



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeバッチ推論ジョブで生成されるデータはJSON lines形式で出力されます。
既存のソリューションで利用するとなると、少し加工、もしくはファイル形式を変更する必要があるかもしれません。
今回の記事では、Amazon Personalizeバッチ推論ジョブで生成されたJSONファイルを、AWS Lambdaを利用してCSV形式に変換・出力する方法を紹介します。
バッチ推論ジョブで生成されたJSONファイルをCSVファイルにしてみた
バッチ推論ジョブで生成されるJSONファイルはJSON lines形式です。下のようにオブジェクトが一行にまとまっています。
{"input":{"userId":"4638"},"output":{"recommendedItems":["63992","115149","110102","148626","148888","31685","102445","69526","92535","143355","62374","7451","56171","122882","66097","91542","142488","139385","40583","71530","39292","111360","34048","47099","135137"],"scores":[0.0152238,0.0069081,0.0068222,0.006394,0.0059746,0.0055851,0.0049357,0.0044644,0.0042968,0.004015,0.0038805,0.0037476,0.0036563,0.0036178,0.00341,0.0033467,0.0033258,0.0032454,0.0032076,0.0031996,0.0029558,0.0029021,0.0029007,0.0028837,0.0028316]},"error":null}
{"input":{"userId":"663"},"output":{"recommendedItems":["368","377","25","780","1610","648","1270","6","165","1196","1097","300","1183","608","104","474","736","293","141","2987","1265","2716","223","733","2028"],"scores":[0.0406197,0.0372557,0.0254077,0.0151975,0.014991,0.0127175,0.0124547,0.0116712,0.0091098,0.0085492,0.0079035,0.0078995,0.0075598,0.0074876,0.0072006,0.0071775,0.0068923,0.0066552,0.0066232,0.0062504,0.0062386,0.0061121,0.0060942,0.0060781,0.0059263]},"error":null}
{"input":{"userId":"3384"},"output":{"recommendedItems":["597","21","223","2144","208","2424","594","595","920","104","520","367","2081","39","1035","2054","160","1370","48","1092","158","2671","500","474","1907"],"scores":[0.0241061,0.0119394,0.0118012,0.010662,0.0086972,0.0079428,0.0073218,0.0071438,0.0069602,0.0056961,0.0055999,0.005577,0.0054387,0.0051787,0.0051412,0.0050493,0.0047126,0.0045393,0.0042159,0.0042098,0.004205,0.0042029,0.0040778,0.0038897,0.0038809]},"error":null}
...
バッチ推論ジョブで生成されるファイルの形式は指定できないので、推薦情報を利用と思ったときに、既存のソリューションではそのまま扱えない可能性があります。
わたしが参加しているプロジェクトでもCSVで利用したいと要望があり、JSON lines形式のファイルから必要なカラムだけ抽出し、CSV形式に変換・出力する必要がありました。
■jsonlとは
JSON lines(JSONL)フォーマットは、JSON(JavaScript Object Notation)をベースにしたデータフォーマットの一種です。JSONLは、各行が有効なJSONオブジェクトであるテキストファイルです。このフォーマットは、大量のデータを扱う際やストリーミングデータの処理に特に適しています。
JSONLファイルの各行は、独立したJSONオブジェクトを含みます。これは、標準のJSONと異なり、複数のJSONオブジェクトが一つのファイルに含まれていても、それぞれが独立している点が特徴です。
例えば、次のような内容がJSONLファイルになります
{"name": "Alice", "age": 30}
{"name": "Bob", "age": 25}
{"name": "Carol", "age": 27}
【メリット】
- ストリーム処理の容易さ: 各JSONオブジェクトが独立しているため、ファイル全体を一度に読み込む必要がなく、ストリーミングや大規模データの逐次処理が容易になります。
- 柔軟性とスケーラビリティ: 一つのオブジェクトが壊れていても、他のオブジェクトには影響がないため、データの柔軟な取り扱いが可能です。また、ファイルサイズが大きくなっても、各行を個別に処理できるため、スケーラビリティに優れています。
- パースの簡便さ: 標準のJSONと同じパーサーを使用して各行を独立してパースできるため、追加のライブラリやツールは不要です。
- 大規模データセットの扱いやすさ: データベースのダンプや機械学習のデータセットなど、大規模なデータセットを扱う際に便利です。
総括すると、JSONLは、ログファイル、データエクスポート、機械学習のトレーニングデータセットなど、さまざまな用途で有効に活用できる汎用的なフォーマットです。
■jsonlファイルをCSV形式に変換・出力ハンズオン
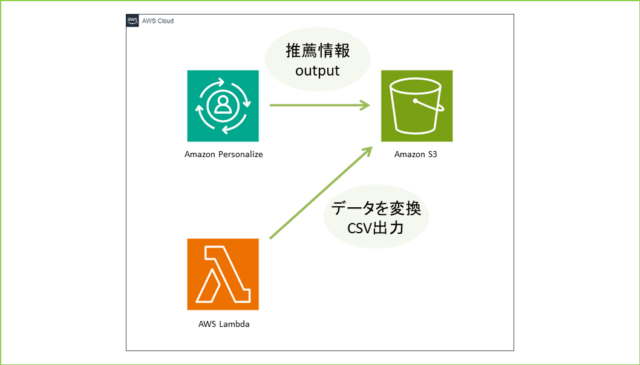

●前提や条件
今回のハンズオンは、Amazon Personalizeのバッチ推論ジョブを使ってみる【ハンズオン】の続きです。また、作成されるデータファイルや保存場所は以下の条件です。
- Amazon Personalizeのバッチ推論ジョブを使ってみる【ハンズオン】の続き
- システム担当者が任意のバケットにあるCSVファイルを取得するシチュエーション
- フォルダパスで最新のファイルを管理するのではなく、常に最新のCSVファイルのみバケットにある状態
- CSVファイルのヘッダーは"USER_ID","ITEM_ID"のみ
●Amazon S3バケット確認
まずはS3バケットにある"バッチ推薦ジョブが生成したデータファイル"の確認しましょう。のちほどバケット名やフォルダパスを使用します。
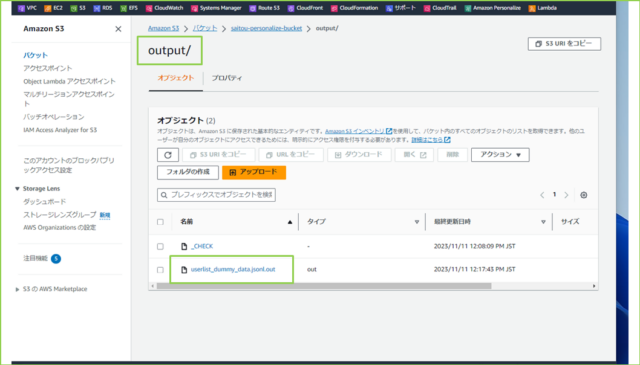
ありますね。
●IAMポリシー・ロール作成
つぎにAWS LambdaにアタッチするIAMロールとポリシーを作成します。バケットのリスト参照と、オブジェクトへの読み込み・書き込み・削除を与えます。
↓IAMのダッシュボード画面にいき、左のナビゲーションペインから[ポリシー]をクリックし、[ポリシーの作成]を押してください。
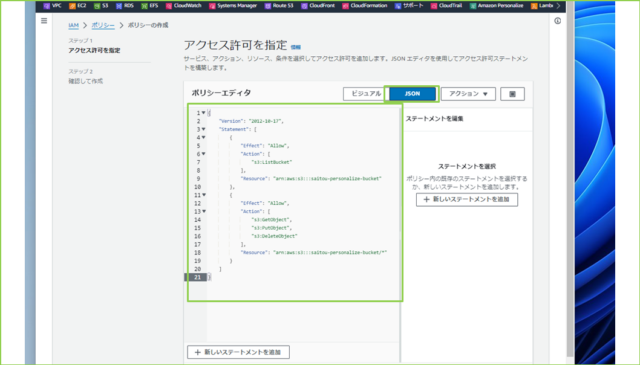
↓[JSON]を選択し、以下のドキュメントを貼り付けましょう。
※[Resource]の部分は、自身の環境に合わせてください。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:ListBucket"
],
"Resource": "arn:aws:s3:::saitou-personalize-bucket"
},
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:DeleteObject"
],
"Resource": "arn:aws:s3:::saitou-personalize-bucket/*"
}
]
}
↓貼り付けが完了しましたら、[次へ]をクリックします。
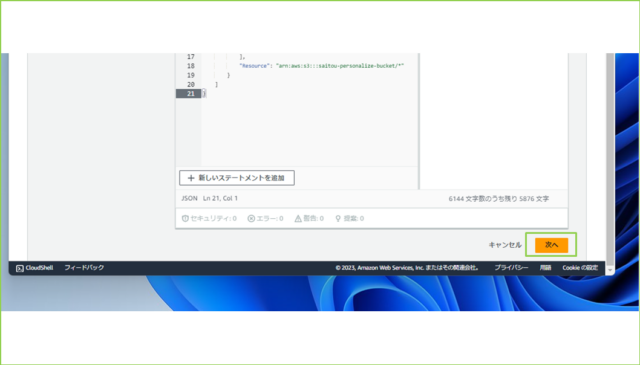
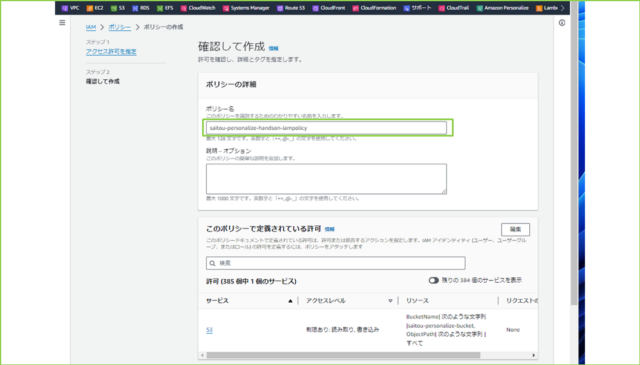
↓[ポリシー名]を任意の名前で入力します。
例、saitou-personalize-handson-iampolicy
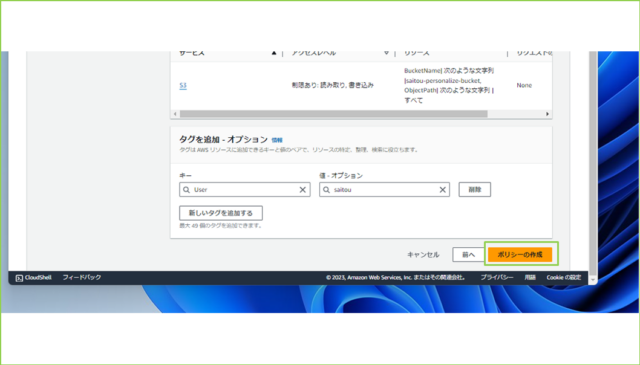
↓[ポリシーの作成]をクリックします。
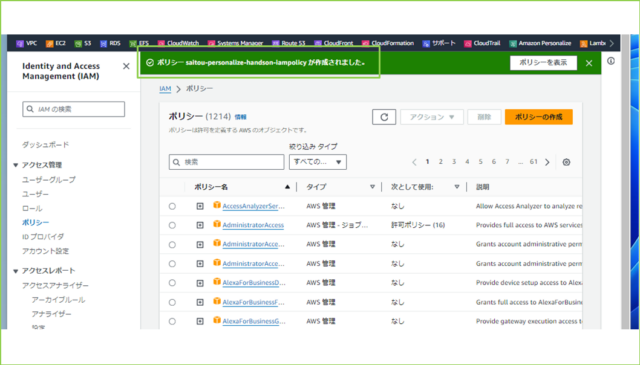
↓[ポリシー saitou-personalize-handson-iampolicy が作成されました。]と表示され、正常に作成されたことを確認します。
↓続いて、IAMロールを作成します。左のナビゲーションペインから[ロール]をクリックし、[ロールを作成]を押してください。
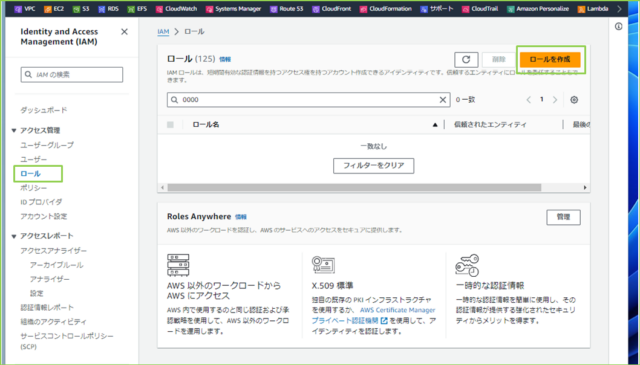
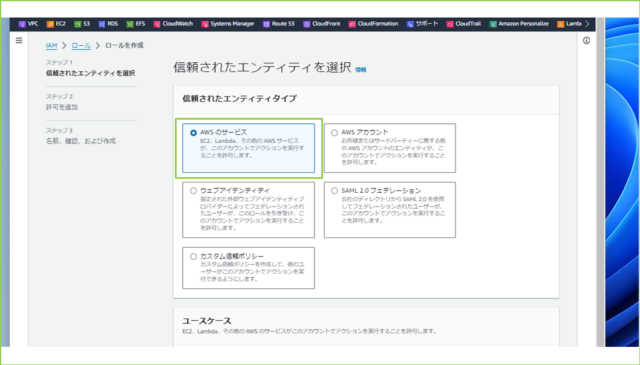
↓[信頼されたエンティティタイプ]で[AWS のサービス]を選択します。
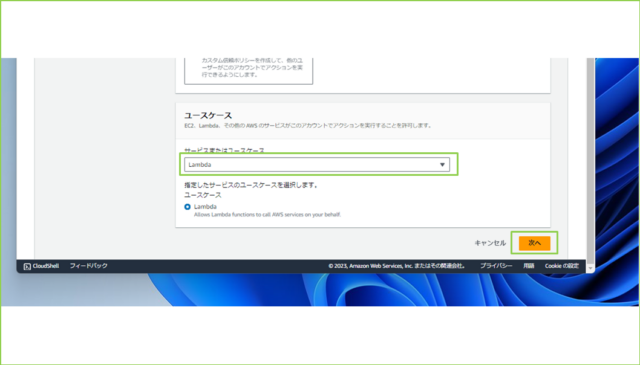
↓[サービスまたはユースケース]で[Lambda]を選択し、[次へ]をクリックします。
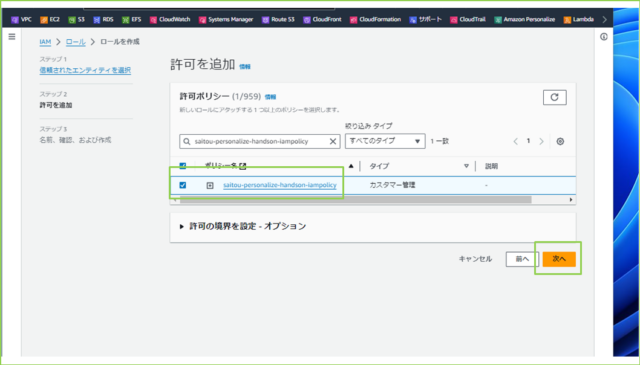
↓[許可ポリシー]で作成したIAMポリシーを検索し、チェックボックスにチェックを入れて、[次へ]をクリックします。
↓[ロール名]を任意の名前で入力します。
saitou-personalize-handson-iamrole
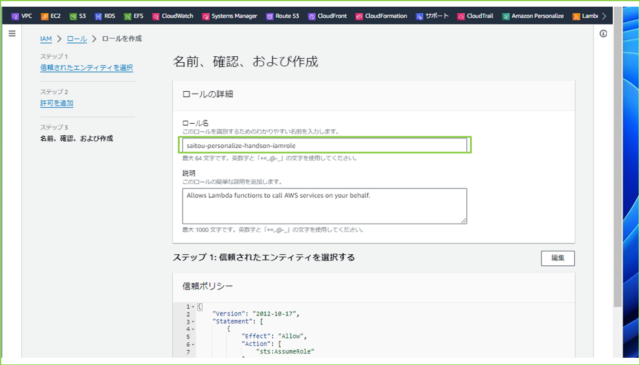
↓入力が完了しましたら、[ロールを作成]をクリックします。
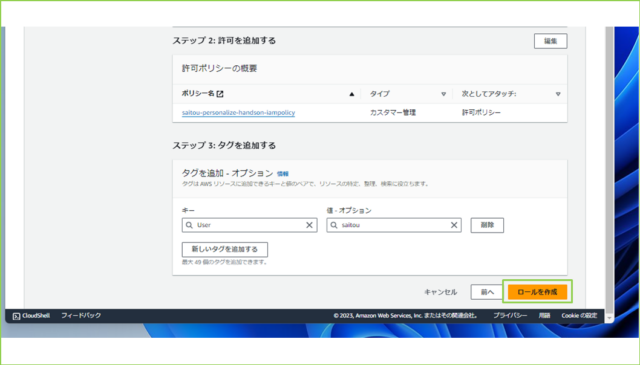
↓
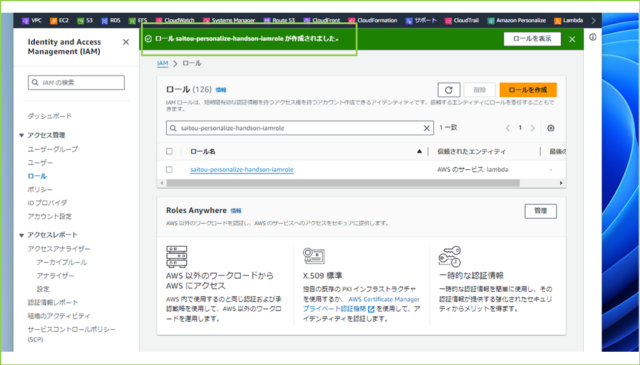
IAMロール・ポリシーの作成は以上です。
●AWS Lambda関数作成
バッチ推論ジョブで生成されたJSONファイルから必要なキーと値だけ取り出しCSV形式でS3にアップロードするAWS Lambda関数を作成します。
↓サービス検索窓で[Lambda]と検索し、[Lambda]をクリックします。左のナビゲーションペインから、[関数]をクリックし、[関数の作成]を押してください。
↓
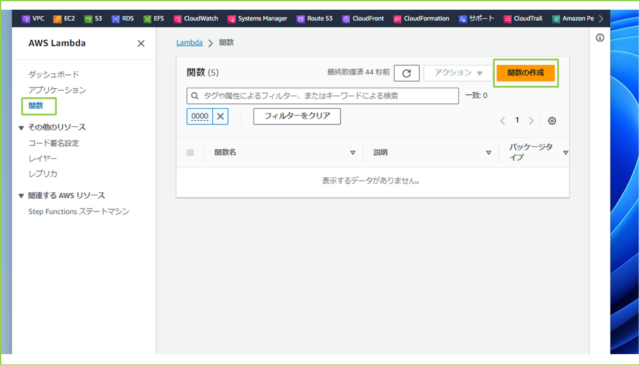
↓[一から作成]を選択し、以下の設定値を入力します。
| 項目 | 設定値 |
|---|---|
| 関数名 | 任意 |
| ランタイム | Python 3.10 |
| アーキテクチャ | x86_64 |
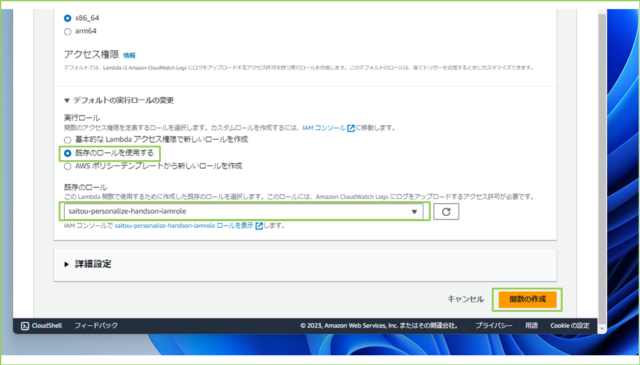
| 実行ロール | 既存のロールを使用する |
| 既存のロール | 作成したIAMロール |
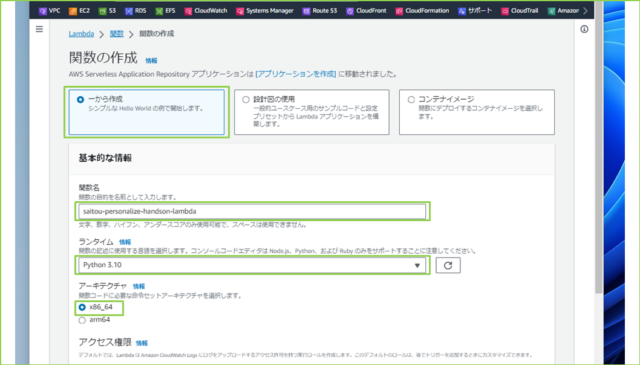
↓入力が完了しましたら、[関数の作成]をクリックします。
↓[コード]タブをクリックし、[lambda_function.py]に以下のコードを上書きで貼り付けましょう。
import boto3
import csv
import json
import logging
import os
from io import StringIO
from datetime import datetime
logger = logging.getLogger()
logger.setLevel(logging.INFO)
s3_client = boto3.client('s3')
def lambda_handler(event, context):
source_bucket = os.environ['SOURCE_BUCKET']
source_prefix = os.environ['SOURCE_PREFIX']
destination_bucket = os.environ['DESTINATION_BUCKET']
destination_prefix = os.environ['DESTINATION_PREFIX']
# destination_prefixの中の既存のファイルを削除
delete_response = s3_client.list_objects_v2(Bucket=destination_bucket, Prefix=destination_prefix)
delete_objects = delete_response.get('Contents', [])
if delete_objects:
delete_keys = {'Objects': [{'Key': obj['Key']} for obj in delete_objects]}
s3_client.delete_objects(Bucket=destination_bucket, Delete=delete_keys)
# S3からファイルのリストを取得
response = s3_client.list_objects_v2(Bucket=source_bucket, Prefix=source_prefix)
# ファイルカウンタを初期化
file_count = 1
# リストからファイルを一つずつ処理
for item in response.get('Contents', []):
file_key = item['Key']
file_response = s3_client.get_object(Bucket=source_bucket, Key=file_key)
# ファイルの内容を読み込む
file_content_lines = file_response['Body'].read().decode('utf-8').splitlines()
# CSV形式のデータを準備
csv_buffer = StringIO()
csv_writer = csv.writer(csv_buffer)
# ヘッダーを書き込む 'userId'='USER_ID', 'recommendedItems'='ITEM_ID'
csv_writer.writerow(['USER_ID', 'ITEM_ID'])
# 各行をJSONオブジェクトとして処理
for line in file_content_lines:
try:
# JSONオブジェクトをパース
jsonl_data = json.loads(line)
# 'userId' と 'recommendedItems' を取得してCSVに書き込む
user_id = jsonl_data['input']['userId']
recommended_items = jsonl_data['output']['recommendedItems']
if not recommended_items: # 推薦アイテムリストが空でないか確認
logger.info(f"推薦アイテムがありません: ユーザーID {user_id}")
continue
for item in recommended_items:
csv_writer.writerow([user_id, item])
except json.JSONDecodeError as e:
logger.error(f"JSONの解析エラー: {e}")
continue # JSONエラーが発生した場合は次の行にスキップ
# ループの後で、ヘッダー以外にも内容があるか確認してからアップロード
csv_buffer.seek(0)
# 現在の日付を取得
current_date = datetime.now().strftime('%Y%m%d')
if len(csv_buffer.getvalue().splitlines()) > 1:
# CSVファイル名に日付とカウンタを付けてS3にアップロード
destination_file_key = f"{destination_prefix}newsletter{current_date}-{file_count}.csv"
s3_client.put_object(Bucket=destination_bucket,
Key=destination_file_key,
Body=csv_buffer.getvalue())
file_count += 1 # ファイルカウンタを増やす
else:
logger.info(f"書き込むデータがありません: ファイルキー {file_key}")
csv_buffer.close()
return {
'statusCode': 200,
'body': json.dumps('CSV files have been uploaded successfully.')
}
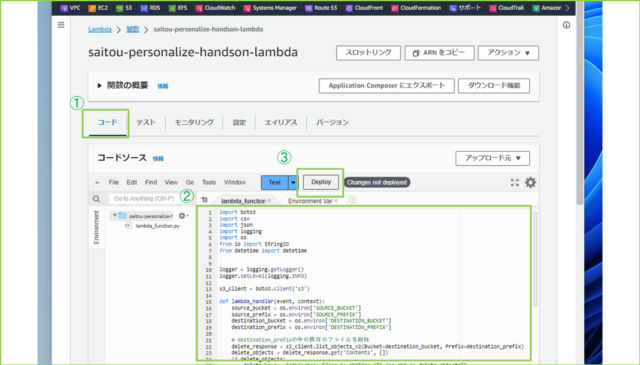
↓貼り付けましたら、[Deploy]をクリックします。デプロイに成功すると、[関数 saitou-personalize-handson-lambda が正常に更新されました。]と表示されます。
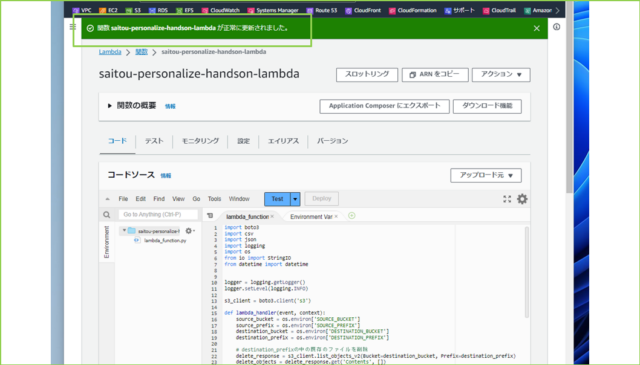
↓続いて、コード内で参照される環境変数を設定します。[設定]タブをクリックし、[環境変数]をクリックし、[編集]を押します。
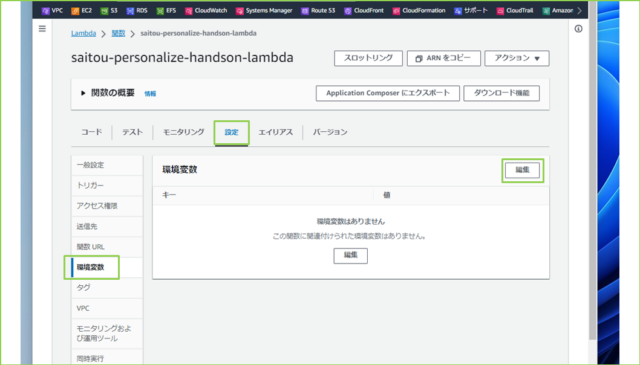
↓設定が必要な環境変数は以下の4つです。
"""
SOURCE_BUCKET = ソースバケット名
SOURCE_PREFIX = ソースプレフィックス
DESTINATION_BUCKET = 出力先バケット名
DESTINATION_PREFIX = 出力先プレフィックス
"""
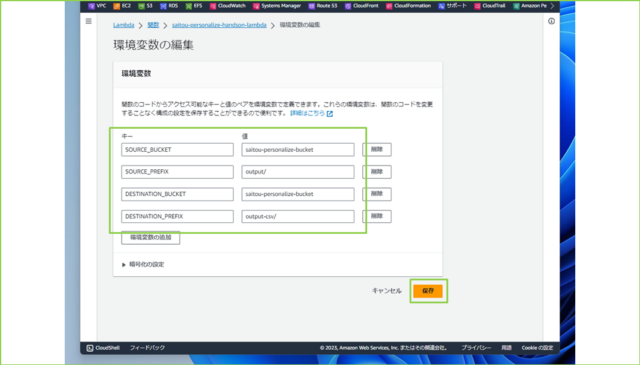
↓入力が完了しましたら、[保存]をクリックします。
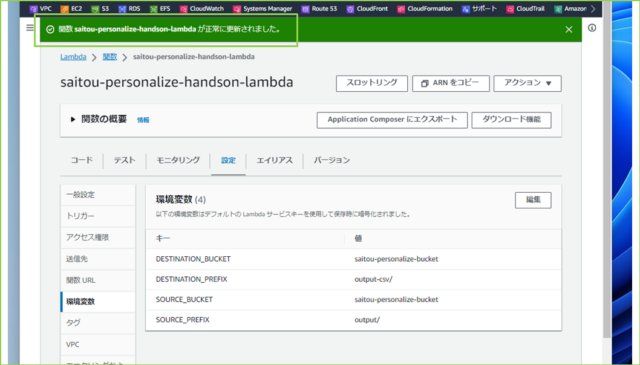
↓つぎに、タイムアウト設定を編集します。[一般設定]をクリックし、[編集]を押してください。
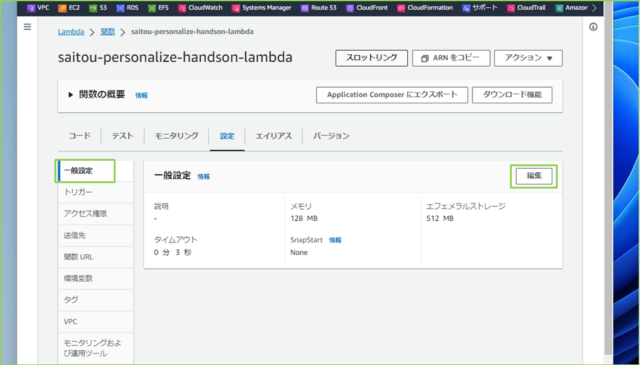
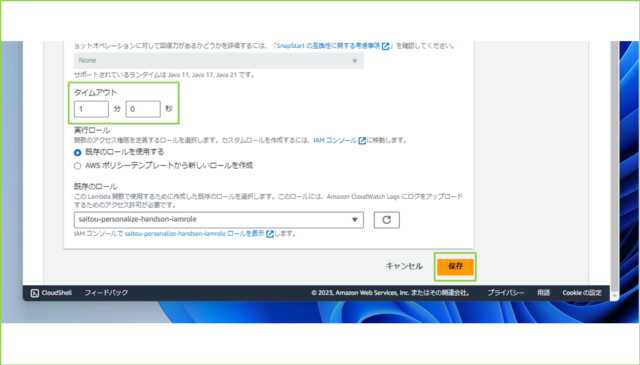
↓読み込むデータの量と書き込む量に合わせて、タイムアウトの分数を調整してください。※データ量が多い場合、、メモリも変更しなければいけません。
変更が完了しましたら、[保存]をクリックします。
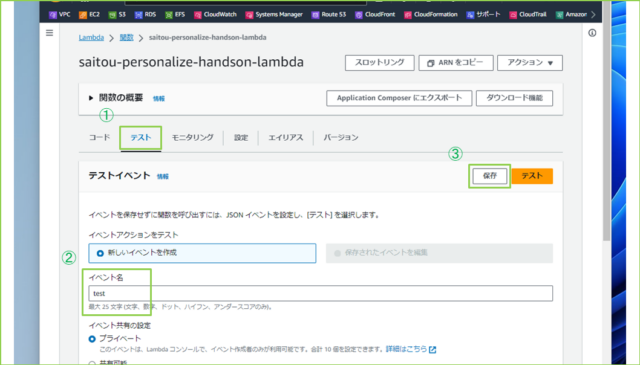
↓さいごにテストの設定をします。[テスト]タブをクリックし、[イベント名]を入力、[保存]を押してください。
構築は以上です。
●動作確認
それでは、実際にLambda関数を実行してみましょう。
実際の現場では、Eventbridgeなどのトリガーによって動かすかと思います。今回はテストで実行し、出力先のS3バケットにCSVファイルがあるか確認してみましょう。
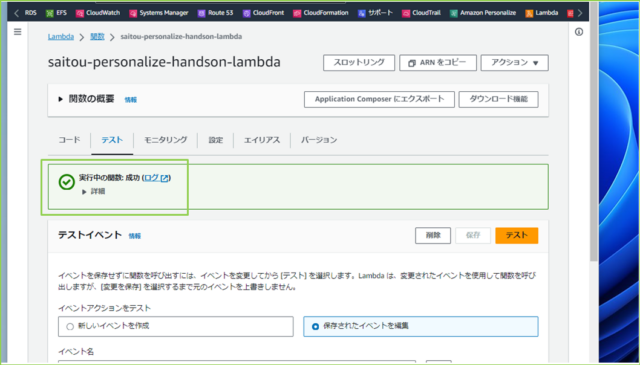
↓[テスト]タブの[テストイベント]から[テスト]をクリックします。
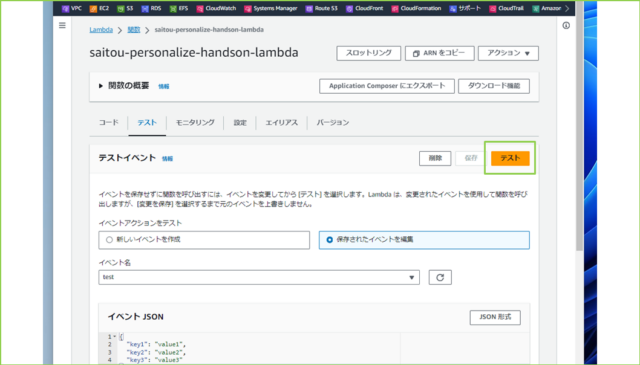
↓[成功]と表示されました。
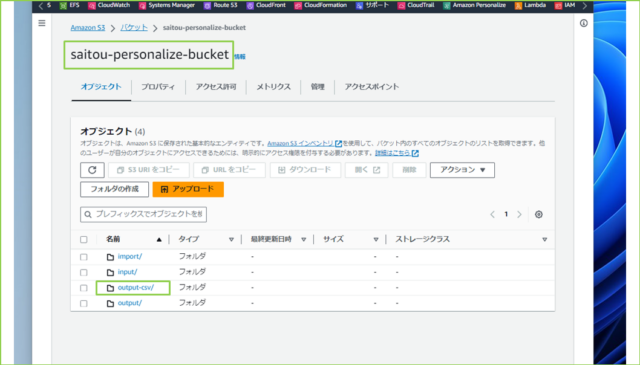
↓S3バケットを見てみましょう。output-csv/というプレフィックスが作成されています。
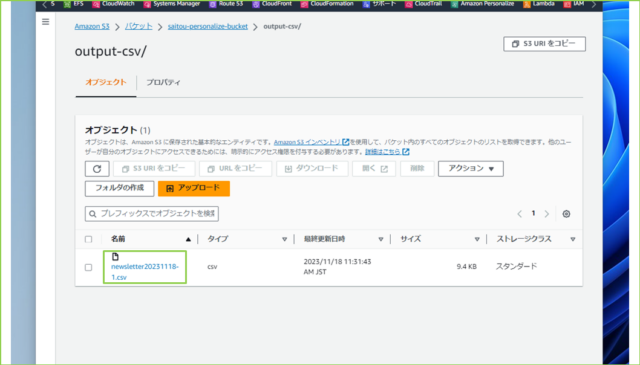
↓csvファイルが一つ作成されています。
↓ダウンロードして中身を見てみると、ヘッダーに選択したカラム名とその下に値がCSV形式で出力されていますね。
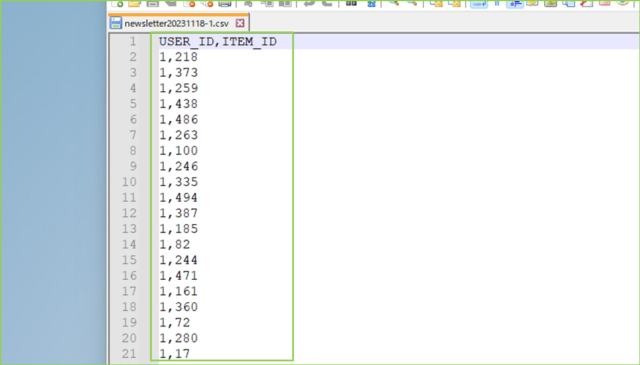
↓もとのjsonファイルが次です。
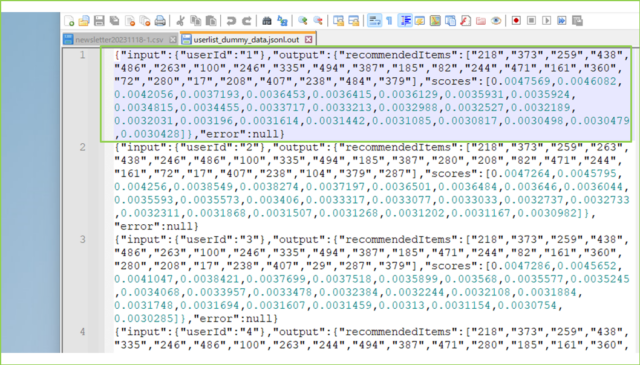
必要なデータだけ取り出して、CSV形式でS3にアップロードできました。
↓Lambdaの実行ログを見ると、いくつかわかることがあります。
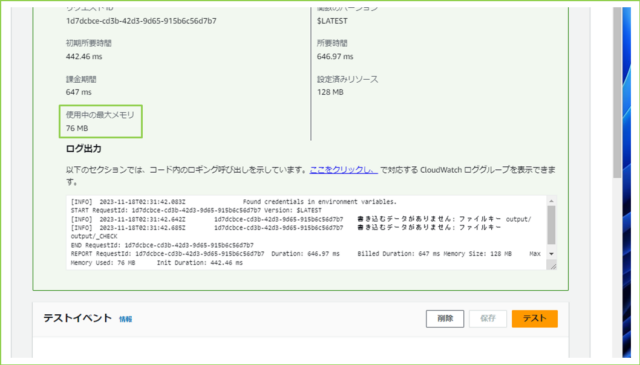
とくに重要なのが、使用中の最大メモリです。今回は76MBと書かれていまして、設定してある128MBまでまだ余裕があります。もしギリギリだった場合、1.5倍や2倍の値で調査してみましょう。
今回のハンズオンは以上です。
まとめ:Amazon Personalizeバッチ推論ジョブで生成されたJSONファイルをCSV形式に変えてみる
Amazon Personalizeバッチ推論ジョブでは、出力されるファイル形式で決まっています。今あるシステムにうまく組み込むためには、Lambdaを使って変換する必要があることもありますよね。
ぜひためしてみください。
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
AIや機械学習のレコメンデーションサービスについて知りたい方は、ぜひ協栄情報にお問い合わせください。
https://www.cp-info.co.jp/contact/
☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆☆
参考リンク:AWS公式ドキュメント
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/
■Amazon Personalize学習用ダミーデータをPythonで作ってみた(齊藤弘樹)
https://cloud5.jp/saitou-personalize-create-dammydata/
■Amazon Personalizeのエラーを解決!各カラムのデータ型を調べる方法(齊藤弘樹)
https://cloud5.jp/saitou-check-data-type/
■AWS Lambdaを使ってAmazon Personalizeの推薦情報をCSVでS3にエクスポートする方法(齊藤弘樹)
https://cloud5.jp/saitou-personalize-attribute-recommendation/