



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeはフルマネージド型の機械学習サービスで、用意したデータをもとにユーザーへのおすすめ商品・情報を生成します。
おすすめ商品をメルマガやサイドバーで提供したい場合、Personalizeに用意されているAPIを利用します。しかし、ユーザー数が多くなり、短時間に大量のAPIが利用されるとスループットの制限やリクエストレートの限界に触れ、Personalizeのレスポンスが遅くなる場合があります。
メルマガでおすすめ商品情報の提供する際には、リアルタイム性を必要としないかと思いますので、ぜひAmazon Personalizeの機能のひとつ"バッチ推論ジョブ"を使ってみましょう。
今回の記事では、Amazon Personalizeのバッチ推論ジョブの概要やメリット、使い方を紹介します。
Amazon Personalizeのバッチ推論ジョブを使ってみる
■バッチ推論ジョブとは
Amazon Personalizeのバッチ推論ジョブ(batch inference job)は、大量のアイテムやユーザーに対して一括で推薦を生成する機能です。
- 大規模なデータセット: バッチ推論は大量のユーザーまたはアイテムに対して一括で推薦を行うため、大規模なデータセットを扱う際に適しています。
- 非同期処理: 推薦はバックグラウンドで非同期に処理され、結果はS3バケットに保存されます。
- カスタマイズ可能: ユーザーやアイテムの特定のグループに対してカスタマイズされた推薦を生成するためのフィルタリングやパラメータの調整が可能です。
●バッチ推論ジョブのメリット
バッチ推論ジョブのメリットは3つあります。
- 効率性: 大量の推薦を一度に処理できるため、時間とリソースを節約できます。
- 拡張性: データの量が増加しても、バッチ処理能力によってスムーズに対応できます。
- コスト効率: 非同期処理により、リアルタイムAPIの使用に比べてコストを抑えることができます。
■バッチ推論ジョブ作成ハンズオン
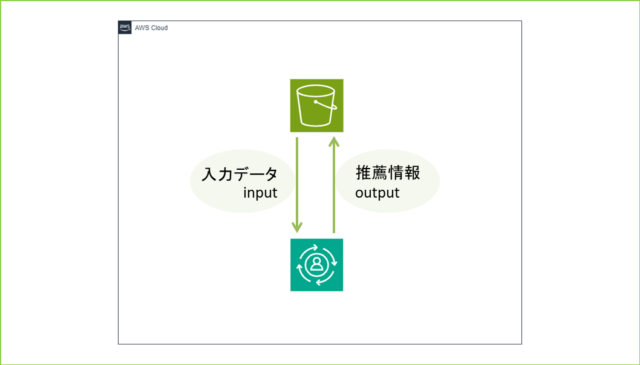

●必要な前提条件(AWSアカウント、データセットなど)
今回のハンズオンの前提条件は以下の通りです。
- Personalizeソリューション作成済み
ソリューションの作成はこちらを参考にしてください。
1000件以上のインタラクションデータさえあればすぐに作成できるかと思います。わたしは今回ユーザー数50、アイテム数500、インタラクション10,000件分のデータをインポートし、ソリューションを作成しました。
●S3バケット準備
バッチ推論ジョブ作成には入力データと作成後の出力先が必要です。
事前にS3バケットの作成、もしくは既存のバケットにフォルダを作成しておきましょう。
今回はPerosonalizeのデータセットで利用しているS3バケットを利用します。同じバケットであればソリューション作成時に選択したIAMロールがそのまま使えます。
※もしS3バケットを新たに作成して使う場合は、PersonalizeとS3の権限が付与されたロールを準備してください。
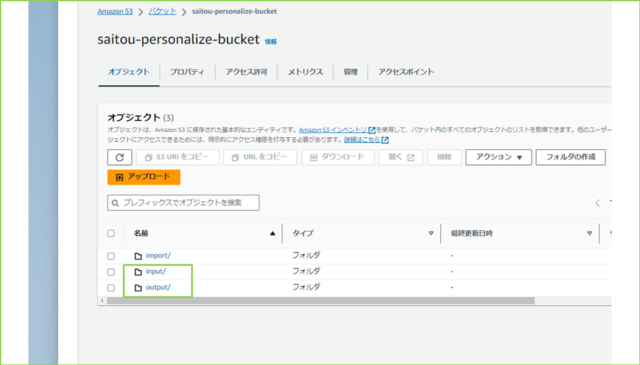
↓S3バケットに[input]と[output]のフォルダを作っておきます。
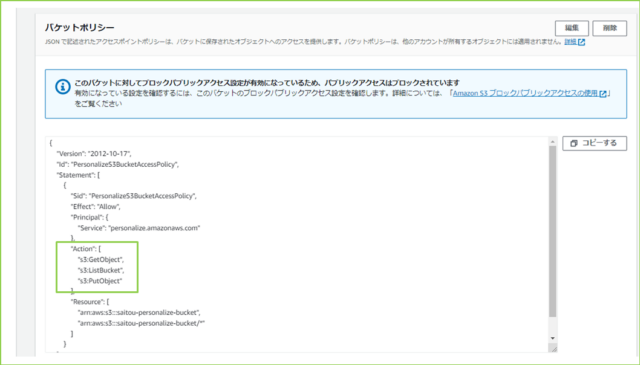
↓アクセスポリシーも確認しておきましょう。[読み込み]はもちろん、[書き込み]も必要です。
●入力データアップロード
バッチ推論ジョブ実行には、推薦情報を生成するためのユーザーIDがまとめれた入力データが必要です。形式はJSON Linesで、キーも"userId"と仕様が決まっています。USER_ID
でもなく、useridでもなく、キャメルケースのuserIdです。
ダミーデータを作成し、S3バケットのinput/にアップロードしましょう。
↓ダミーデータ作成は以下のコードを利用してください。ユーザー数50のダミーデータがjsonl形式で作成されます。
"""ユーザーリスト作成"""
import pandas as pd
import json
# ユーザー数を定義
num_users = 50
# ダミーデータの作成
users = {
"userId": list(range(1, num_users + 1))
}
# pandasのDataFrameに変換
df = pd.DataFrame(users)
# userIdのデータ型を文字列型に変換
df['userId'] = df['userId'].astype(str)
# JSON Lines形式でファイルに保存
with open('userlist_dummy_data.jsonl', 'w') as file:
for _, row in df.iterrows():
json.dump(row.to_dict(), file)
file.write('\n')
print("userlist_dummy_data.jsonl ファイルを作成しました。")
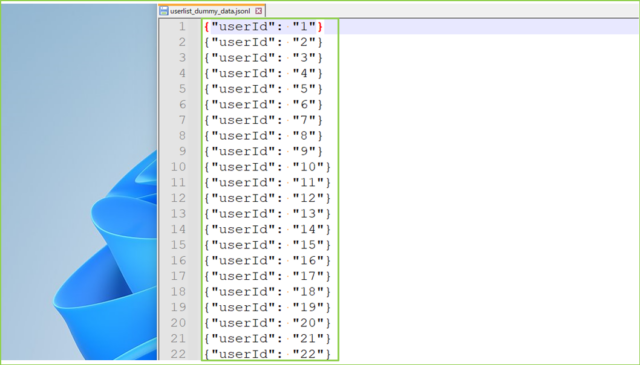
↓コードを実行すると、つぎのようなデータができます。
↓作成た入力データを、S3バケットのinput/にアップロードします。
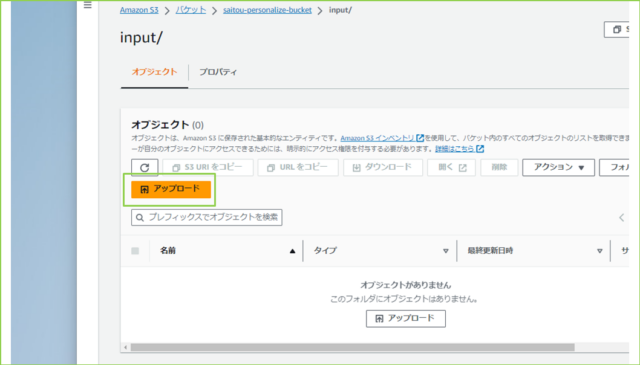
↓
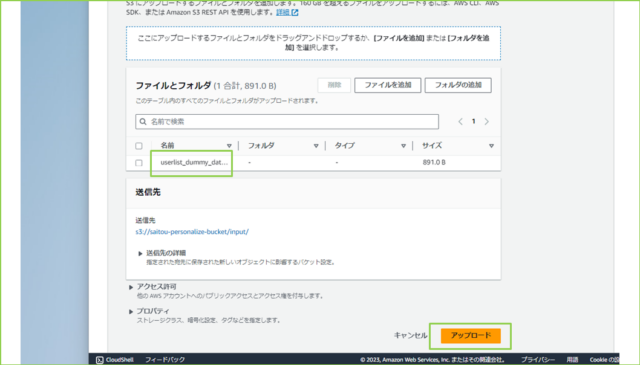
↓
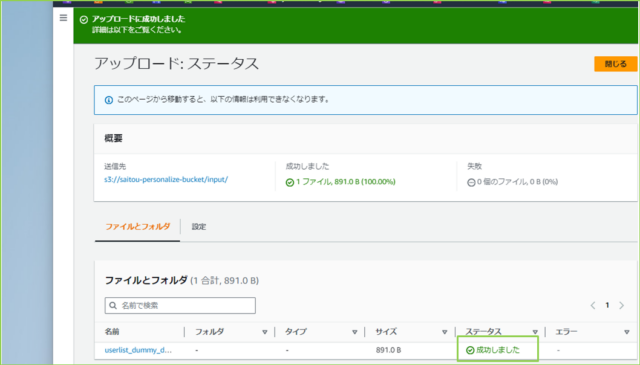
アップロードが成功しましたら、準備は完了です。
●バッチ推論ジョブ作成
それでは、本題のバッチ推論ジョブを作成していきます。
↓サービス検索窓で[Amazon Personalize]を検索し、[Amazon Personalize]をクリックします。
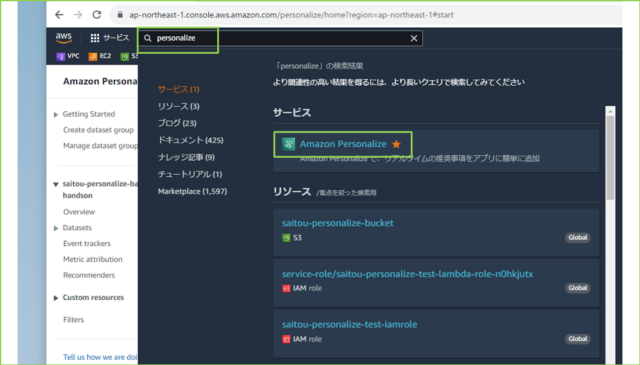
↓左のナビゲーションペインから[Manage dataset groups]をクリックし、利用するデータセットグループをクリックします。
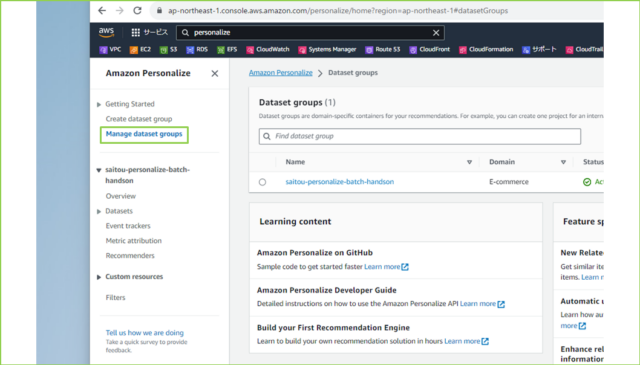
↓つづいて、左のナビゲーションペインから[Solutions and recipes]をクリックして、ソリューションの[status]が[Active]であることを確認します。
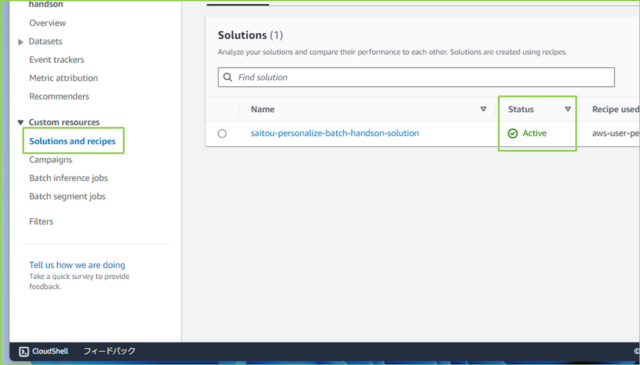
↓左のナビゲーションペインから[Batch inference jobs]をクリックします。
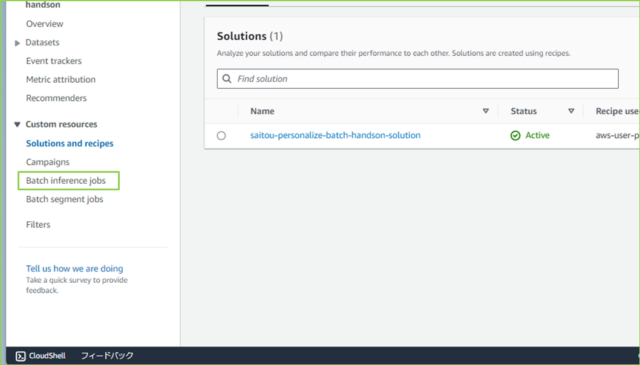
↓[Create batch inference job]をクリックします。
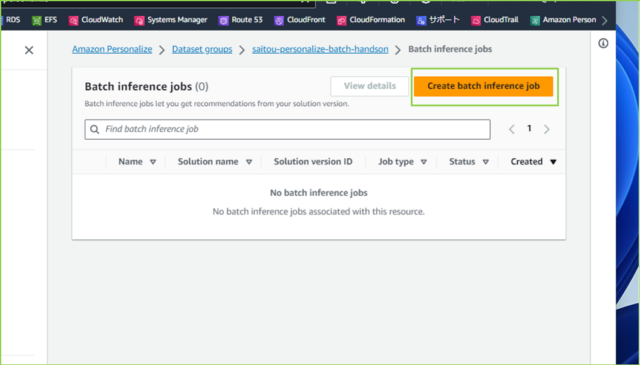
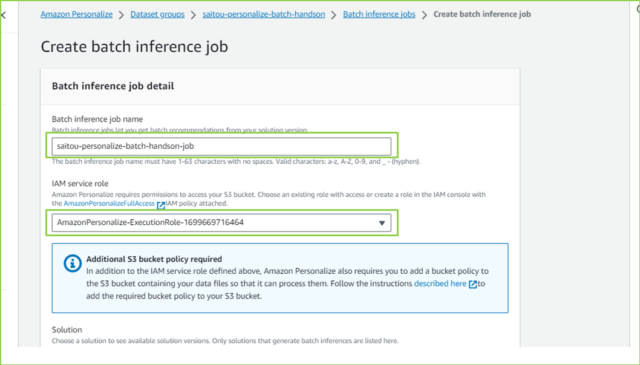
↓各項目を入力していきましょう。設定値は以下の通りです。自身の環境に合わせて入力してください。
| 項目 | 設定値 |
|---|---|
| Batch inference job name | 任意 |
| IAM service role | ソリューションと同じ |
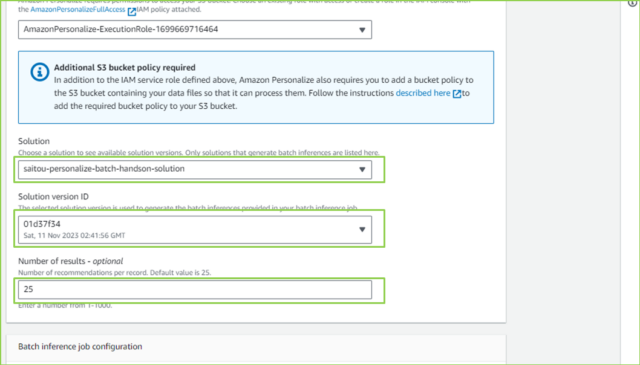
| Solution | 任意 |
| Solution version ID | 任意 |
| Number of results | 25 |
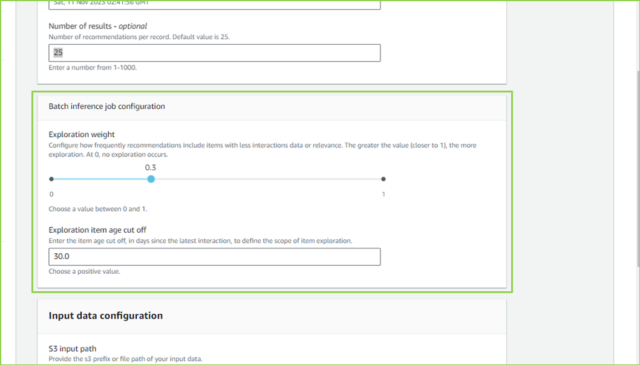
| Batch inference job configuration | デフォルト |
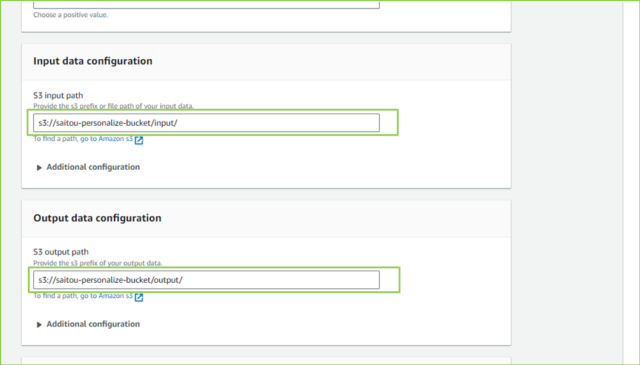
| S3 input path | 入力データをアップロードしたフォルダパス(/input/) |
| S3 output path | 出力先パス(/output/) |
↓
↓
↓
↓入力が完了したら、[Create batch inference job]をクリックします。
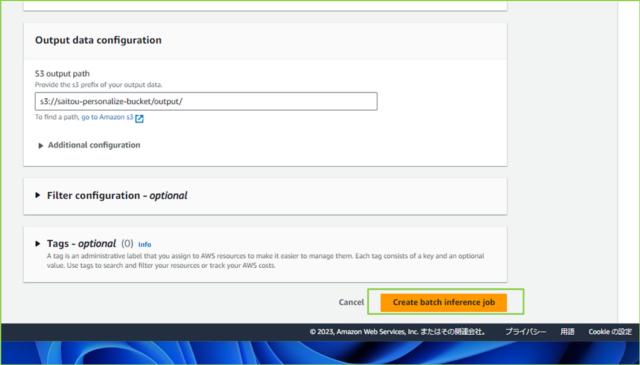
↓[status]が[Active]になるまで待ちましょう。
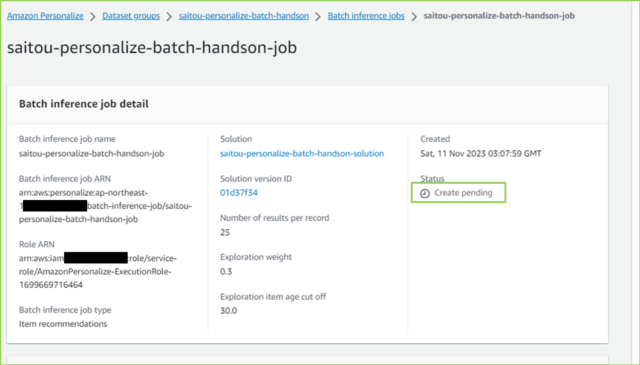
↓
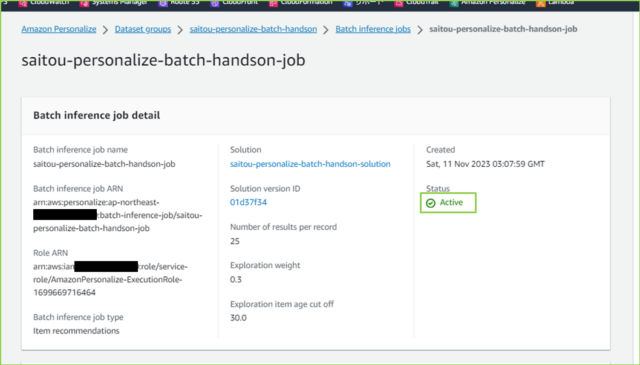
↓[Active]になりましたので、推薦情報の生成が完了です。データ量によりますが、何十万件とあると1時間くらいかかります。指定したS3バケットを見てみましょう。
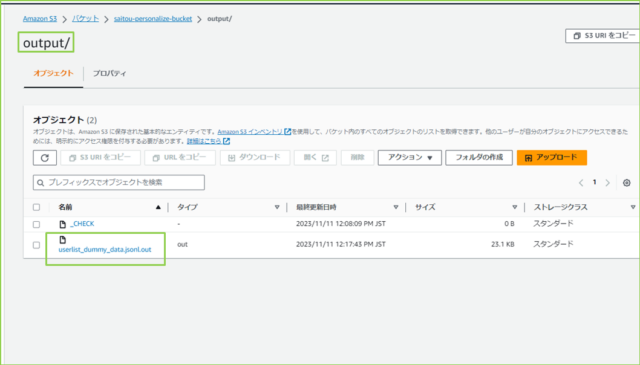
ファイルが出力されていますね。
↓中身を確認してみましょう。
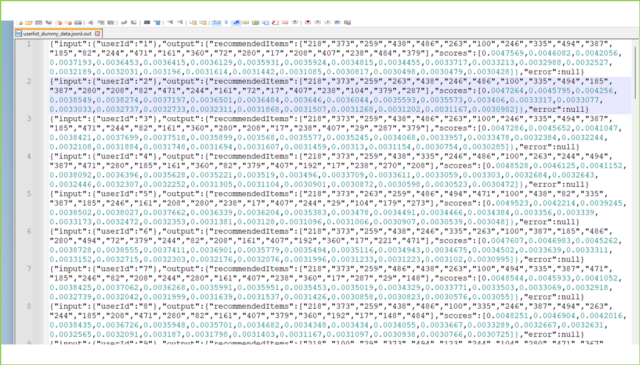
{"input":{"userId":"1"},"output":{"recommendedItems":["218","373","259","438","486","263","100","246","335","494","387","185","82","244","471","161","360","72","280","17","208","407","238","484","379"],"scores":[0.0047569,0.0046082,0.0042056,0.0037193,0.0036453,0.0036415,0.0036129,0.0035931,0.0035924,0.0034815,0.0034455,0.0033717,0.0033213,0.0032988,0.0032527,0.0032189,0.0032031,0.003196,0.0031614,0.0031442,0.0031085,0.0030817,0.0030498,0.0030479,0.0030428]},"error":null}
{"input":{"userId":"2"},"output":{"recommendedItems":["218","373","259","263","438","246","486","100","335","494","185","387","280","208","82","471","244","161","72","17","407","238","104","379","287"],"scores":[0.0047264,0.0045795,0.004256,0.0038549,0.0038274,0.0037197,0.0036501,0.0036484,0.003646,0.0036044,0.0035593,0.0035573,0.003406,0.0033317,0.0033077,0.0033033,0.0032737,0.0032733,0.0032311,0.0031868,0.0031507,0.0031268,0.0031202,0.0031167,0.0030982]},"error":null}
{"input":{"userId":"3"},"output":{"recommendedItems":["218","373","259","438","486","263","100","246","335","494","387","185","471","244","82","161","360","280","208","17","238","407","29","287","379"],"scores":[0.0047286,0.0045652,0.0041047,0.0038421,0.0037699,0.0037518,0.0035899,0.003568,0.0035577,0.0035245,0.0034068,0.0033957,0.0033478,0.0032384,0.0032244,0.0032108,0.0031884,0.0031748,0.0031694,0.0031607,0.0031459,0.00313,0.0031154,0.0030754,0.0030285]},"error":null}
ユーザーひとつ当たり、おすすめ情報が25件生成されています。scoreも入っていますね。
今回のハンズオンは以上です。
まとめ:Amazon Personalizeのバッチ推論ジョブを使ってみる【ハンズオン】
Webアプリケーションでサービスを提供する場合、クリック率やコンバージョン率を上げるのは重要なことです。
Amazon Personalizeはユーザーの"ほしい"を叶えてくれるサービスで、今回紹介した"バッチ推論ジョブ"は多くのユーザーの"ほしい"を効率的に生成することができます。ぜひ使ってみてください。
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
AIや機械学習のレコメンデーションサービスについて知りたい方は、ぜひ協栄情報にお問い合わせください。
https://www.cp-info.co.jp/contact/
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
参考リンク:AWS公式ドキュメント
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/
■Amazon Personalize学習用ダミーデータをPythonで作ってみた(齊藤弘樹)
https://cloud5.jp/saitou-personalize-create-dammydata/
■Amazon Personalizeのエラーを解決!各カラムのデータ型を調べる方法(齊藤弘樹)
https://cloud5.jp/saitou-check-data-type/
■AWS Lambdaを使ってAmazon Personalizeの推薦情報をCSVでS3にエクスポートする方法(齊藤弘樹)
https://cloud5.jp/saitou-personalize-attribute-recommendation/