




この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeを学習していて、ダミーデータが必要になりました。いくつか検索しましたが、ちょうどいいのがなかったため自分で作成しました。
今回の記事では、Amazon Personalizeで利用できる、各データセット用のダミーファイル作成コードを紹介します。
Amazon Personalize学習用ダミーデータ作成
Personalizeの学習で使用しているダミーデータ作成用のPythonコードを共有します。作成するダミーデータは、求人サイトにおすすめ求人を表示する想定のダミーデータです。
【ダミーデータ内で利用する各属性の想定数】
- ユーザー数: 500
- 求人件数: 1000
- 行動履歴数: 5000
■ユーザーデータのダミーデータ作成コード
作成されるカラム:USER_ID, AGE, GENDER, LOCATION
"""ユーザーデータを作成"""
import pandas as pd
import random
# ユーザー数を定義
num_users = 500
# 日本の47の都道府県のリスト
prefectures = [
"北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県",
"茨城県", "栃木県", "群馬県", "埼玉県", "千葉県", "東京都", "神奈川県",
"新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県",
"岐阜県", "静岡県", "愛知県", "三重県",
"滋賀県", "京都府", "大阪府", "兵庫県", "奈良県", "和歌山県",
"鳥取県", "島根県", "岡山県", "広島県", "山口県",
"徳島県", "香川県", "愛媛県", "高知県",
"福岡県", "佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県",
"沖縄県"
]
genders = ["M", "F", "U"] # "U": 非公開
# ダミーデータの作成
users = {
"USER_ID": list(range(1, num_users + 1)),
"AGE": [random.randint(15, 70) for _ in range(num_users)],
"GENDER": [random.choice(genders) for _ in range(num_users)],
"LOCATION": [random.choice(prefectures) for _ in range(num_users)]
}
# pandasのDataFrameに変換
df = pd.DataFrame(users)
# CSVファイルに保存
df.to_csv('user_dummy_data.csv', index=False)
print("user_dummy_data.csv ファイルを作成しました。")
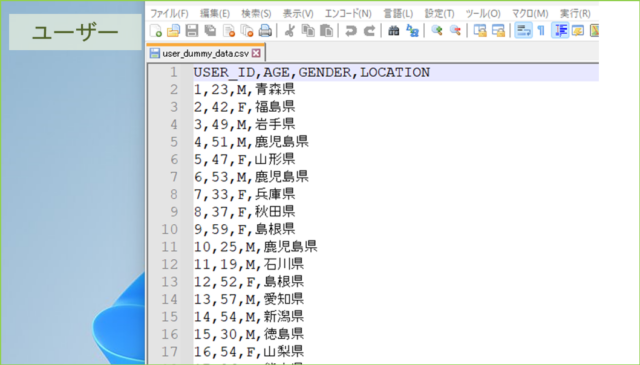
↓作成されるデータはこんな感じです。
■アイテムデータのダミーデータ作成コード
作成されるカラム:ITEM_ID, LOCATION, CATEGORY_L1, PRICE
"""アイテムデータ作成"""
import pandas as pd
import random
# 件数を定義
num_entries = 1000
# カラムごとのダミーデータを生成
locations = [
"北海道", "青森県", "岩手県", "宮城県", "秋田県", "山形県", "福島県", "茨城県", "栃木県", "群馬県",
"埼玉県", "千葉県", "東京都", "神奈川県", "新潟県", "富山県", "石川県", "福井県", "山梨県", "長野県",
"岐阜県", "静岡県", "愛知県", "三重県", "滋賀県", "京都府", "大阪府", "兵庫県", "奈良県", "和歌山県",
"鳥取県", "島根県", "岡山県", "広島県", "山口県", "徳島県", "香川県", "愛媛県", "高知県", "福岡県",
"佐賀県", "長崎県", "熊本県", "大分県", "宮崎県", "鹿児島県", "沖縄県"
]
random_locations = [random.choice(locations) for _ in range(num_entries)]
# 20業種を想定
industries = [
"Technology", "Finance", "Healthcare", "Manufacturing", "Retail", "Entertainment",
"RealEstate", "Agriculture", "Transportation", "Education", "Energy", "Construction",
"Pharmaceutical", "Hospitality", "Media", "Telecommunications", "Automotive",
"Aerospace", "FoodAndBeverage", "Consulting"
]
random_industries = [random.choice(industries) for _ in range(num_entries)]
# 時給幅を定義
salary_ranges = [round(random.uniform(1000, 2000), 2) for _ in range(num_entries)]
# データフレームを作成
df = pd.DataFrame({
"ITEM_ID": list(range(1, 1001)),
"LOCATION": random_locations,
"CATEGORY_L1": random_industries,
"PRICE": salary_ranges
})
# CSVとして保存
df.to_csv("item_dummy_data.csv", index=False)
print("item_dummy_data.csv ファイルを作成しました。")
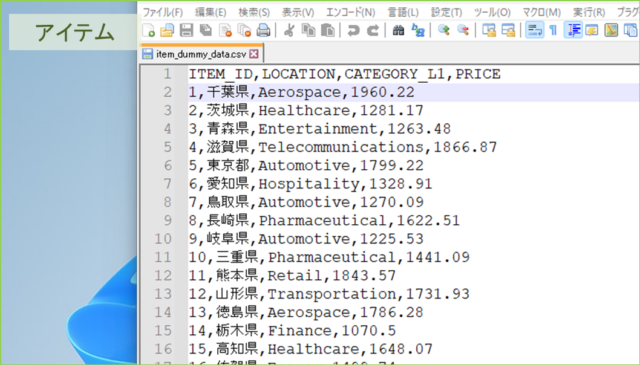
↓作成されるデータはこんな感じです。
■インタラクションデータのダミーデータ作成コード
作成されるカラム:USER_ID, ITEM_ID, TIMESTAMP, EVENT_TYPE
"""インタラクションデータ作成"""
import pandas as pd
import random
import time
# レコード数を定義
num_records = 5000
# パラメータ設定
user_id_range = 500 # USER_IDの範囲(1から500までの整数)
item_id_range = 1000 # ITEM_IDの範囲(1から1000までの整数)
event_types = ["click", "view", "apply", "save"]
# ダミーデータの生成
user_ids = [random.randint(1, user_id_range) for _ in range(num_records)]
item_ids = [random.randint(1, item_id_range) for _ in range(num_records)]
timestamps = [int(time.time()) for _ in range(num_records)]
event_types_list = [random.choice(event_types) for _ in range(num_records)]
# pandasのDataFrameに変換
df = pd.DataFrame({
"USER_ID": user_ids,
"ITEM_ID": item_ids,
"TIMESTAMP": timestamps,
"EVENT_TYPE": event_types_list
})
# CSVファイルに保存
df.to_csv('interaction_dummy_data.csv', index=False)
print("interaction_dummy_data.csv ファイルを作成しました。")
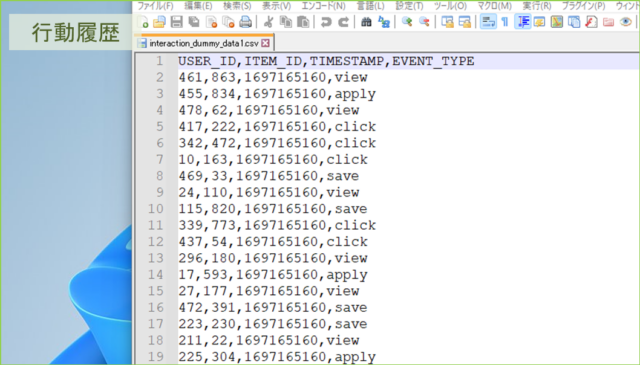
↓作成されるデータはこんな感じです。
■ユーザーリストのダミーデータ作成コード
ユーザーリストデータに関しては、バッチ推論ジョブ作成時に利用するかと思います。キーの名前が一致していないとエラーが起こります。USER_IDでもなく、useridでもなく、"userId"です。
作成されるカラム:userId
"""ユーザーリスト作成"""
import pandas as pd
import json
# ユーザー数を定義
num_users = 10
# ダミーデータの作成
users = {
"userId": list(range(1, num_users + 1))
}
# pandasのDataFrameに変換
df = pd.DataFrame(users)
# userIdのデータ型を文字列型に変換
df['userId'] = df['userId'].astype(str)
# JSON Lines形式でファイルに保存
with open('userlist_dummy_data.jsonl', 'w') as file:
for _, row in df.iterrows():
json.dump(row.to_dict(), file)
file.write('\n')
print("userlist_dummy_data.jsonl ファイルを作成しました。")
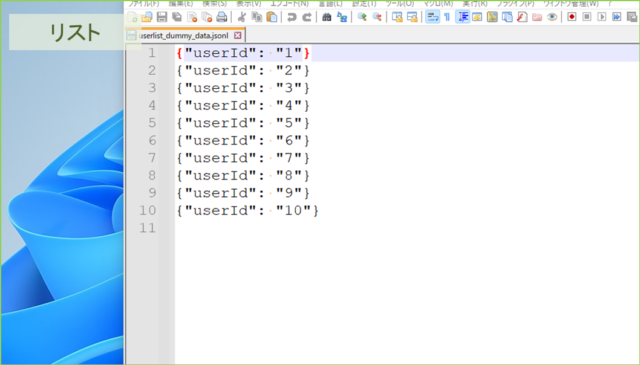
↓作成されるデータはこんな感じです。
まとめ: Amazon Personalize学習用ダミーデータをPythonで作ってみた
Amazon Personalizeを想定通り動かすためには、正確なデータ・スキーマ定義、そして、データの量が必要です。今回ユーザー数を500人、求人件数を1000件、行動履歴数を5000個で想定しましたが、精度を高めるためには行動履歴数をもっと増やす必要がある気がしました。
必要に応じて、コード内の各件数を修正してください。
参考リンク:AWS公式ドキュメント
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/