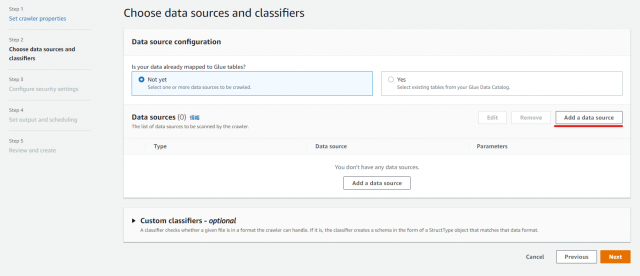
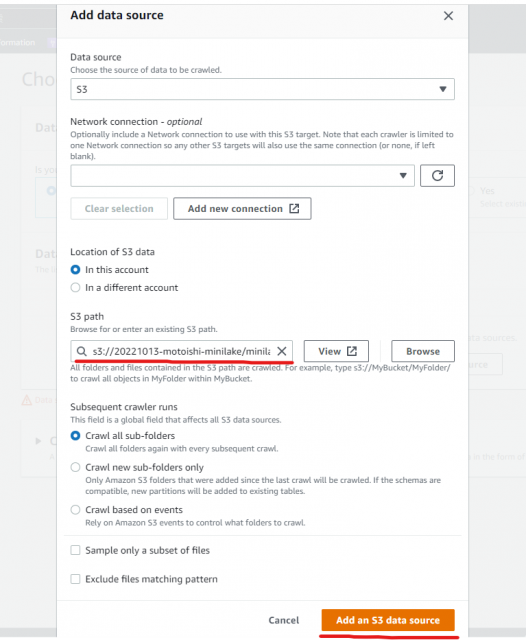
・Not yet を選択、Add a data source をクリックし
s3://[S3 BUCKET NAME]/minilake-in1(任意)を入力
※ S3をデータソースにするため
↓
↓
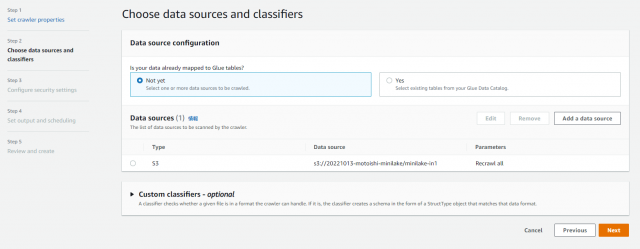
Existing IAM role で作成済みのIAMロールを選択し、次へ
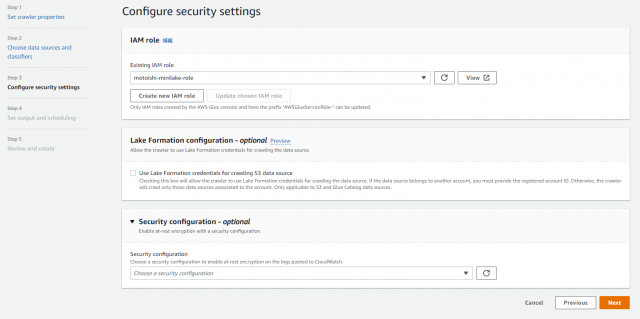
Add database をクリック
↓
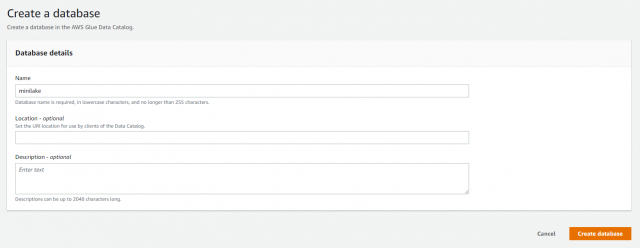
↓
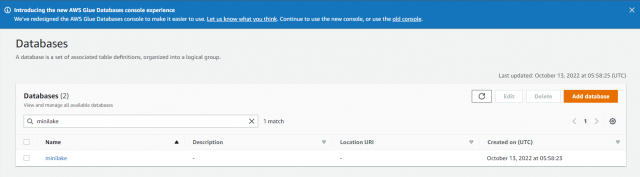
データベースの作成ができました
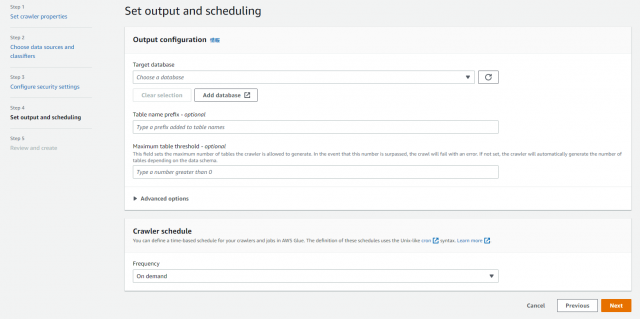
Set output and scheduling の画面に戻り、作成したデータベースを選択、次へ
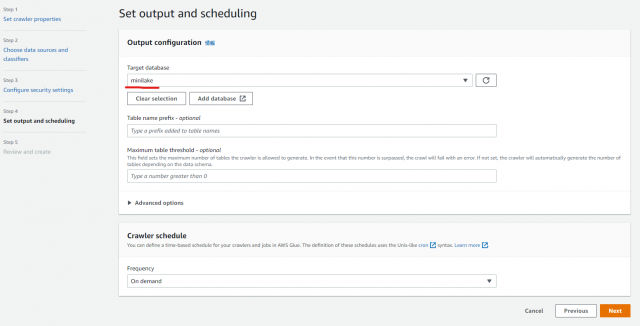
次の画面で内容を確認しCreate crawler をクリック
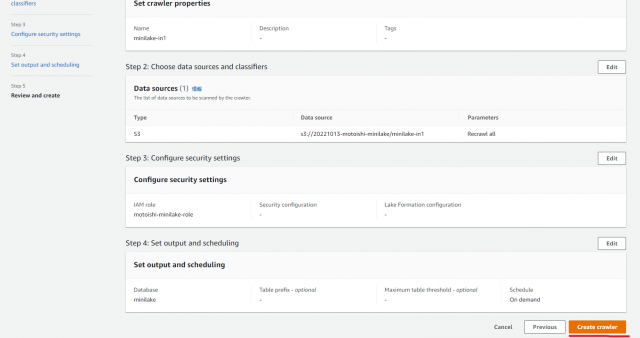
↓
- テーブルの確認
Glue Crawlerを作成した際に自動でテーブルが作成されているかの確認をします
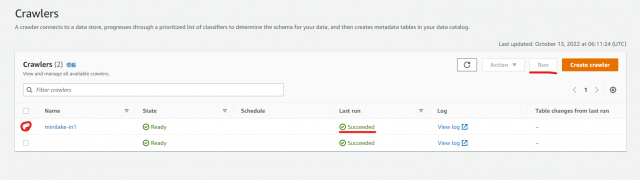
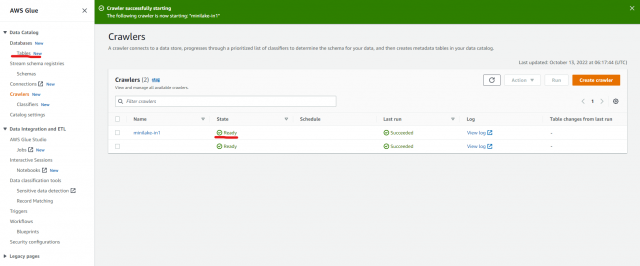
作成したクローラのにチェックを入れ、「Run」 をクリックします
ステータスが「Starting」から[Ready]に変わったら、左の「Tables」をクリックしテーブルが自動作成されていることを確認します
↓
↓
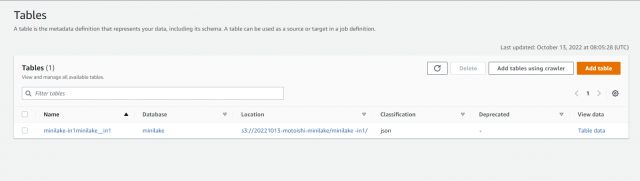
6. Athena でクエリ実行
- Athena を用いて分析
Athenaを使用してS3に保存しているデータの分析を行います
サービス一覧から Athena を選択し、クエリエディタをクリック
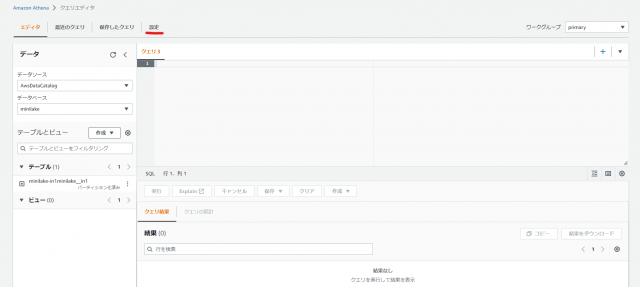
※使用している AWS アカウントで初めて Athena を利用する場合は、クエリの結果の場所と暗号化を設定してください
設定→クエリの結果と暗号化の設定→管理
↓
バケット名の後ろにresult/を記載してください
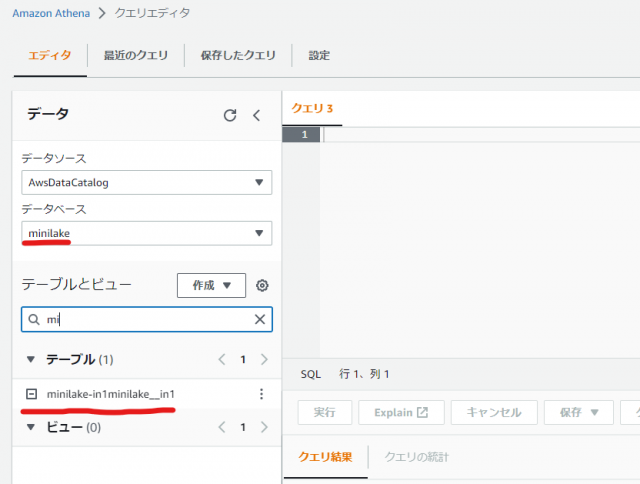
- データベースとテーブル欄で作成したものを選択します
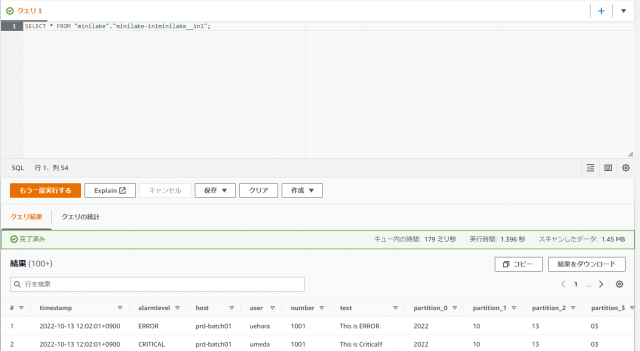
- クエリエディタで下記 SQL を実行します
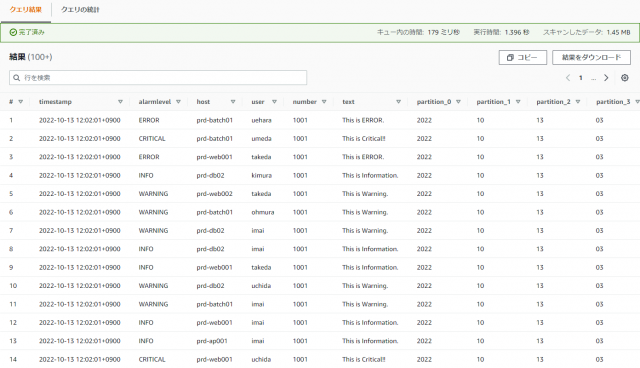
SELECT * FROM "minilake"."minilake-in1minilake__in1";
※ "minilake"."minilake-in1minilake__in1"の部分はご自身で設定したデータベース名とテーブル名に変更してください
7. QuickSight の設定
- サービス一覧から QuickSight を選択します。
QuickSight を初めて使う方は[QuickSightにサインアップ] をクリック
QuickSight アカウントを作成してください
※ すでに東京リージョン以外で登録されている場合、 [QuickSight の管理] → [お客様のサブスクリプション] で、所持しているサブスクリプションを選択し [サブスクリプション削除] をクリックします。実施後、数分待つと、再度 サインアップが可能になります。

- 今回は東京リージョンで実施しているので東京を選択
QuickSight アカウント名、通知のEメールアドレスを任意で設定
その他はデフォルトで完了をクリック
数十秒ほどでサインアップ完了

- 右上のアイコンをクリックし、 [QuickSight の管理] をクリックします
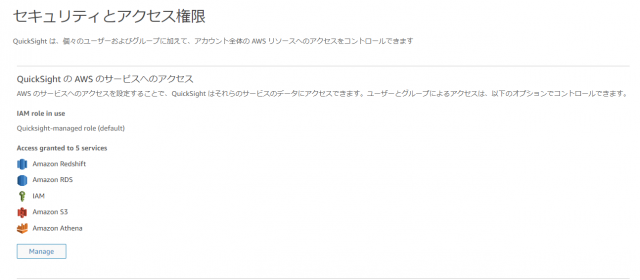
AthenaとS3にアクセスできるように設定します
右上のアイコンをクリックし、 [QuickSight の管理] をクリックします
[セキュリティとアクセス権限] をクリック
QuickSight の AWS のサービスへのアクセスの [Manege] をクリック
- [Amazon Athena] にチェックを入れる(すでにチェックが入っている場合はそのまま)
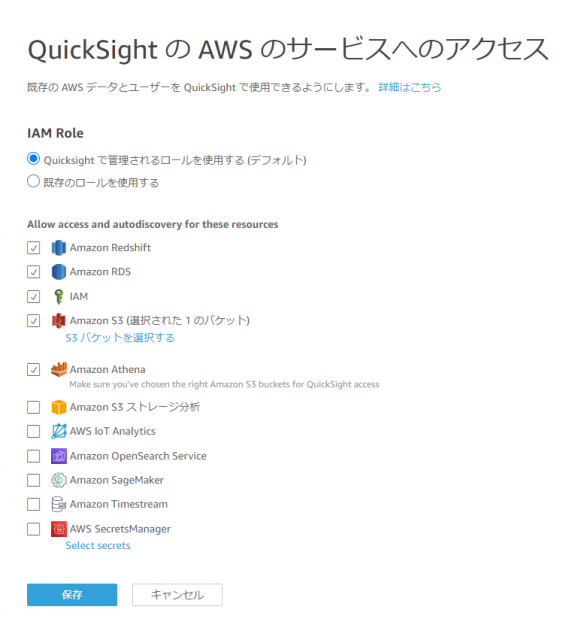
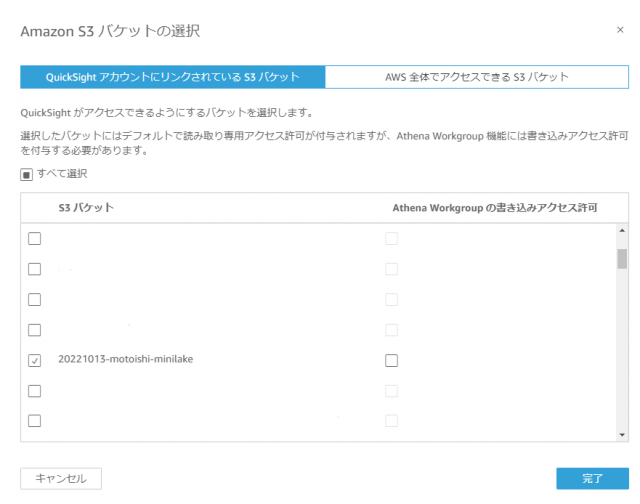
- [Amazon S3] の [S3 バケットを選択する] をクリック
作成したS3のバケット名にチェックを入れ(すでにチェックが入っている場合はそのまま)
完了を選択
保存をクリックして設定は完了です
- 左上の QuickSight のロゴをクリックしてHOME画面に戻ります
8. QuickSightでデータの可視化
- 新しい分析をクリックし新しいデータセットをクリック
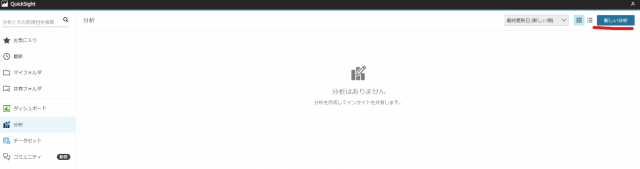
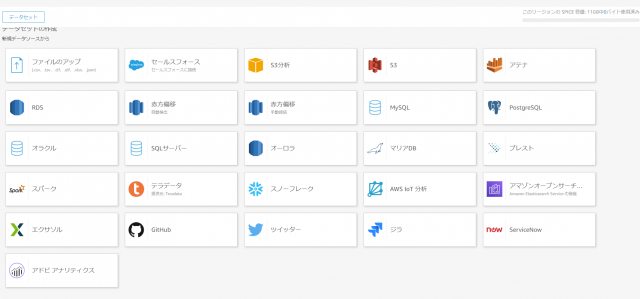
- Athenaをクリック
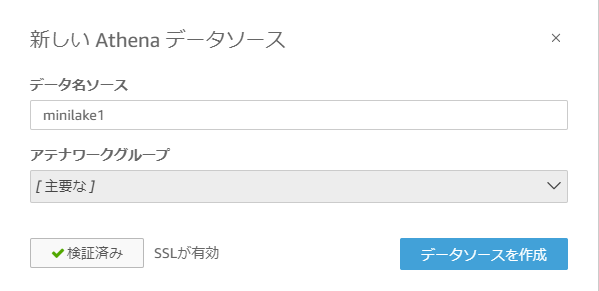
- データソース名を任意で入力し、 [接続を検証] をクリックし、検証済みと表示されたら
[データソースを作成] をクリックします
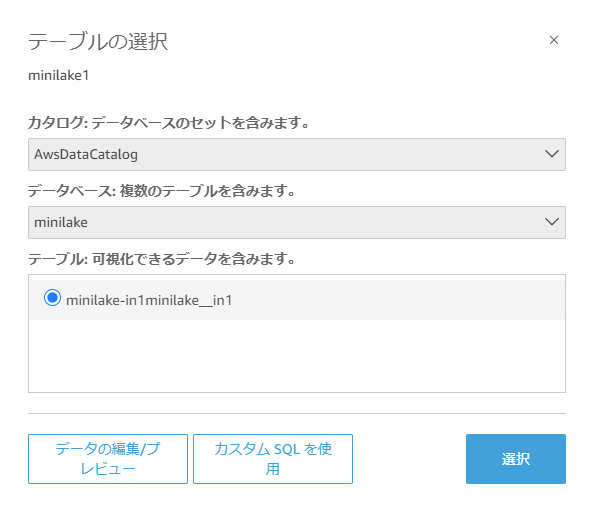
- データベースとテーブルを設定
データベースとテーブル欄で作成したものを選び、選択ボタンをクリック
[迅速な分析のために SPICE へインポート] を選択し、 [Visualize] をクリックします
インポートが完了したら準備完了です
- データの可視化
フィールドリストやビジュアルタイプの好きなものを選び、データが可視化されていることを確認します
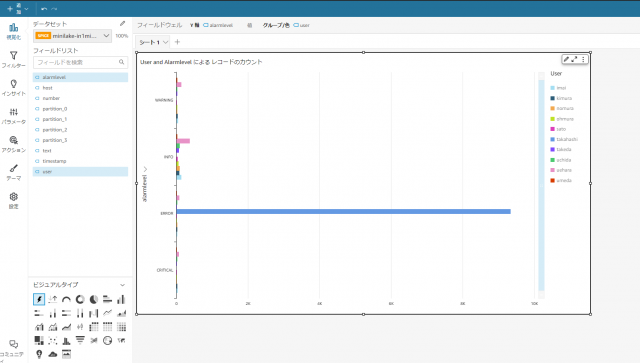
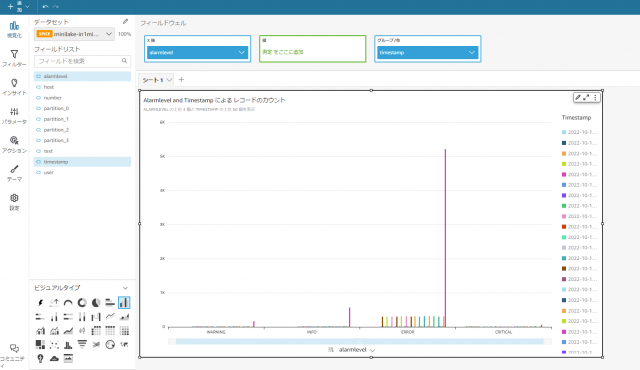
データの可視化がされていることが確認できました。
まとめ
今回データを分析・可視化を行う基盤の構築を行いました。膨大なデータを収集・分析し可視化させるBIツール(QuickSight)は、わかりやすく自動でデータを集計・レポーティングしてくれるサービスで今後も必要とされるサービスなので、今後も学習していきたいと思います。
参考リンク: データレイクハンズオン ・lab1→lab4