



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
皆様こんにちは。
Terraformを利用して、AWSで高可用性アーキテクトの構築をしていきます。
今回はCloudWatch Alarmの構築をしていきます。
1.高可用性アーキテクト構築目次
2.CloudWatch Alarm概要
Amazon CloudWatch は、DevOps エンジニア、デベロッパー、サイト信頼性エンジニア (SRE)、IT マネージャー、および製品所有者のために構築されたモニタリング/オブザーバビリティサービスです。CloudWatch は、アプリケーションをモニタリングし、システム全体におけるパフォーマンスの変化に対応して、リソース使用率の最適化を行うためのデータと実用的なインサイトを提供します。
Amazon CloudWatchとは
Amazon CloudWatchは、稼働中のシステムを効率的に安定運用するためのAWSサービスです。システムの状態をリアルタイムで監視し、指定条件に合致しているか判定することで障害を検知します。また、障害検知時にはシステム管理者へのメール通知、サーバー台数増減等のアクションの実行が可能です。
CloudWatchは各AWSリソースの状態を定期的に取得します。この状態のことをメトリクスと呼びます。
AWSがあらかじめ定義しているメトリクスを標準メトリクスと呼び、利用者が定義した値をCloudWatchに渡すことで作成した独自のメトリクスをカスタムメトリクスと呼びます。
標準メトリクス
標準メトリクスとは、AWSがあらかじめ用意したAWSリソースの使用状況(監視項目)です。
主にEC2やRDSのCPU使用率、ステータスチェックなどの項目があります。
カスタムメトリクス
カスタムメトリクスは、ユーザーが独自に設定するメトリクスです。標準メトリクスに存在しないシステム項目を監視したい場合に設定します。
代表的な項目としてはEC2インスタンスのメモリ使用率やディスク使用率があります。
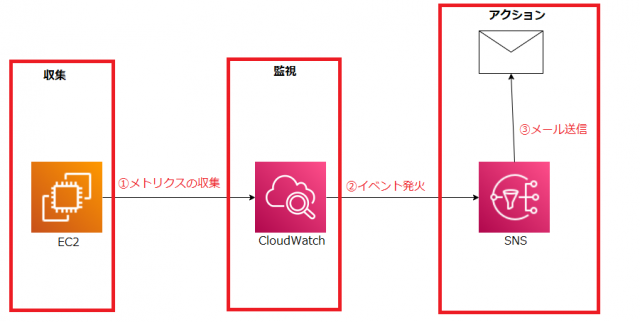
3.フロー図
CloudWatchのフロー図は下記の通りです。
4.CloudWatch Agentの初期設定
CloudWatchAgentのインストールはEC2起動時にユーザーデータで完了しているため、初期設定から始めます。
SSHでEC2インスタンスに接続して、下記コマンドでセットアップウィザードを実行します。
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard下記のように表示されました。
[ec2-user@ip-10-0-1-10 ~]$ sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-config-wizard
================================================================
= Welcome to the Amazon CloudWatch Agent Configuration Manager =
= =
= CloudWatch Agent allows you to collect metrics and logs from =
= your host and send them to CloudWatch. Additional CloudWatch =
= charges may apply. =
================================================================セットアップウィザードの実行内容は以下のようになります。
- ウィザード起動
On which OS are you planning to use the agent?
1. linux
2. windows
3. darwin
default choice: [1]:
1今回はLinuxOSを利用しているので1を選択。
- どのOSでエージェントを使用する予定ですか?
Are you using EC2 or On-Premises hosts?
1. EC2
2. On-Premises
default choice: [1]:
1EC2インスタンスで利用するので1を選択。
- どのユーザーでエージェントを実行する予定ですか?
Which user are you planning to run the agent?
1. root
2. cwagent
3. others
default choice: [1]:
1実質的にはroot又はAmazonlinuxのデフォルトユーザーであるec2-userどちらかの選択です。
今回はデフォルトで選択されている1にします。
- StatsDデーモンを有効にしますか?
Do you want to turn on StatsD daemon?
1. yes
2. no
default choice: [1]:
2今回はStatsDデーモンは利用しないので2を選択。
- CollectDからメトリクスを監視しますか?警告:CollectDがインストールされていないと、Agentの起動に失敗します。
Do you want to monitor metrics from CollectD? WARNING: CollectD must be installed or the Agent will fail to start
1. yes
2. no
default choice: [1]:
2CollectDは利用しないので2を選択します。
CollectDをインストールしてない状態で1を選択すると、エラーで起動に失敗します。
- CPU、メモリなどを監視したいですか?
Do you want to monitor any host metrics? e.g. CPU, memory, etc.
1. yes
2. no
default choice: [1]:
1今回はディスク使用率のカスタムメトリクスを取得したいので1を選択。
- コアごとのCPUメトリックスを監視したいですか?
Do you want to monitor cpu metrics per core?
1. yes
2. no
default choice: [1]:
2今回はコアごとのCPUメトリックスを監視する必要はないので2を選択。
- ec2のディメンション(ImageId, InstanceId, InstanceType, AutoScalingGroupName)が利用可能であれば、すべてのメトリクスに追加しますか?
Do you want to add ec2 dimensions (ImageId, InstanceId, InstanceType, AutoScalingGroupName) into all of your metrics if the info is available?
1. yes
2. no
default choice: [1]:
1ディメンションが利用可能であれば追加したいので1を選択。
- ec2のディメンション(InstanceId)を集約するか?
Do you want to aggregate ec2 dimensions (InstanceId)?
1. yes
2. no
default choice: [1]:
2今回はメトリクスの集約は必要ないので2を選択。
- メトリクスを何秒間隔で収集するか?
Would you like to collect your metrics at high resolution (sub-minute resolution)? This enables sub-minute resolution for all metrics, but you can customize for specific metrics in the output json file.
1. 1s
2. 10s
3. 30s
4. 60s
default choice: [4]:
4今回は60秒間隔で十分なのでデフォルトの4を選択。
- どのようなデフォルトメトリクス設定をご希望ですか?
Which default metrics config do you want?
1. Basic
2. Standard
3. Advanced
4. None
default choice: [1]:
1今回使用するカスタムメトリクスはBasicで十分取得できるため1を選択。
- 上記の設定に満足していますか?
Are you satisfied with the above config? Note: it can be manually customized after the wizard completes to add additional items.
1. yes
2. no
default choice: [1]:
1問題ないので1を選択。
- 既存のCloudWatch Log Agentはありますか?
Do you have any existing CloudWatch Log Agent (http://docs.aws.amazon.com/AmazonCloudWatch/latest/logs/AgentReference.html) configuration file to import for migration?
1. yes
2. no
default choice: [2]:
2既存のCloudWatch Log Agentはないので2を選択。
- ログファイルを監視しますか?
Do you want to monitor any log files?
1. yes
2. no
default choice: [1]:
2今回はログファイルを監視する必要はないので2を選択。
- 設定したものがJSON形式で提示されます。
Saved config file to /opt/aws/amazon-cloudwatch-agent/bin/config.json successfully.
Current config as follows:
{
"agent": {
"metrics_collection_interval": 60,
"run_as_user": "root"
},
"metrics": {
"append_dimensions": {
"AutoScalingGroupName": "${aws:AutoScalingGroupName}",
"ImageId": "${aws:ImageId}",
"InstanceId": "${aws:InstanceId}",
"InstanceType": "${aws:InstanceType}"
},
"metrics_collected": {
"disk": {
"measurement": [
"used_percent"
],
"metrics_collection_interval": 60,
"resources": [
"*"
]
},
"mem": {
"measurement": [
"mem_used_percent"
],
"metrics_collection_interval": 60
}
}
}
}
Please check the above content of the config.
The config file is also located at /opt/aws/amazon-cloudwatch-agent/bin/config.json.
Edit it manually if needed.- コンフィグをSSMパラメータストアに保存しますか?
Do you want to store the config in the SSM parameter store?
1. yes
2. no
default choice: [1]:
2SSMは利用しないので2を選択。
これでウィザードによる設定は完了です。
次に下記のコマンドでCloudWatchAgentを起動します。
sudo /opt/aws/amazon-cloudwatch-agent/bin/amazon-cloudwatch-agent-ctl -a fetch-config -m ec2 -c file:/opt/aws/amazon-cloudwatch-agent/bin/config.json -s最後に起動できたかの確認のため下記のコマンドを実行します。
systemctl status amazon-cloudwatch-agent.service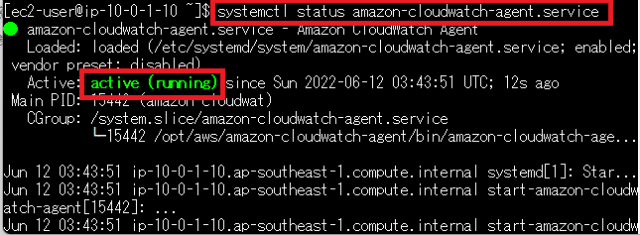
上記より、起動できていることが確認できました。
同じように2台目のEC2インスタンスのCloudWatchAgentも起動します。
5.CloudWatch Alarm作成
EC2にシステムエラーが起きてないか、EBSのディスク使用率が限界に近づいてないかを監視するために、CloudWatchを作成します。
5-1.CloudWatchAlarm(オートリカバリー)
システムエラー時に通知と復旧を行うアラームを作成します。
ソースコードは下記の通りです。
# 1.システムエラー時に通知と復旧を行うアラームを作成
//higa-ec2-1のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA1" {
alarm_name = "higa-CWA1"
alarm_description = "EC2オートリカバリーのアラーム"
metric_name = "StatusCheckFailed_System"
namespace = "AWS/EC2"
statistic = "Maximum"
//指定された統計値が比較される値
period = "60"
//指定された統計値が比較される値
threshold = "1"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
InstanceId = aws_instance.higa-ec2-1.id
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:automate:ap-southeast-1:ec2:recover", "arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "ignore"
tags = {
name = "higa-CWA1"
}
}
//higa-ec2-2のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA2" {
alarm_name = "higa-CWA2"
alarm_description = "EC2オートリカバリーのアラーム"
metric_name = "StatusCheckFailed_System"
namespace = "AWS/EC2"
statistic = "Maximum"
period = "60"
//指定された統計値が比較される値
threshold = "1"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
InstanceId = aws_instance.higa-ec2-2.id
}
evaluation_periods = "2"
alarm_actions = ["arn:aws:automate:ap-southeast-1:ec2:recover", "arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "ignore"
tags = {
name = "higa-CWA2"
}
}設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| alarm_name | higa-CWA1 higa-CWA2 |
アラーム名を設定 |
| alarm_description | EC2オートリカバリーのアラーム | アラームの説明 |
| metric_name | StatusCheckFailed_System | 監視するメトリクスを指定 |
| namespace | AWS/EC2 | 監視するサービスの名前空間を指定 |
| statistic | Maximum | 統計に最大を指定 |
| period | 60 | 迅速なオートリカバリーを考慮し最小値 |
| threshold | 1 | 1以上でエラー状態とするため |
| comparison_operator | GreaterThanOrEqualToThreshold | 1以上でエラー状態とするため |
| dimensions | 別途記載 | ディメンションは、メトリクスのアイデンティティの一部である名前と値のペア |
| evaluation_periods | 2 | 2回データポイントが越えた時アラーム状態にする |
| alarm_actions | ["arn:aws:automate:ap-southeast-1:ec2:recover", "arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"] |
通知と復旧のアクションを指定 |
| treat_missing_data | ignore | アラーム後のデータ欠落時はなんらかのエラーが起きていることが予想されるため |
| tags | name = "higa-CWA1","higa-CWA2" | タグを入力 |
dimensionsの設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| InstanceId | aws_instance.higa-ec2-1.id aws_instance.higa-ec2-2.id |
インスタンスIDを指定 |
5-2.EC2ディスク監視
EBSのディスクに負荷がかかってないかを監視し、ディスク使用率が70%以上の時にメールで通知をするアラームを作成します。
ソースコードは下記の通りです。
#2.EC2ディスク監視 → EBSのディスクに負荷がかかってないかを監視(ディスク使用率が70%以上の時にメールで通知)
//higa-ec2-1のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA3" {
alarm_name = "higa-CWA3"
alarm_description = "EC2ディスクの監視アラーム"
metric_name = "disk_used_percent"
namespace = "CWAgent"
statistic = "Average"
//時間(秒)
period = "300"
//指定された統計値が比較される値
threshold = "70"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
path = "/"
InstanceId = aws_instance.higa-ec2-1.id
ImageId = aws_instance.higa-ec2-1.ami
InstanceType = aws_instance.higa-ec2-1.instance_type
device = "xvda1"
fstype = "xfs"
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "missing"
tags = {
name = "higa-CWA3"
}
}
//higa-ec2-2のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA4" {
alarm_name = "higa-CWA4"
alarm_description = "EC2ディスクの監視アラーム"
metric_name = "disk_used_percent"
namespace = "CWAgent"
statistic = "Average"
//時間(秒)
period = "300"
//指定された統計値が比較される値
threshold = "70"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
path = "/"
InstanceId = aws_instance.higa-ec2-2.id
ImageId = aws_instance.higa-ec2-2.ami
InstanceType = aws_instance.higa-ec2-.instance_type
device = "xvda1"
fstype = "xfs"
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "missing"
tags = {
name = "higa-CWA4"
}
}設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| alarm_name | higa-CWA3 | アラーム名を設定 |
| alarm_description | EC2ディスクの監視アラーム | アラームの説明 |
| metric_name | disk_used_percent | 監視するメトリクスを指定 |
| namespace | CWAgent | 監視するサービスの名前空間を指定 |
| statistic | Average | 統計に平均を指定 |
| period | 300 | 緊急性がないのでデフォルト値 |
| threshold | 70 | 70%以上でエラー状態とするため |
| comparison_operator | GreaterThanOrEqualToThreshold | 70%以上でエラー状態とするため |
| dimensions | 別途記載 | ディメンションは、メトリクスのアイデンティティの一部である名前と値のペア |
| evaluation_periods | 2 | 2回データポイントが越えた時アラーム状態にする |
| alarm_actions | ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"] | 通知のアクションを指定 |
| treat_missing_data | missing | データ欠落時はデータが欠落していると表示されても問題ないため |
| tags | name = "higa-CWA3" ,"higa-CWA4" | タグを入力 |
dimensionsの設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| path | / | パスの指定 |
| InstanceId | aws_instance.higa-ec2-1.id aws_instance.higa-ec2-2.id |
インスタンスIDを指定 |
| ImageId | aws_instance.higa-ec2-1.ami aws_instance.higa-ec2-2.ami |
イメージIDを指定 |
| InstanceType | aws_instance.higa-ec2-1.instance_type aws_instance.higa-ec2-2.instance_type |
インスタンスタイプを指定 |
| device | xvda1 | デバイスを指定 |
| fstype | xfs | fstypeを指定 |
5-3.EC2死活監視
EC2が問題なく動作しているか監視するアラームを作成します。
ソースコードは下記の通りです。
# 3.EC2死活監視 → EC2が問題なく動作しているか監視するアラームを作成
//higa-ec2-1のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA5" {
alarm_name = "higa-CWA5"
alarm_description = "EC2死活監視のアラーム"
metric_name = "StatusCheckFailed"
namespace = "AWS/EC2"
statistic = "Maximum"
//時間(秒)
period = "60"
//指定された統計値が比較される値
threshold = "1"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
InstanceId = aws_instance.higa-ec2-1.id
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "missing"
tags = {
name = "higa-CWA5"
}
}
//higa-ec2-2のCWA
resource "aws_cloudwatch_metric_alarm" "higa-CWA6" {
alarm_name = "higa-CWA6"
alarm_description = "EC2死活監視のアラーム"
metric_name = "StatusCheckFailed"
namespace = "AWS/EC2"
statistic = "Maximum"
//時間(秒)
period = "60"
//指定された統計値が比較される値
threshold = "1"
comparison_operator = "GreaterThanOrEqualToThreshold"
dimensions = {
InstanceId = aws_instance.higa-ec2-2.id
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "missing"
tags = {
name = "higa-CWA6"
}
}設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| alarm_name | higa-CWA5 higa-CWA6 |
アラーム名を設定 |
| alarm_description | EC2死活監視のアラーム | アラームの説明 |
| metric_name | StatusCheckFailed | 監視するメトリクスを指定 |
| namespace | AWS/EC2 | 監視するサービスの名前空間を指定 |
| statistic | Maximum | 統計に最大を指定 |
| period | 60 | 迅速なオートリカバリーを考慮し最小値 |
| threshold | 1 | 1以上でエラー状態とするため |
| comparison_operator | GreaterThanOrEqualToThreshold | 1以上でエラー状態とするため |
| dimensions | 別途記載 | ディメンションは、メトリクスのアイデンティティの一部である名前と値のペア |
| evaluation_periods | 2 | 2回データポイントが越えた時アラーム状態にする |
| alarm_actions | ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"] | 通知と復旧のアクションを指定 |
| treat_missing_data | missing | アラーム後のデータ欠落時はなんらかのエラーが起きていることが予想されるため |
| tags | name = "higa-CWA5" ,"higa-CWA6" | タグを入力 |
dimensionsの設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| InstanceId | aws_instance.higa-ec2-1.id aws_instance.higa-ec2-2.id |
インスタンスIDを指定 |
5-4.ALB死活監視
ALBの分散対象のEC2が正常かどうかを監視するアラームを作成します。
ソースコードは下記の通りです。
# 4.ALB死活監視 → ALBの分散対象のEC2が正常かどうかを監視
resource "aws_cloudwatch_metric_alarm" "higa-CWA7" {
alarm_name = "higa-CWA7"
alarm_description = "ALB死活監視のアラーム"
metric_name = "HealthyHostCount"
namespace = "AWS/ApplicationELB"
statistic = "Minimum"
//時間(秒)
period = "60"
//指定された統計値が比較される値
threshold = "1"
comparison_operator = "LessThanOrEqualToThreshold"
dimensions = {
TargetGroup = aws_lb_target_group.higa-TGN.arn_suffix
LoadBalancer = aws_lb.higa-ALB.arn_suffix
}
//2回データポイントが越えた時アラーム状態にする
evaluation_periods = "2"
alarm_actions = ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"]
treat_missing_data = "missing"
tags = {
name = "higa-CWA7"
}
}設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| alarm_name | higa-CWA7 | アラーム名を設定 |
| alarm_description | ALB死活監視のアラーム | アラームの説明 |
| metric_name | HealthyHostCount | 監視するメトリクスを指定 |
| namespace | AWS/ApplicationELB | 監視するサービスの名前空間を指定 |
| statistic | Minimum | 統計に最小を指定 |
| period | 60 | 迅速なオートリカバリーを考慮し最小値 |
| threshold | 1 | 1以下でエラー状態とするため |
| comparison_operator | LessThanOrEqualToThreshold | 1以下でエラー状態とするため |
| dimensions | 別途記載 | ディメンションは、メトリクスのアイデンティティの一部である名前と値のペア |
| evaluation_periods | 2 | 2回データポイントが越えた時アラーム状態にする |
| alarm_actions | ["arn:aws:sns:ap-southeast-1:【アカウントID】:higa-sns-topic"] | 通知のアクションを指定 |
| treat_missing_data | missing | アラーム後のデータ欠落時はなんらかのエラーが起きていることが予想されるため |
| tags | name = "higa-CWA7" | タグを入力 |
dimensionsの設定項目は下記の通りです。
| 使用するオプション | 設定値 | 説明 |
|---|---|---|
| TargetGroup | aws_lb_target_group.higa-TGN.arn_suffix | ALBのターゲットグループを指定 |
| LoadBalancer | aws_lb.higa-ALB.arn_suffix | ALBの指定 |
6.検証
CloudwatchAgentとCloudwatchAlarm、前回設定したSNSが正常に機能するかの検証を行います。
6-1.CloudWatchAgent起動確認
2つのEC2にSSHで接続して下記のコマンドでCloudWatchAgentの起動を確認します。
systemctl status amazon-cloudwatch-agent.service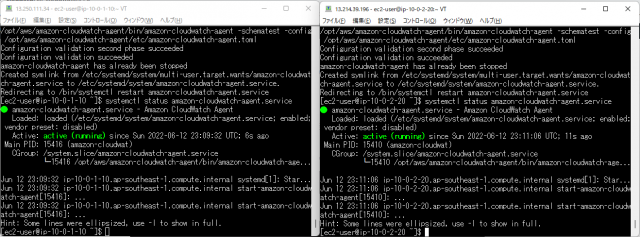
両方のEC2でCloudWatchAgentの起動を確認できました。
6-2.CloudWatchAlarm、SNS動作検証
検証は2つのEC2の片方を停止してHealthyHostCountの値が1になった際、それを監視しているアラームがSNSにアラーム状態になったことのメールを通知し、SNSを通じてエンドポイントのメールアドレス(私のメールアドレス)に配信されるか機能確認します。
①マネジメントコンソール画面からアラームの状態を確認します。
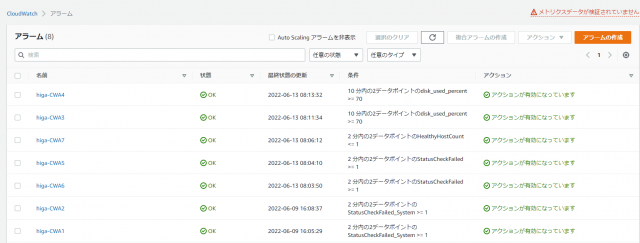
作成したアラームはすべてOK状態です。
②マネジメントコンソール画面から片方のEC2インスタンスを停止します。

③数分時間を置き、アラームの状態を再度確認します。
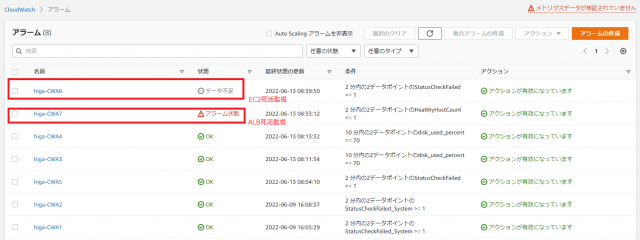
EC2が停止しているため、CW6(EC2が問題なく動作しているか監視するアラーム)は状態が「データ不足」と表示され、CW7(ALBの分散対象のEC2が正常かどうかを監視するアラーム)では「アラーム状態」が確認されました。
④自分のメールアドレスにアラームのメールが配信されているかの確認をします。

自分のメールアドレスに配信されていることを確認できました。
6-3.Disk監視アラーム検証
①EBSのディスクに負荷をかけて使用率を上げます。
SSHでEC2インスタンスに接続して、下記コマンドを実行して、4GBのダミーファイルを作成します。
dd if=/dev/zero of=4G.dummy bs=1MD count=4000②マネジメントコンソール画面からアラーム状態を確認します。
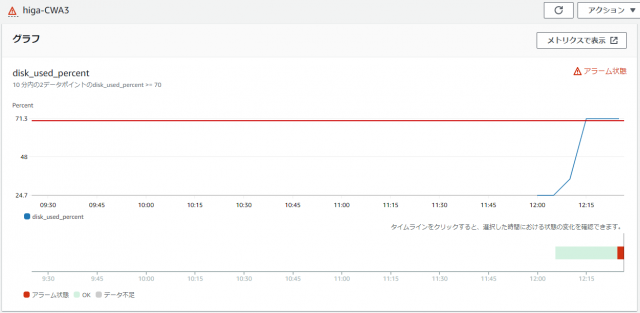
アラーム状態が確認できました。
③最後にメールの通知確認をします。

メール通知の設定も確認できました。
下記コマンドでダミーファイルを削除します。
rm 4G.dummyこれで検証は終了です。
7.まとめ
5-2で作成した「EC2ディスク監視」の作成でTerraformではエラー文が表示されず、問題なくCloudWatchAlarmが作成されたと表示されたのですが、マネジメントコンソール画面から確認すると、うまく設定できていませんでした。
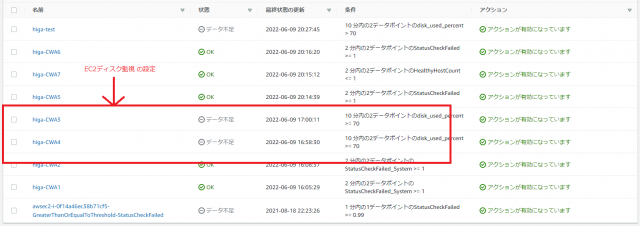
原因としては「dimensions」の設定項目のローマ字表記に問題がありました。(大文字・小文字)
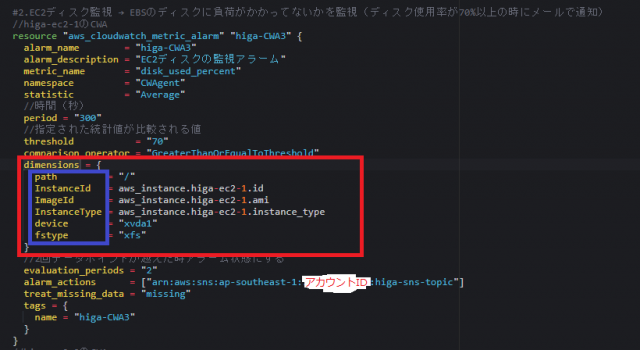
Terraformで構文エラーの表示が出なかったので、解決に至るまでかなり時間がかかりました。
CloudWatchAlarmの作成はマネジメントコンソール画面から行う方が良いと感じました。
8.参考文献
- terraformの公式ドキュメント
Docs overview | hashicorp/aws | Terraform Registry