



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
Amazon Personalizeはユーザーにパーソナライズされた推薦情報を提供する、AWSの機械学習サービスです。機械学習についての深い知識がなくても簡単に利用できるのが利点ですが、学習させるデータの質が結果の質に大きく影響する面を持っています。
筑波大学の佐久間 淳教授は「1. 機械学習概論と単回帰 (1)」の講義で「データセットを突っ込む前に、各特徴量が本当に予測に有用かを判断する。方法は、視覚化。グラフなどにして、偏りがないか。」と話しています。
Peronalizeにデータをインポートする前に、データの前処理や探索的データ解析のステップが必要だということですね。
そして、この解析にピッタリなツールがJupyter Notebookです。
今回の記事では、Amazon Personalizeで利用するデータをJupyter Notebookで可視化し、どういったデータなのかを知る方法を紹介します。
Jupyter Notebookを使ってみよう
Jupyter Notebookはデータ解析に優れたツールです。さきにどんなことができるか、下の画像を見てみましょう。

ライブラリを利用し、データを配列で表示したり、画像のようにグラフで可視化したりしてくれる優れたツールです。
■Jupyter Notebookとは

Jupyter Notebookは、対話型のコーディングと計算、可視化、ドキュメント作成を統合するためのオープンソースのウェブアプリケーションです。
A notebook is a shareable document that combines computer code, plain language descriptions, data, rich visualizations like 3D models, charts, graphs and figures, and interactive controls. A notebook, along with an editor (like JupyterLab), provides a fast interactive environment for prototyping and explaining code, exploring and visualizing data, and sharing ideas with others.公式ドキュメントより
【Jupyter Notebookのメリット】
-
対話型環境: Jupyter Notebookは、セルベースのインターフェースを提供しており、ユーザーは個々のセルにコードを書き、そのセルを実行することができます。これにより、リアルタイムでのフィードバックと結果の表示が可能となります。
-
多言語サポート: Jupyter システムは、Python、Java、R、Julia、Matlab、Octave、Scheme、Processing、Scala などを含む 100 以上のプログラミング言語 (Jupyter エコシステムでは「カーネル」と呼ばれます) をサポートしています。https://jupyter4edu.github.io/jupyter-edu-book/jupyter.html
-
文書化: ノートブックは、MarkdownやLaTeXなどのリッチテキストフォーマットをサポートしており、コードとともに説明やドキュメンテーションを記述することができます。これにより、分析の過程や結果を詳細に説明することが容易となります。
-
可視化: 多くのデータ可視化ライブラリ(例:matplotlib、seaborn、bokehなど)と統合しており、直接ノートブック内でグラフやチャートを表示することができます。
-
統合された環境: Jupyter Notebookは、データの取得、クリーニング、変換、モデリング、可視化など、データサイエンスのワークフロー全体を1つのツールで実行できる統合された環境を提供しています。
■データ準備
まずはJupyter Notebookで解析するデータを用意しましょう。形式はCSVでお願いします。
データがないという方は、ダミーデータ作成記事から"ユーザーデータのダミーデータ作成コード"を利用して、ダミーデータを作成しましょう。
↓作成されるデータはこんな感じです。データの属性はユーザーID、年齢、性別、地域ですね。
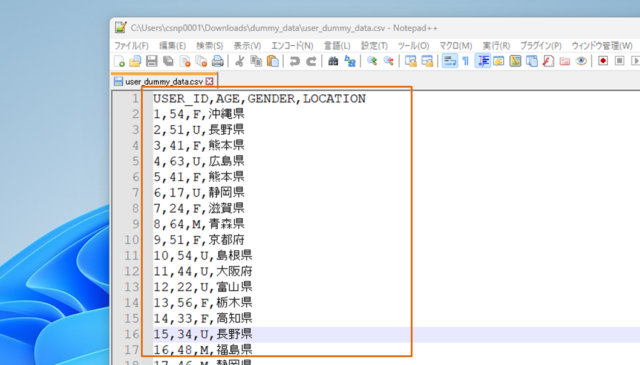
データの準備は以上です。
■Jupyter Notebookの起動
つぎは"Jupyter Notebook"を起動しましょう。Jupyter Notebookはブラウザを利用して、使用することができます。
今回はAnaconada NavigatorにありますJupyter Notebookを使ってみましょう。
Anaconadaをインストールしていない方は、こちらからインストールしてみてください。
↓Windowsを利用している方は、タスクバーにある検索窓で"anaconda"と調べていただき、[Anaconda Navigator]をクリックしてください。
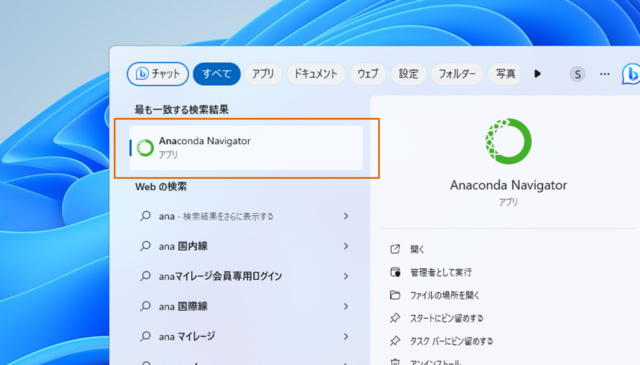
↓Anaconda Navigatorには多くのアプリケーションが搭載されています。今回は[Jupyter Notebook]の[Launch]をクリックします。

↓ブラウザが起動し、Jupyter Notebookのホーム画面が表示されます。
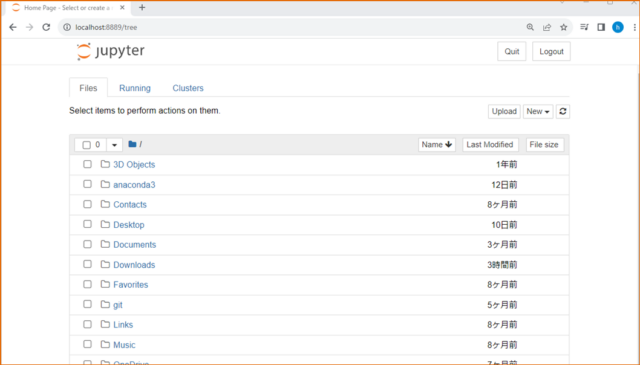
↓Jupyter Notebookは基本的にはローカル環境上で動作し、デフォルトでhttp://localhost:8888/ を使用して通信します。Jupyter Notebookインスタンスが増えていくと、8889、8890とポートが変わっていきますね。
↓画面右上に[New]と書かれた選択ボタンをクリックし、[Python3]をクリックしてください。
新たにページが立ち上がり、セル型のインターフェースが表示されます。
↓左上の[Untitled]をクリックし、任意の名前に変えましょう。
↓
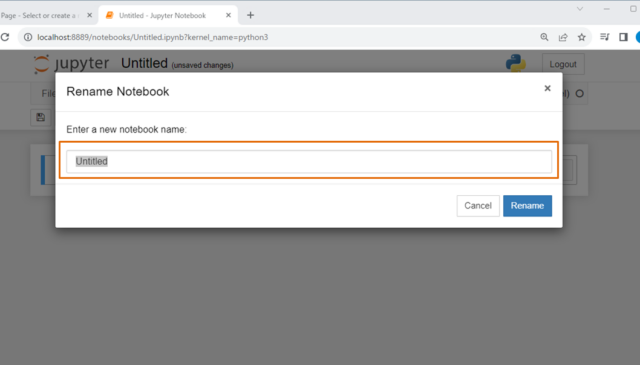
↓
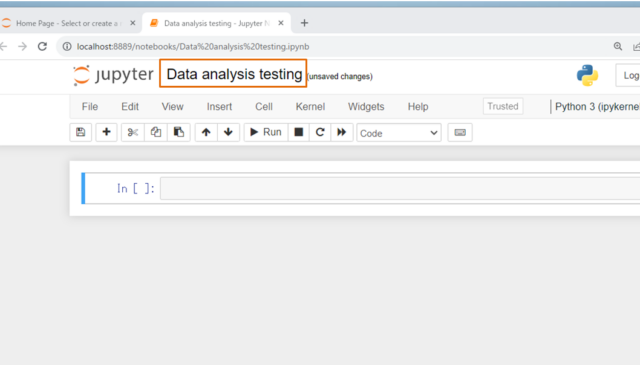
Jupyter Notebookの起動は以上です。"Jupyter Notebook"の使い方については、記事を準備中ですのでお待ちください。
■Jupyter Notebookでデータを可視化
実行環境が用意できましたので、実際にコードを実行していきましょう。
今回利用するデータには、ユーザーID、年齢、性別、地域が含まれていますので、まずはユーザーを地域別にグラフで可視化してみます。
まずは必要なライブラリpandasとmatplotlibをインポートします。
- pandasはPythonでデータ分析を行うための高度なライブラリです。データの操作や分析のための多数の関数とメソッドを提供しています。
- matplotlibはPythonでグラフを描画するためのライブラリで、pyplotはその中のモジュールで、MATLABのプロッティングスタイルのインターフェースを提供しています。
↓以下のコード貼り付けましょう。
import pandas as pd
import matplotlib.pyplot as plt
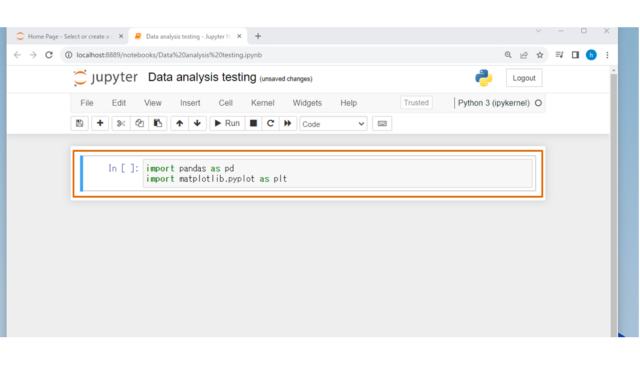
asで省略するのはお作法のようです。入力しましたら、[Shift + Enter]、もしくは、画面上の[Run]をクリックしましょう。次のセルが表示されます。
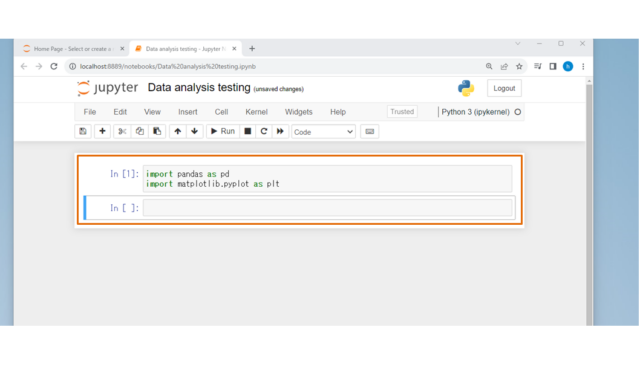
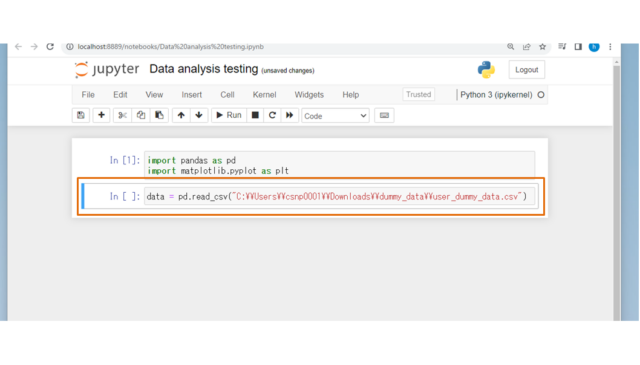
↓つづいて、データの読み込みを行います。[データ準備]で用意したCSVファイルのパスを指定し、以下のコードを実行してください。
data = pd.read_csv("ファイルフルパス")
# 例) data = pd.read_csv("C:\\Users\\csnp0001\\Downloads\\dummy_data\\user_dummy_data.csv")
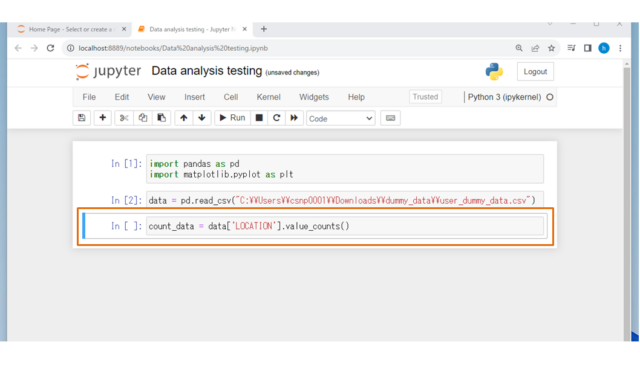
↓データファイル内のカラム"LOCATION"にある都道府県ごとの頻度をカウントします。
count_data = data['LOCATION'].value_counts()
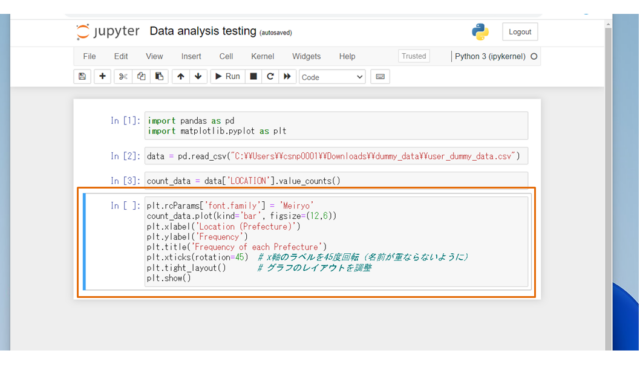
ここまでで可視化する準備が整いましたので、matplotlibでグラフを描画します。以下のコードを実行してください。
# 棒グラフの描画
plt.rcParams['font.family'] = 'Meiryo'
count_data.plot(kind='bar', figsize=(12,6))
plt.xlabel('Location (Prefecture)')
plt.ylabel('Frequency')
plt.title('Frequency of each Prefecture')
plt.xticks(rotation=45) # x軸のラベルを45度回転(名前が重ならないように)
plt.tight_layout() # グラフのレイアウトを調整
plt.show()
↓
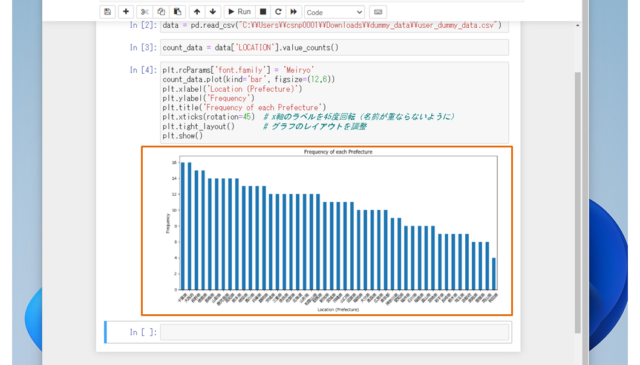
ダミーデータの値はランダムで生成されるようにしてあるので、同じグラフではないかと思います。
↓右クリックすると、画像を別タブで開く、もしくは保存することも可能です。
↓
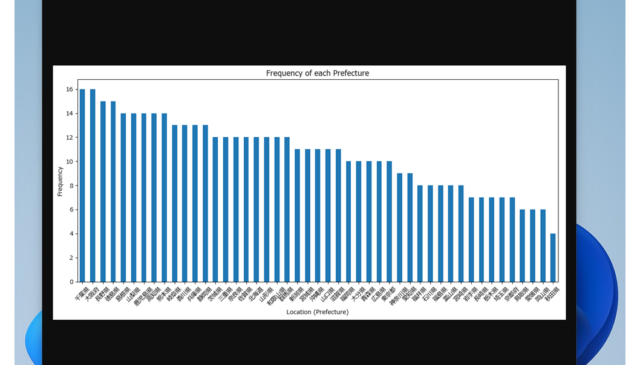
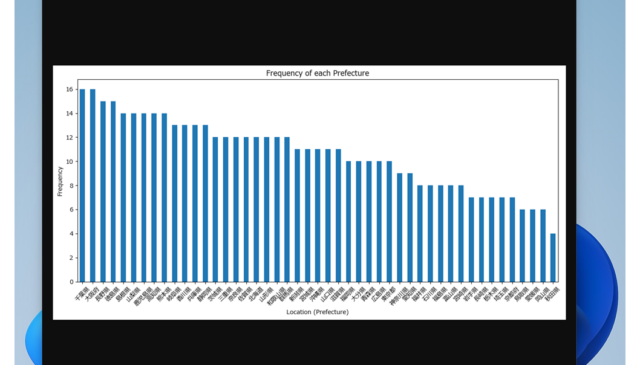
データを可視化したおかげで、わたしのデータの場合、"千葉県と大阪府のユーザが多く、秋田県のユーザーが一番少ないデータ"なんだということが一目でわかりました。
つぎは、性別をグラフで描画してみましょう。
count_data = data['GENDER'].value_counts()
↓それでは、棒グラフにしてみます。
plt.rcParams['font.family'] = 'Meiryo'
count_data.plot(kind='bar', figsize=(12,6))
plt.xlabel('Gender')
plt.ylabel('Frequency')
plt.title('Frequency of Gender')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
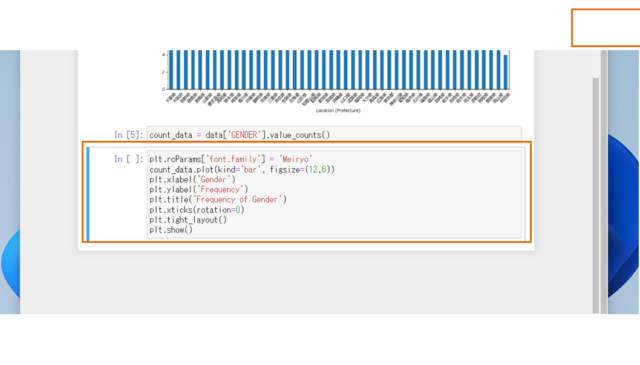
↓
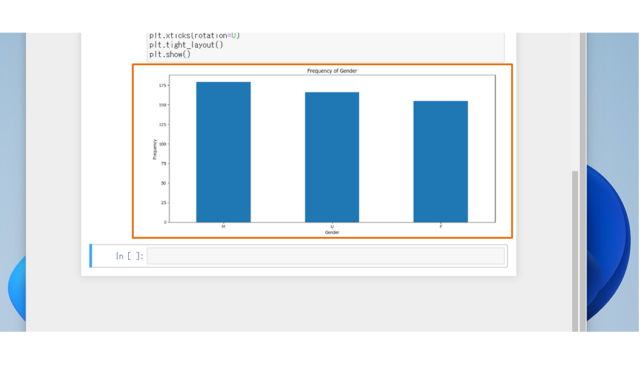
※"U"は非公開です。
さいごに、年齢もグラフにしてみましょう。
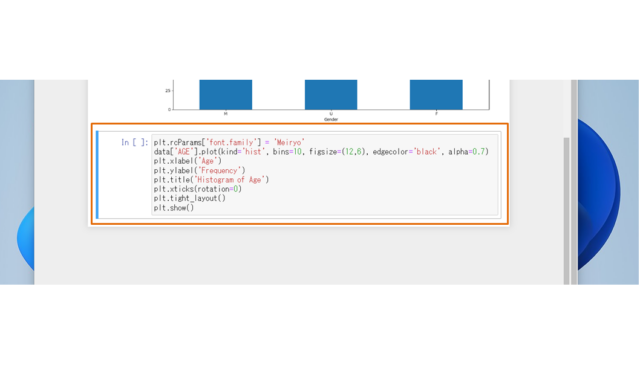
年齢の場合は1歳ごとに表示するとデータがわかりにくくなるので、"bins"で年齢を任意の範囲で区分けして表示します。ヒストグラムと呼ばれるグラフですね。例えば、bins=10とすると、データの範囲を10等分した10のビンが作成されます。ある程度細かく見たい場合は、任意で"bins"の値を変更してください。
以下のコードを実行してください。
plt.rcParams['font.family'] = 'Meiryo'
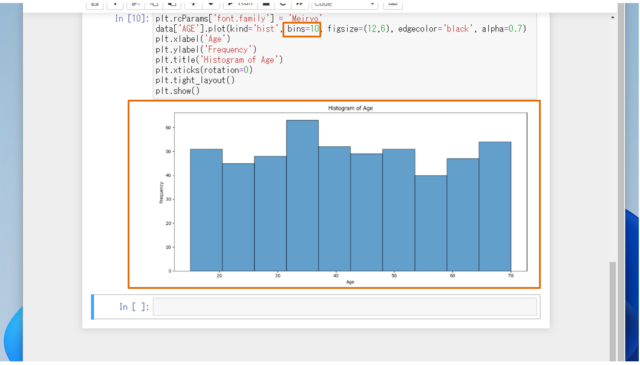
data['AGE'].plot(kind='hist', bins=10, figsize=(12,6), edgecolor='black', alpha=0.7)
plt.xlabel('Age')
plt.ylabel('Frequency')
plt.title('Histogram of Age')
plt.xticks(rotation=0)
plt.tight_layout()
plt.show()
↓
↓[bins]の値を[20]に変更し、実行してみると、
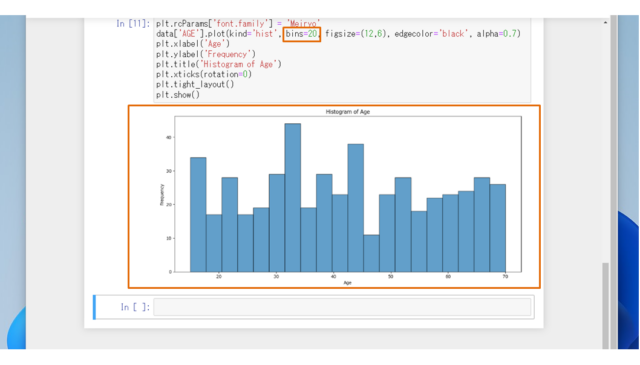
データから受ける印象が全然違いますね。
今回のハンズオンは以上です。
まとめ: Amazon Personalizeで利用するデータをJupyter Notebookで解析してみる
機械学習サービスが簡単に利用できる時代ですが、使い方を間違えるとより良い結果は得られません。
Jupyter Notebookは機械学習サービスと相性のいいツールで、知りたいことを知る手助けをしてくれるはずです。ぜひ使ってみてください。
参考リンク:Jupyter Notebook Documentation
↓ほかの協栄情報メンバーも機械学習・AIに関する記事を公開しています。ぜひ参考にしてみてください。
■Amazon CodeWhispererを試してみた(dapeng)
https://cloud5.jp/amazon-codewhisperer/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-entry/
■Amazon Personalizeの使い方や事例を紹介【ハンズオンあり】 part2(齊藤弘樹)
https://cloud5.jp/saitou-amazonpersonalize-handson/
■Amazon Personalize学習用ダミーデータをPythonで作ってみた(齊藤弘樹)
https://cloud5.jp/saitou-personalize-create-dammydata/