



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeはフルマネージド型の機械学習サービスで、用意したデータをもとにユーザーへのおすすめ商品・情報を生成します。
おすすめ情報が利用される状況は、Eコマース・コンテンツ配信・メディア・広告など、多岐にわたりますよね。
今回の記事ではAmazon Prsonalizeが生成する推薦情報をWebアプリケーションでユーザーごとに表示してみるハンズオンを紹介します。
Webアプリケーションに関しては、初心者の方でも扱いやすいFlaskを利用しますのでご安心ください。
↓ボリュームが多いため、Part1とPart2に分けてあります。
- Amazon EC2にFlaskアプリを構築し、Personalizeから推薦情報を受け取ってみるPart1
- Amazon EC2にFlaskアプリを構築し、Personalizeから推薦情報を受け取ってみるPart2(後日投稿予定)
FlaskアプリでPersonalizeのおすすめ情報を表示
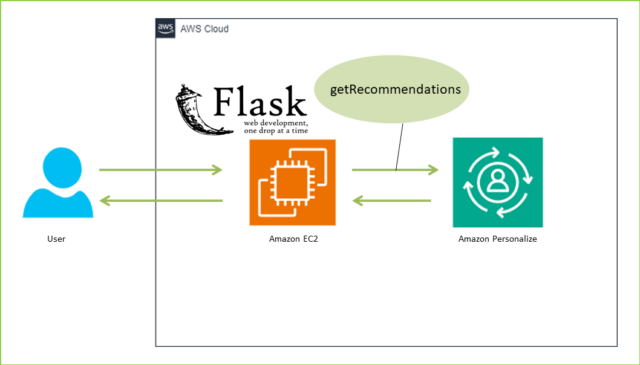

Personalizeのハンズオンをいろいろやりましたが、"ユーザーにどう届ければいいか"の部分を紹介する記事があまりありませんでした。
この記事では、「Eコマースサイトでユーザーにおすすめの果物を2つ紹介する」を想定して、AWSクラウド上にWebアプリとAmazon Personalizeを作成していきます。
↓できあがりイメージは下の画像です。サイトデザインやログイン仕様は無視しています。
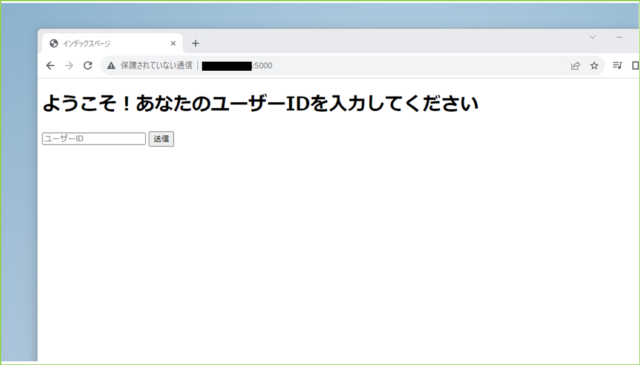
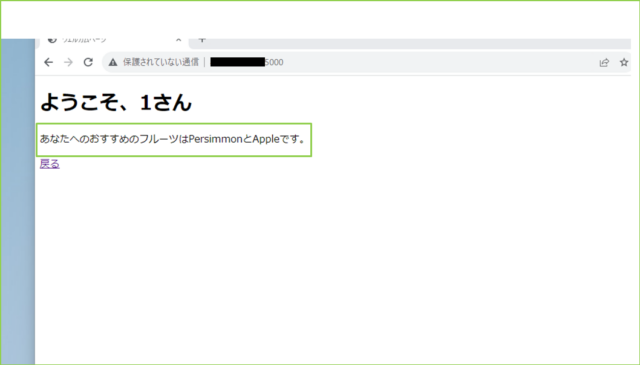
↓ユーザーIDを入力すると、PersonalizeのAPIを使ってユーザーにおすすめのItemIDを取得し、ItemIDに基づいたデータベースに登録されたフルーツを2つ表示します。
■必要な前提知識と準備
今回のハンズオンは以下の前提知識が必要です。できるだけ初心者の方でも迷わずにできるように書きましたが、エラーがおきたときの対処など含めて前提知識があったほうがスムーズにハンズオンができるかと思います。
- AWSアカウントのセットアップ
- VPC,SecurityGroups,EC2の基本知識
- Amazon Personalizeについての基本知識
- 必要なツールとライブラリ(Flask, Boto3など)
【構築の流れ】
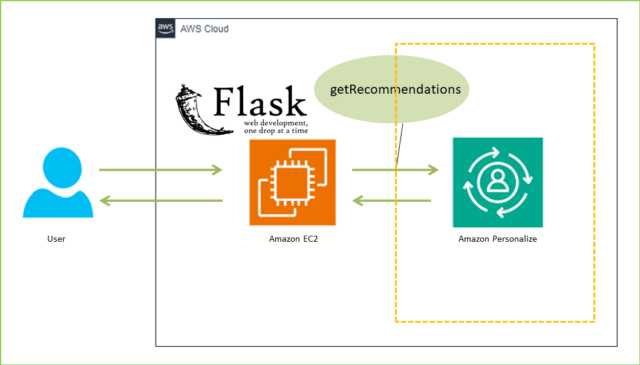
- Amazon S3作成
↓
- Amazon Personalize
■ダミーデータ作成
まずはPesonalizeにインポートするダミーデータを作成します。Personalizeから推薦情報を得るためには、インタラクションデータが最低限あれば問題ありません。
以下のコードを利用し、インタラクションデータのダミーデータを作成しましょう。ユーザー数とレコード数は増やしても大丈夫ですが、アイテム数に関しては30でお願いします。理由はFlaskアプリのデータベースに登録するフルーツが30件のためです。
"""インタラクションデータ作成"""
import pandas as pd
import random
import time
# レコード数を定義
num_records = 10000
# パラメータ設定
user_id_range = 1000 # USER_IDの範囲(1から500までの整数)
item_id_range = 30 # ITEM_IDの範囲(1から1000までの整数)
event_types = ["click", "view", "buy", "save"]
# ダミーデータの生成
user_ids = [random.randint(1, user_id_range) for _ in range(num_records)]
item_ids = [random.randint(1, item_id_range) for _ in range(num_records)]
timestamps = [int(time.time()) for _ in range(num_records)]
event_types_list = [random.choice(event_types) for _ in range(num_records)]
# pandasのDataFrameに変換
df = pd.DataFrame({
"USER_ID": user_ids,
"ITEM_ID": item_ids,
"TIMESTAMP": timestamps,
"EVENT_TYPE": event_types_list
})
# CSVファイルに保存
df.to_csv('interaction_dummy_data.csv', index=False)
print("interaction_dummy_data.csv ファイルを作成しました。")
IDEツールがある方はそちらを利用するか、お使いのローカルPCにPythonがインストールされていれば、Pandasライブラリをpipでインストールするだけでダミーデータを作成できます。
↓コードをメモ帳にペーストし、[create_dummy_data.py]というファイル名でダウンロードフォルダに保存します。
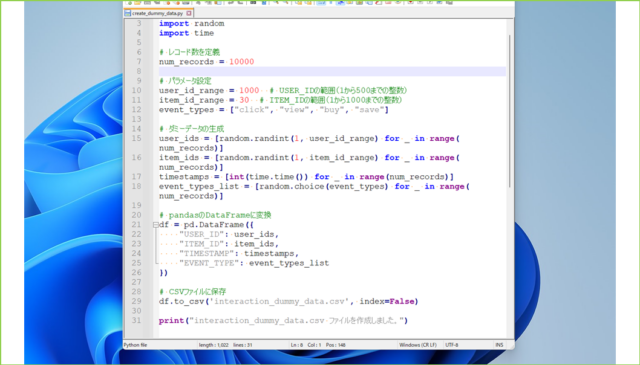
↓
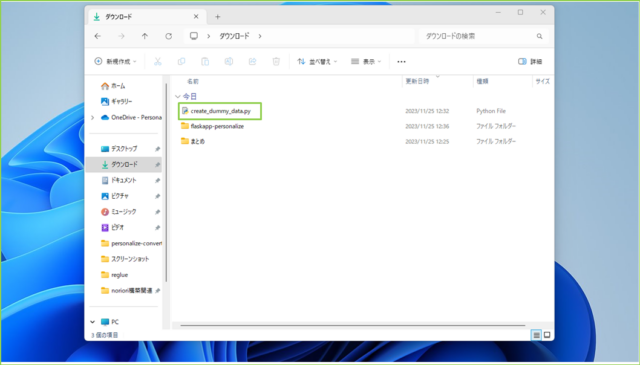
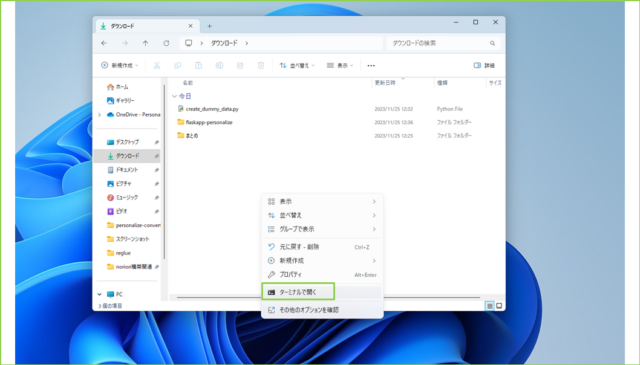
↓ダウンロードフォルダ内でマウスポインタを合わせ、右クリックから[ターミナルで開く]をクリックします。
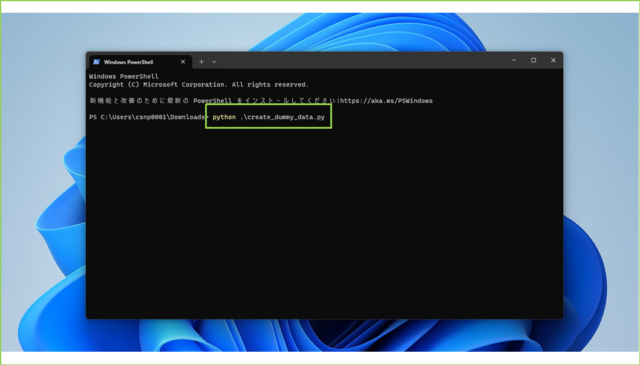
↓次のコマンドを実行します。
python .\create_dummy_data.py
↓ダウンロードフォルダにダミーデータが作成されます。
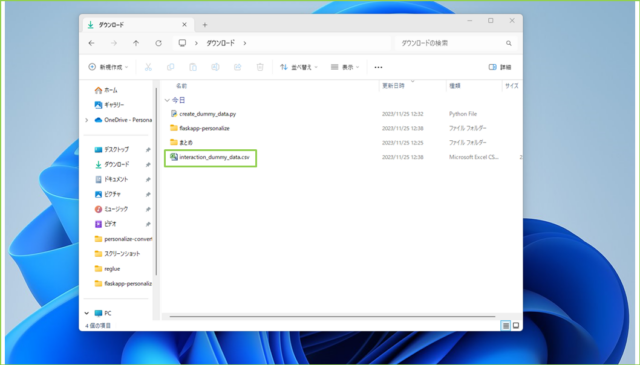
↓
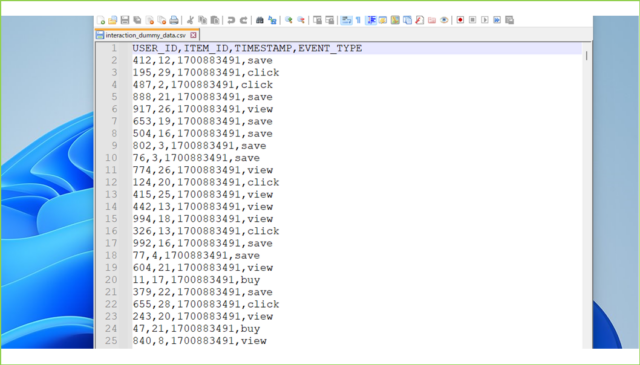
ダミーデータの作成は以上です。
■S3バケット作成
作成したダミーデータを保存するS3バケットを作成します。
↓AWSにログインし、サービス検索窓で[S3]を検索します。
↓[バケット]から[バケットを作成]をクリックします。
↓バケット名は任意の名前で入力し、AWSリージョンは自身の環境に合わせて設定してください。特に要件がなければ、東京リージョンを選択しましょう。
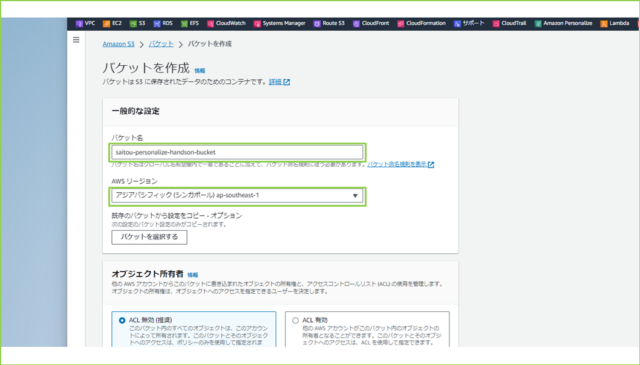
↓[バケットを作成]をクリックします。
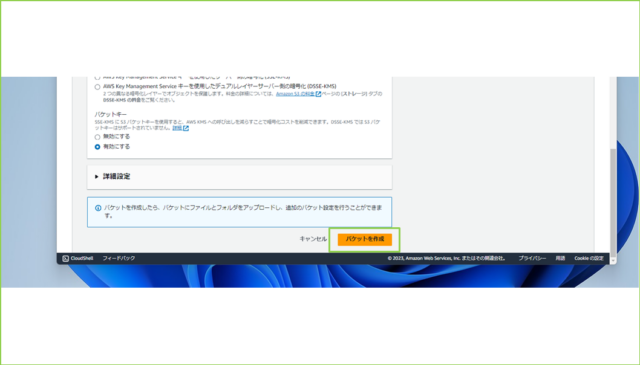
↓作成したバケットをクリックます。
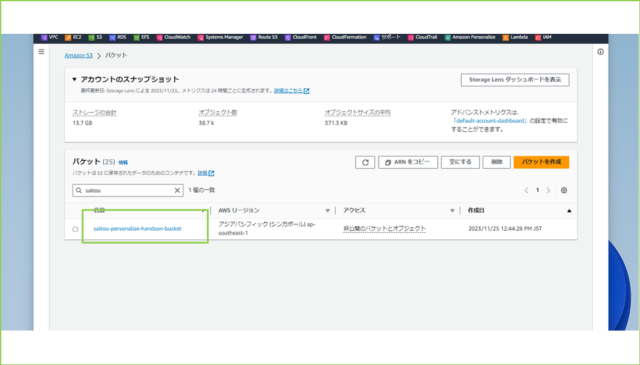
↓[アクセス許可]タブをクリックし、[バケットポリシー]の[編集]をクリックします。
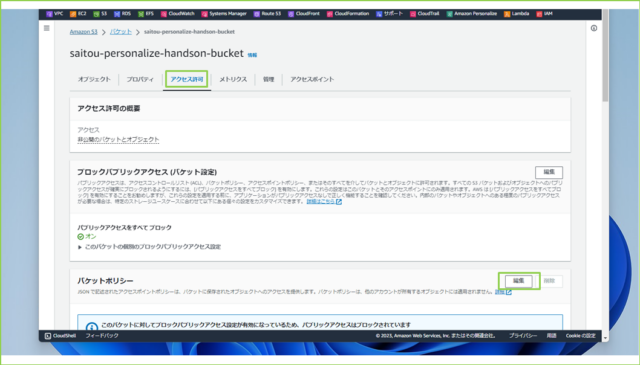
↓以下のポリシーで"YOUR_BUCKET_NAME"部分2カ所を自身が作成したS3バケット名に修正して、JSONドキュメントを貼り付けます。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::YOUR_BUCKET_NAME",
"arn:aws:s3:::YOUR_BUCKET_NAME/*"
]
}
]
}
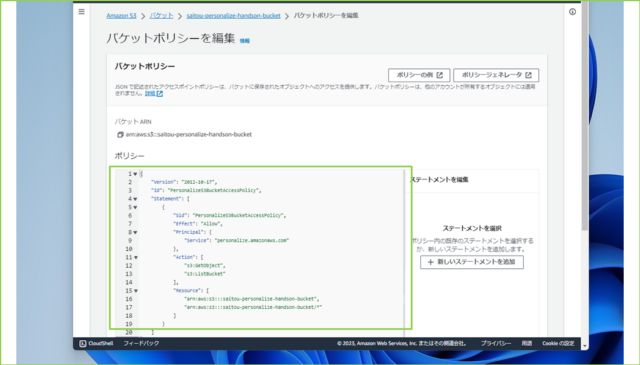
↓[変更の保存]をクリックします。
↓つづいて、[オブジェクト]タブをクリックし、[フォルダの作成]をクリックします。
↓[フォルダ名]を[interactions]とし、[フォルダの作成]をクリックします。
interactions
↓作成したフォルダをクリックします。
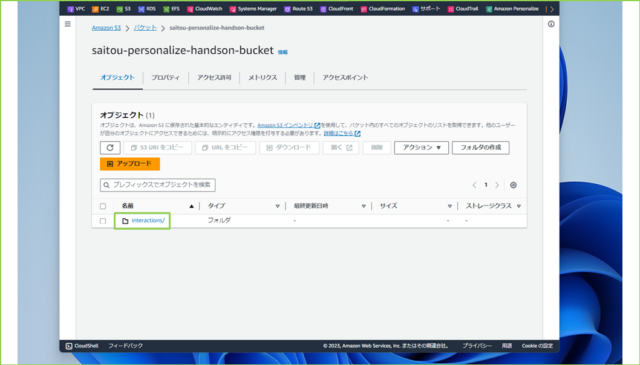
↓[ファイルを追加]をクリックします。
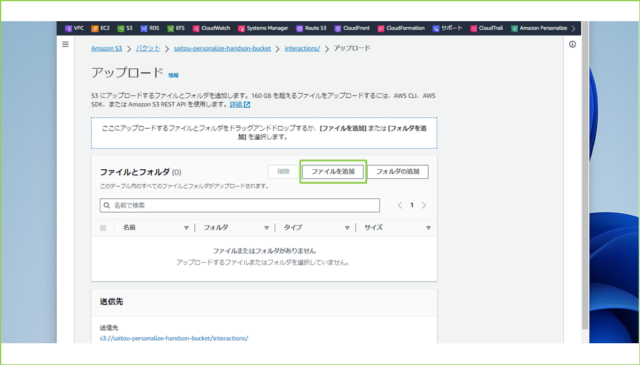
↓作成したダミーデータを追加し、[アップロード]をクリックします。
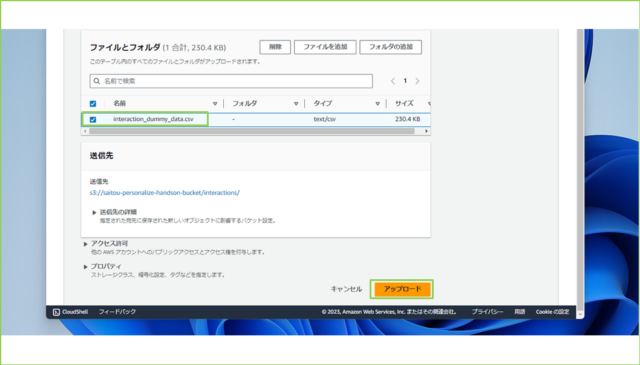
↓
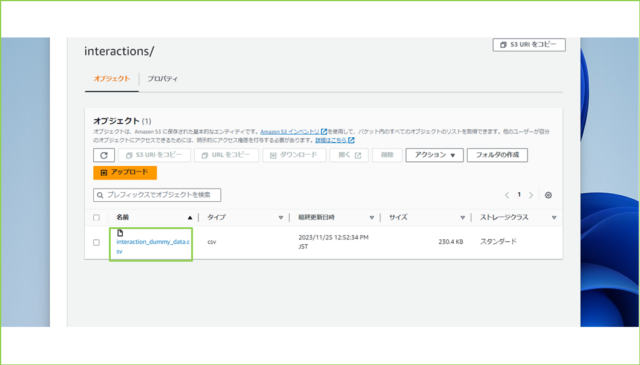
S3バケットの作成は以上です。
■Amazon Personalize作成
おすすめ情報を生成するAmazon Personalizeソリューション・キャンペーンを作成していきます。
↓サービス検索窓で[Amazon Personalize]を検索し、クリックします。
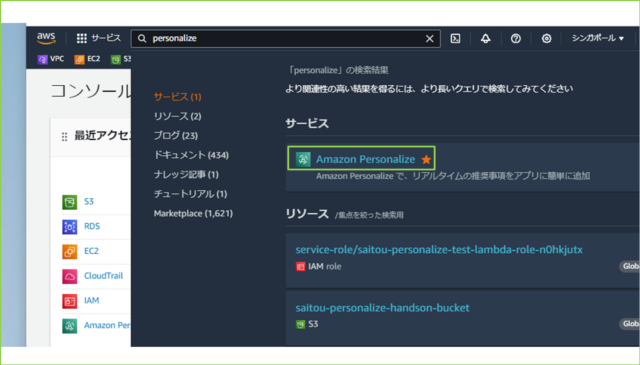
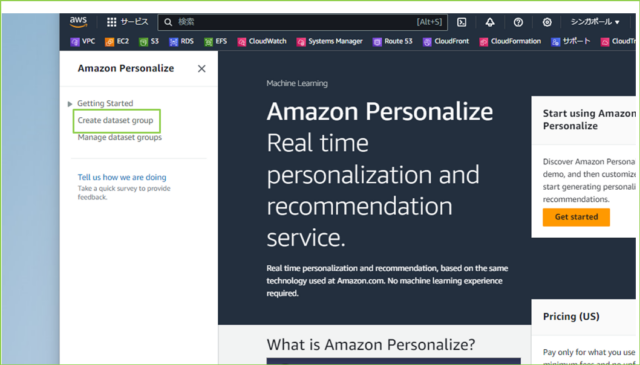
↓[Create dataset group]をクリックします。
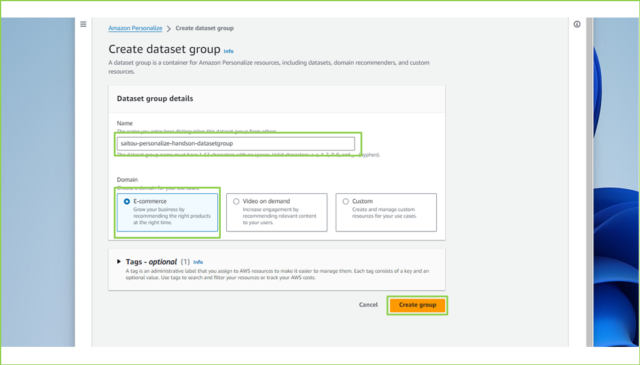
↓[Name]は任意で入力していいただき、[Domain]を[E-commerce]を選択し、[Create group]をクリックします。
saitou-personalize-handson-datasetgroup
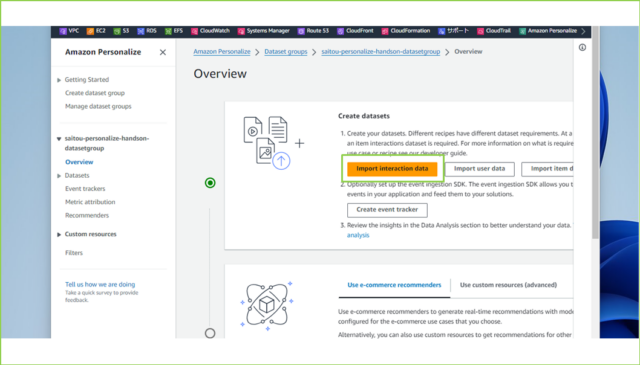
↓Pesonalizeを簡単に作成するためのフローが出てきます。[Create datasets]で[Import interaction data]をクリックします。
↓[Import data directly into Amazon Personalize datasets]を選択し、[Next]をクリックします。
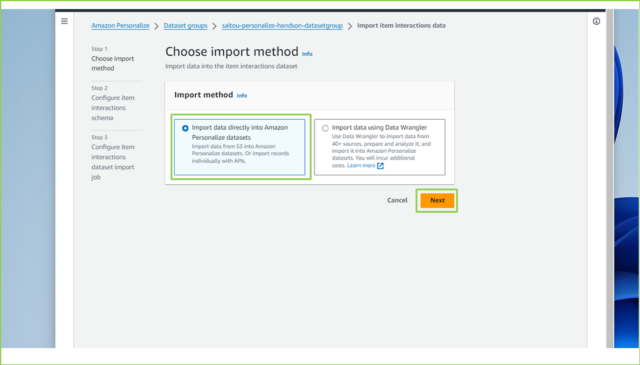
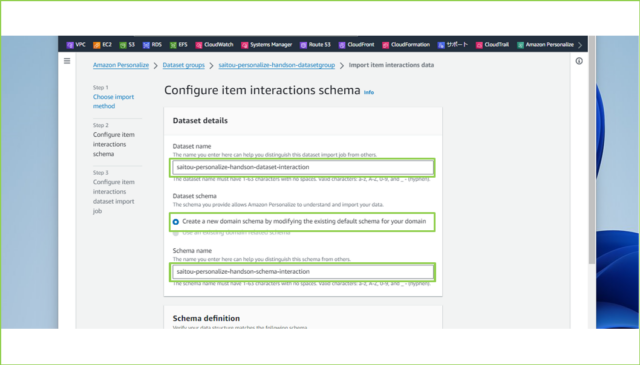
↓[Dataset name]は任意の名前を入力し、[Dataset schema]は[Create a new domain schema by modifying the existing default schema for your domain]を選択します。[Schema name]も任意の名前を入力してください。
saitou-personalize-handson-dataset-interaction
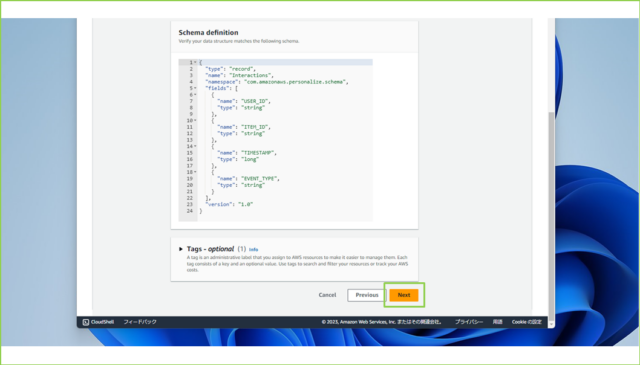
↓[Schema definition]はそのままで、[Next]をクリックします。
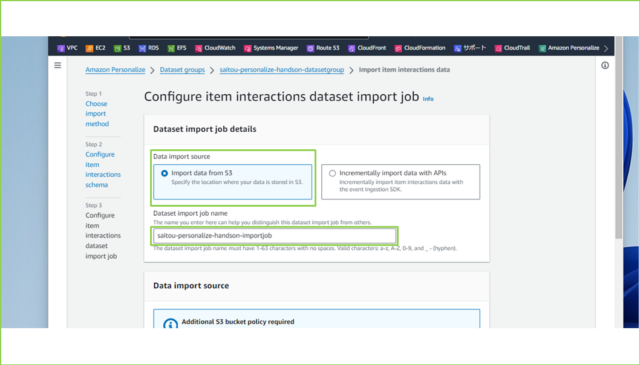
↓[Data import source]は[Import data from S3]を選択し、[Dataset import job name]は任意の名前を入力してください。
saitou-personalize-handson-importjob
↓[Data location]は作成したS3バケットのプレフィックス/interactions/を入力します。
s3://saitou-personalize-handson-bucket/interactions/
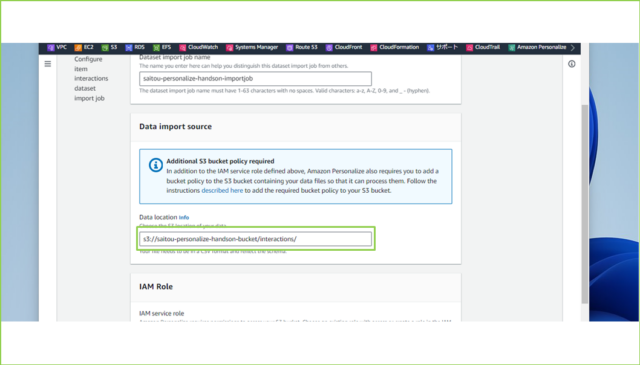
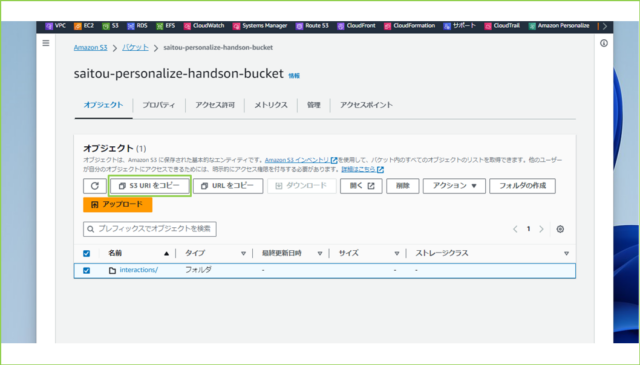
↓S3バケットでコピーできます。
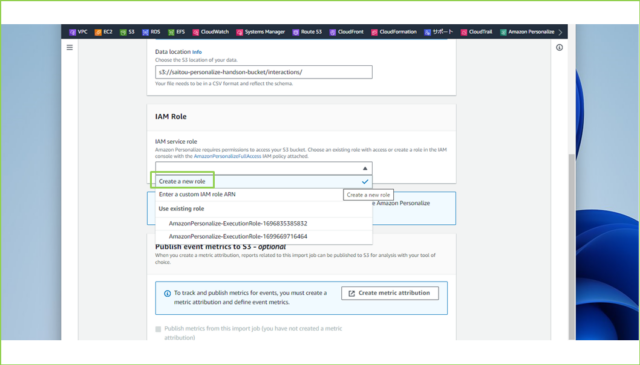
↓Personalizeへの権限付与の設定します。[IAM service role]の[Create a new role]をクリックします。
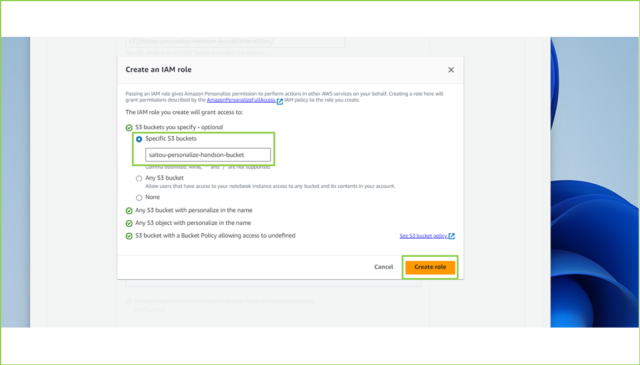
↓[Specific S3 buckets]で作成したS3バケット名を入力し、[Create role]をクリックします。
↓[Start import]をクリックします。
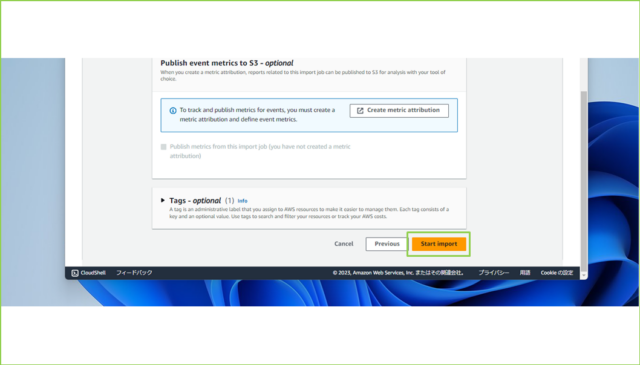
↓ステータスが[create pending]から[active]になるのを待ちましょう。レコード数にもよりますが、5分ほどでActiveになるかと思います。
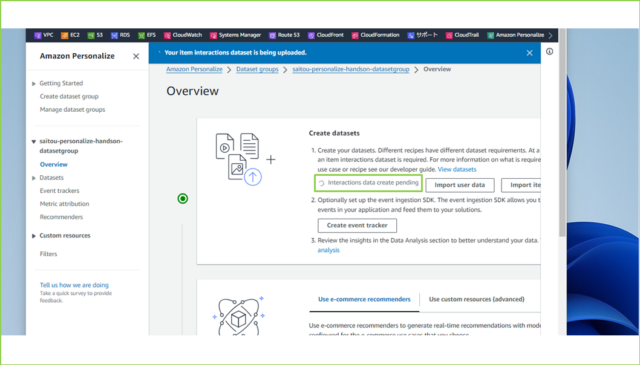
↓
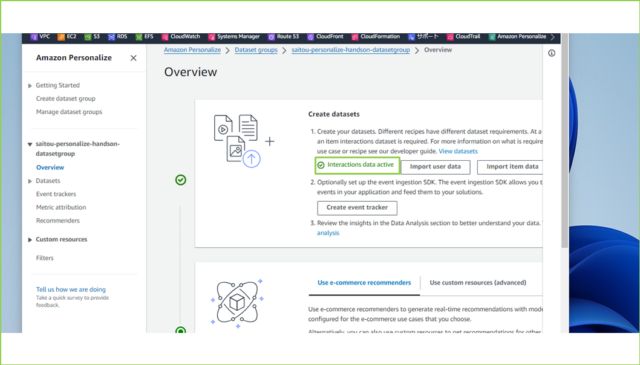
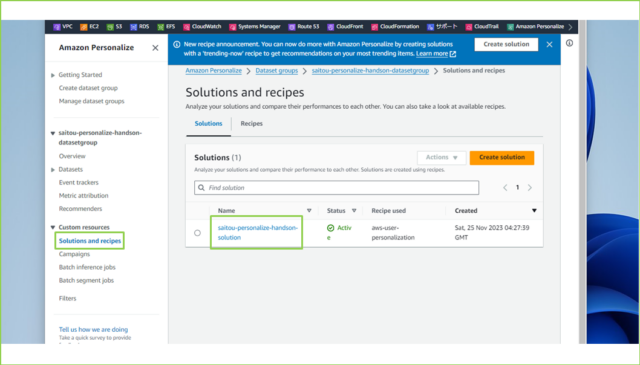
↓つづいて、フローの中段で[Use custom resources (advanced)]タブをクリックし、[Create solution]をクリックします。
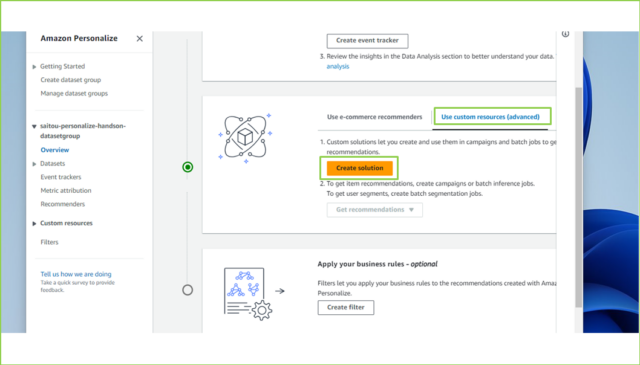
↓[Solution name]は任意の名前を入力し、[Solution type]は[Item recommendation]を選択、[Recipe]は[aws-user-personalization]を選択してください。[Next]をクリックします。
saitou-personalize-handson-solution
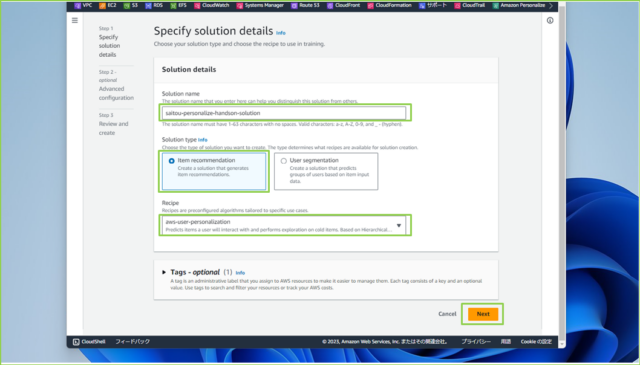
↓[Advanced configuration – optional]はインポートしたデータをより細かくチューニングしてトレーニングさせる設定部分です。今回はデフォルトでいくので、[Next]をクリックします。
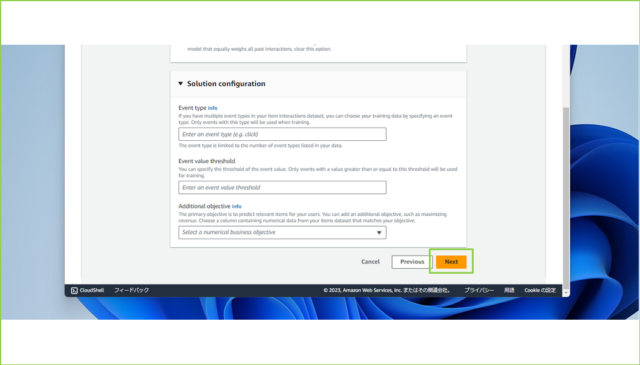
↓[Review and create]で入力した内容を確認し、[Create solution]をクリックします。
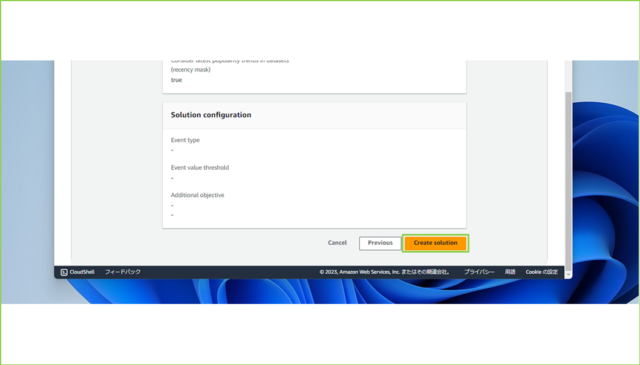
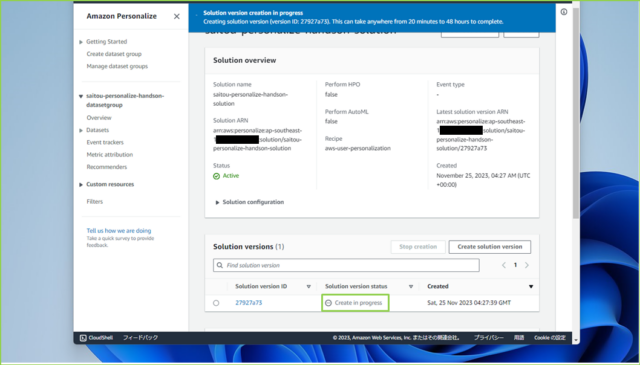
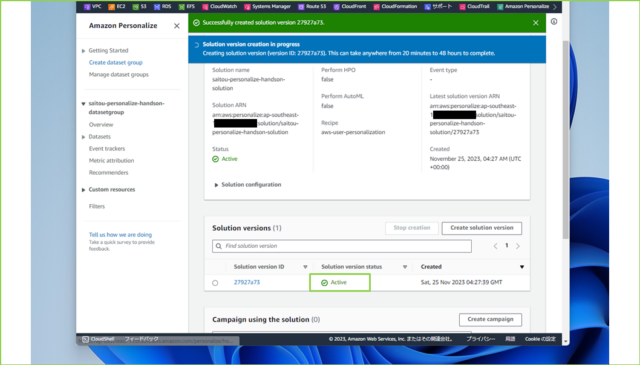
↓作成中から[Active]になるのを待ちましょう。20分ほどかかりますので、ソリューションの[Solution version status]で都度確認してください。
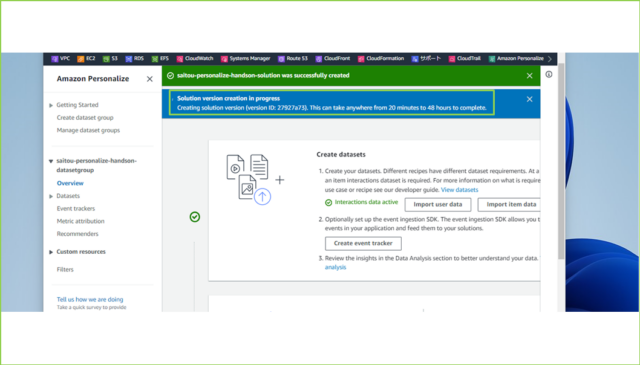
↓
↓
↓
↓さいごにトレーニングしたモデルをAPIで扱えるようにキャンペーンを作成します。[Campaigns]から[Create campaign]をクリックします。
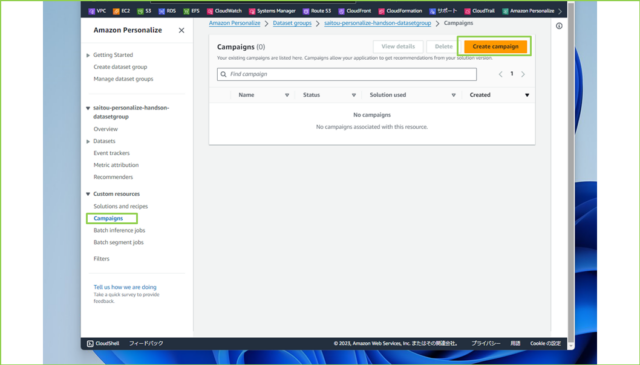
↓[Campaign name]は任意の名前を入力し、[Solution]は作成したソリューションを選択、[Solution version ID]は自動で最新バージョンが選択されるのでそのままです。
saitou-personalize-handson-campaign
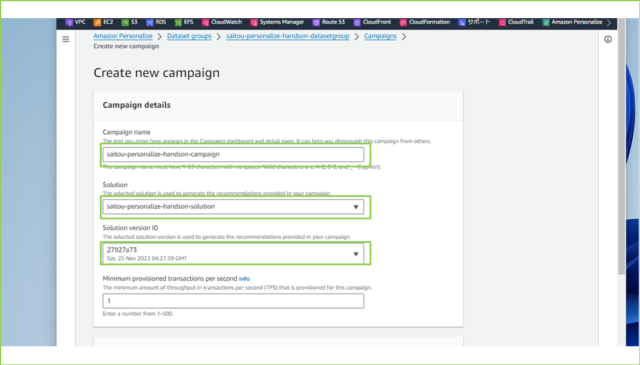
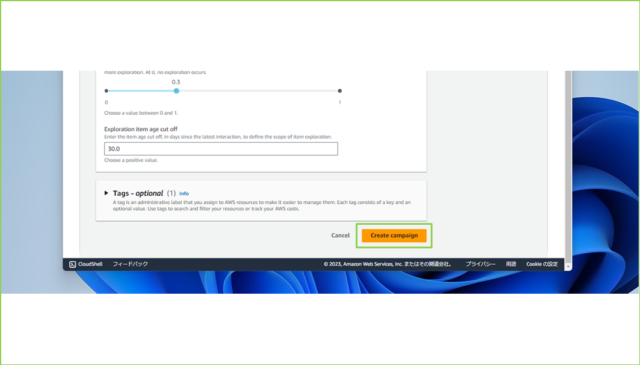
↓そのほかの設定は、推薦するアイテムの探索範囲の設定ですので、こちらもデフォルトのまま、[Create campaign]をクリックします。
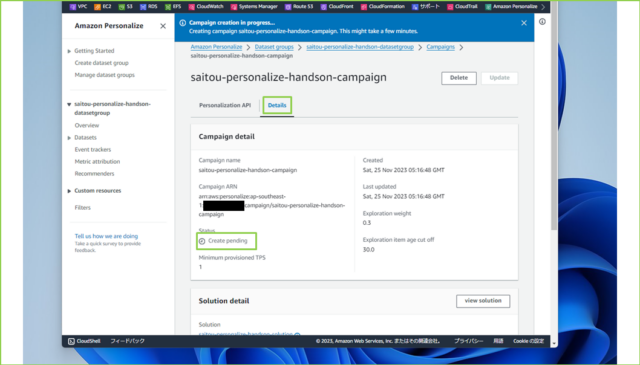
↓こちらもソリューション同様、すこし時間がかかります。[Details]の[Status]で[Active]になるのを待ちましょう。
↓
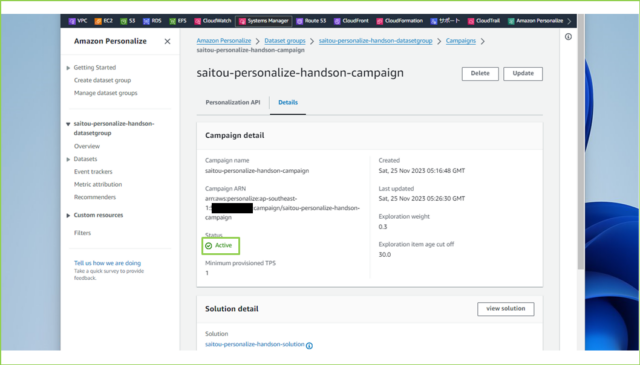
↓[Active]になりましたら、推薦情報が取得できるか確認します。[Personalization API]タブをクリックし、[Test campaign results]の[User ID]欄に適当な数字を入力、[Get recommendations]をクリックします。
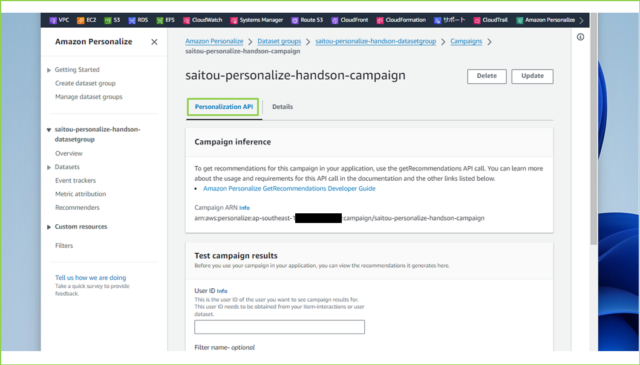
↓
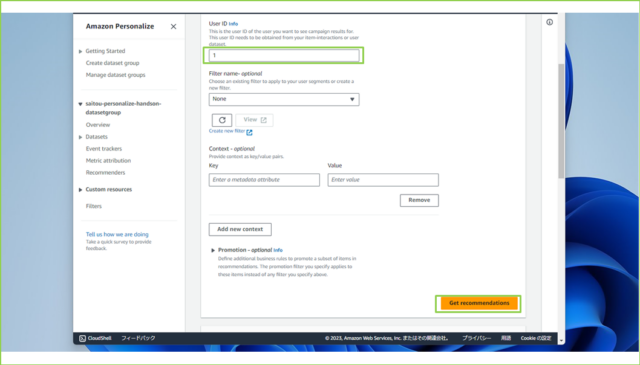
↓画面下に25件分の推薦情報が返ってくるはずです。Scoreは相対的な尺度で表示され、25件分表示した場合はすべて足して"1"になるようになっています。1,000件取得した場合は、ひとつ当たりのScoreはかなり小さくなります。
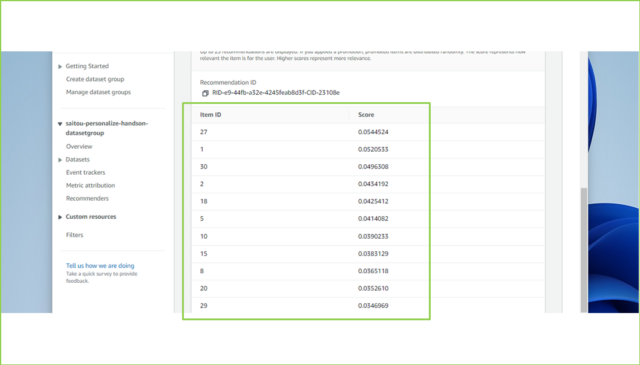
私の場合は[User ID]が[1]に対し、[27]や[1]、[30]が返ってきました。ダミーデータの各パラメータはランダムに生成されているので、[User ID]を[1]と入力しても、わたしの結果とは異なるかと思います。ためしに色々なIDを入力してみましょう。
Amazon Personalizeの作成は以上です。
まとめ
Part1はここまでです。Part2ではAmazon Ec2のインスタンスを起動し、Flaskアプリをデプロイします。Flaskアプリのコードについては、GitHubからFlaskアプリのコードが格納されたリポジトリをクローンしますので、Flaskについて知識がなくても大丈夫です。
Part2は後日投稿しますので、よろしくお願いいたします。
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
AIや機械学習のレコメンデーションサービスについて知りたい方は、ぜひ協栄情報にお問い合わせください。
https://www.cp-info.co.jp/contact/
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
参考リンク:AWS公式ドキュメント
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/
■Amazon Personalize学習用ダミーデータをPythonで作ってみた(齊藤弘樹)
https://cloud5.jp/saitou-personalize-create-dammydata/
■Amazon Personalizeのエラーを解決!各カラムのデータ型を調べる方法(齊藤弘樹)
https://cloud5.jp/saitou-check-data-type/
■AWS Lambdaを使ってAmazon Personalizeの推薦情報をCSVでS3にエクスポートする方法(齊藤弘樹)
https://cloud5.jp/saitou-personalize-attribute-recommendation/