



この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので十分ご注意ください。
みなさん、こんにちは。株式会社協栄情報クラウド事業本部のショウジです。
今回は、自分の業務で必要になるAWSのAurora(PostgreSQL)をポチポチ触ってみたので、その学習内容を記事にします。
Aurora(PostgreSQL)とは
サクッと概要
AWSで提供されているマネージド型リレーショナルデータベースサービスの一つです。AWSによると、処理能力は、MySQLとの互換性版、PostgreSQLとの互換性版でそれぞれMySQLの最大5倍、PostgreSQLの最大3倍の処理能力を有します。またストレージとして、3AZに6つのデータコピーを行うことでデータの高耐久性を実現し(クラスターボリュームと解釈しました)、Quorumシステムというデータ保存の処理システムを採用することで高い処理性能を実現しています。
Amazon RDS(Relational Database Service)では、以下7つのエンジンからRelational Databaseを選ぶことができます。
①②Amazon Aurora(MySQL互換タイプ と PostgreSQL互換タイプ)
③MySQL
④MariaDB
⑤PostgreSQL
⑥Oracle
⑦SQL Server
Amazon Auroraの料金
また、Amazon Auroraを利用する前に注意しておきたいことですが、Amazon Auroraには無料利用枠がありません。Amazon Aurora の料金
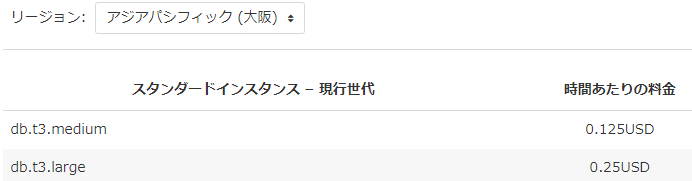
大阪リージョンのAurora PostgreSQLの料金を調べたところ、執筆時点では、db.t3.mediumとdb.t3.largeの2つのみ提供されていたので、安いdb.t3.mediumの方を利用します。
また、データベースを削除するときもスナップショットを残すと、月に0.023UDS/GBかかるようなので、RDS利用後は、必要でない限り削除するようにします。

話の流れが少し変わりますが、AWSで提供されている標準のPostgreSQLとの料金比較もしてみました。
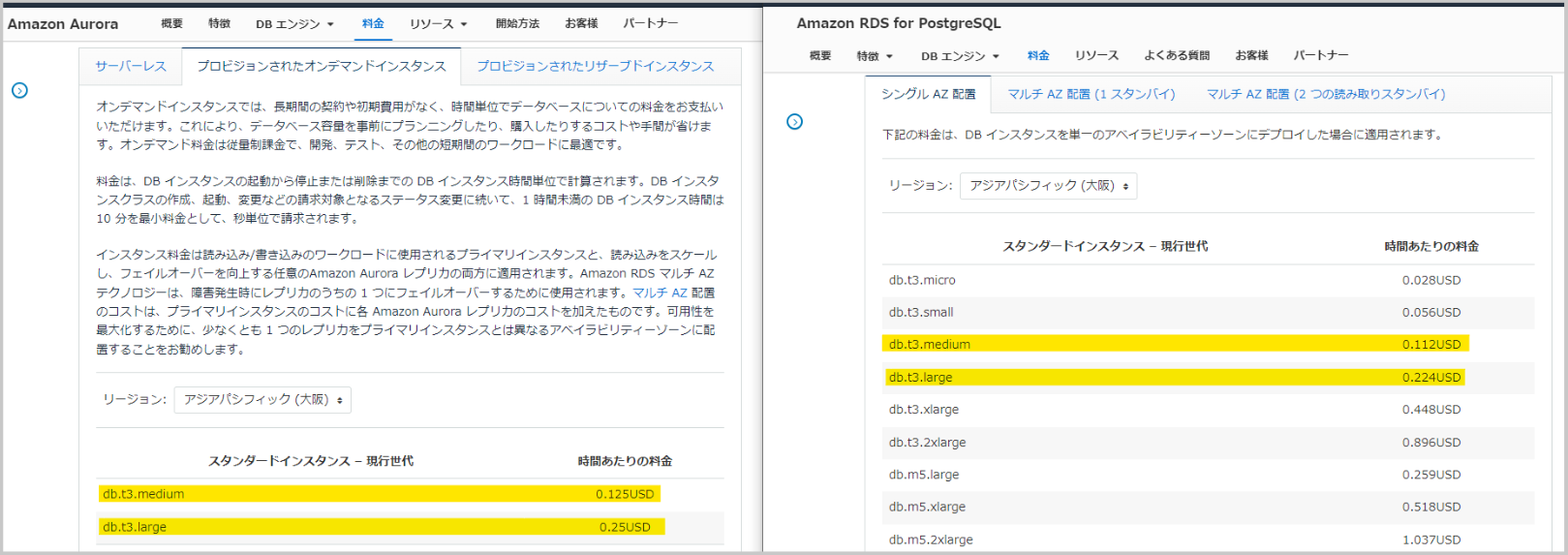
単純比較ですが同じdb.t3.mediumの場合、時間当たりの料金の差が0.013USDなので、無料枠分を除いて考えるとそれほど大きくないのかなと思ったりします。寧ろその差で、最大3倍の処理能力のものを利用できると考えると、性能を求められる業務の場合、人件費等他の諸費用・長期的な利用を考えると実はもの凄くお得なのかもしれないとちょっと想像しました。
Auroraについての他の細かな特徴については、他の方の記事の方が参考になると思いますので、早速、自分のやったハンズオン内容を紹介していきます。
構成図・実施環境
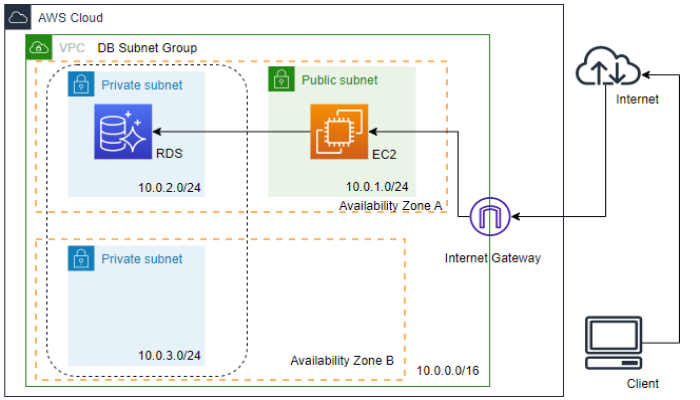
構成図
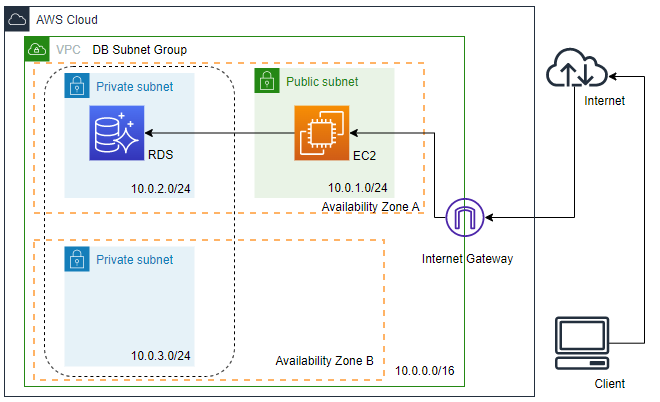
今回は、自分のPCからTeraTermでAWSに作成したVPC内のEC2へSSH接続し、そこからプライベートサブネットに作成したAurora PostgreSQLへログインします。
実施環境
・自身の利用端末のOSエディション:Windows10
・SSH接続に利用するエミュレータ:TeraTerm
・AWS上で使うEC2インスタンス:無料枠のAmazon Linux2
・設定するAurora PostgreSQLのバージョン:PostgreSQL13.7
環境構築
まず、以下の設定でVPCを構築します。下の通りAWSコンソール画面から今回は大阪リージョンで作成していきます。
(AWSコンソールより VPC>お使いのVPC>VPCを作成)
| 設定項目 | 設定値 | 備考 |
|---|---|---|
| IPv4 CIDR ブロック | 10.0.0.0/16 | 利用していないプライベートアドレスを手動で設定(RFC1918) |
| 名前タグ | Test-vpc-sh | 任意で設定 |
※記載していない項目は、デフォルト値のままとします。

作成できました。
サブネット作成
作ったVPC内にそれぞれEC2を入れるパブリック用サブネットを1つ、RDS用のプライベート用サブネットを2つ作ります。
(VPC>サブネットサブネットを作成)

↑のように作成しました。CIDRブロックを24としたので、第3オクテット(IPv4 10.0.X.0のXのところ)でネットワークを区分する番号を振りました。
※補足 AWSでは各サブネット毎に予約されているIPアドレスがあり、例えば、/24の場合、下IPアドレスは利用することができません。(/24の場合、各サブネット毎で利用できるネットワーク数は、下の5つを除く251となります)
- 10.0.0.0: ネットワークアドレス
- 10.0.0.1: AWS が VPC ルータ用に予約
- 10.0.0.2: AWS がDNSサーバ用に予約
- 10.0.0.3: 将来の利用のため(?)
- 10.0.0.255: ネットワークブロードキャストアドレス
インターネットゲートウェイ作成
パブリックサブネットにあるEC2インスタンスとVPC外部からSSH接続でアクセスするための接続点が必要なので、インターネットゲートウェイ(以下IGW)を作成し、VPCへアタッチしていきます。IGWは名前と他のタグを任意で設定します。
(VPC>インターネットゲートウェイ>インターネットゲートウェイの作成)
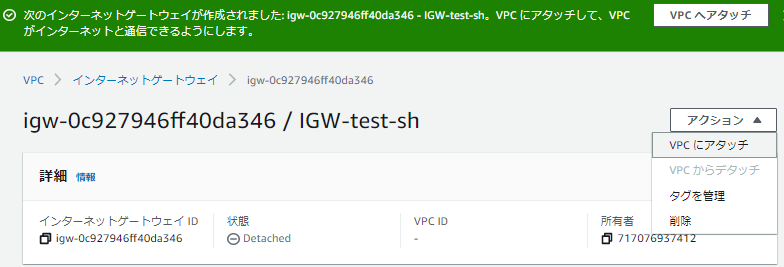
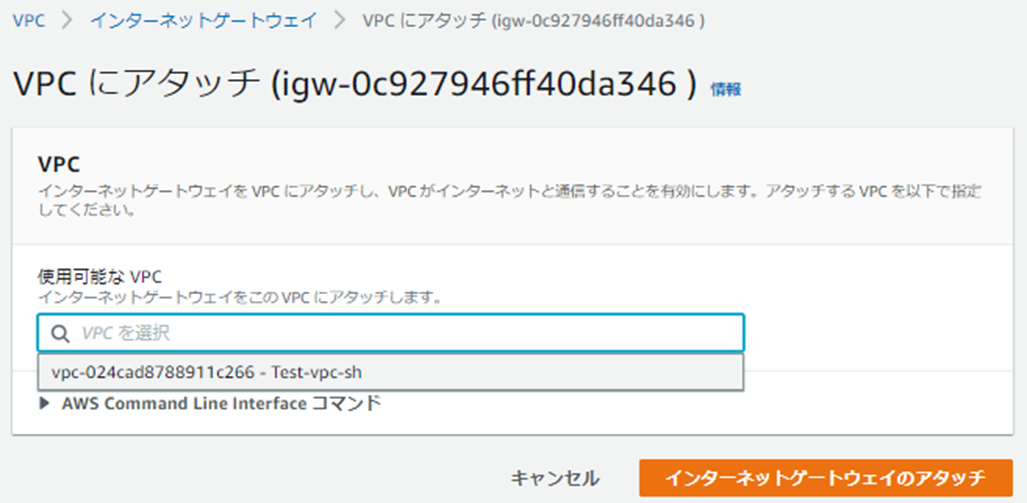
作成後、[VPCへアタッチ]
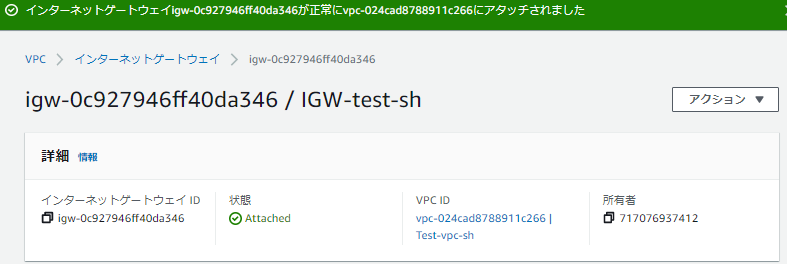
アタッチできました。
ルートテーブル作成
作成したIGWとパブリック用サブネットをつなげるルートテーブルを作ります。
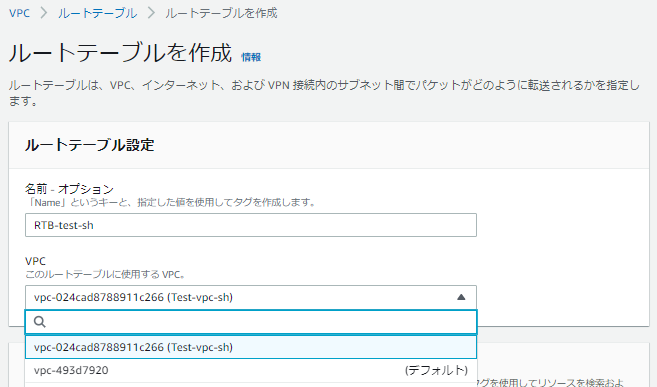
作成したルートテーブルにIGWのルート設定、パブリック用サブネットとの関連付けをしていきます。
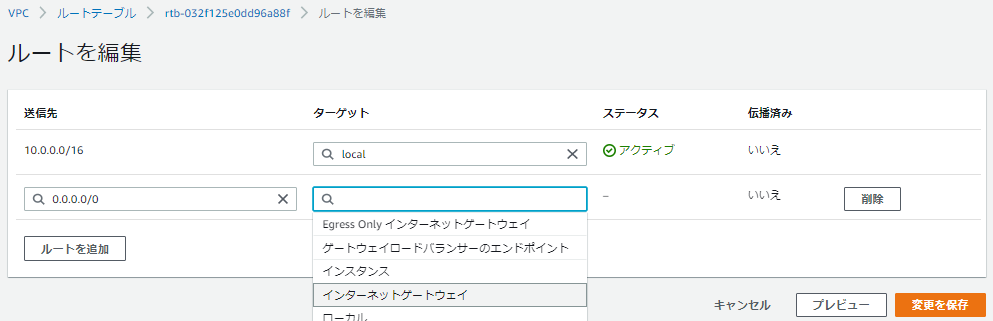
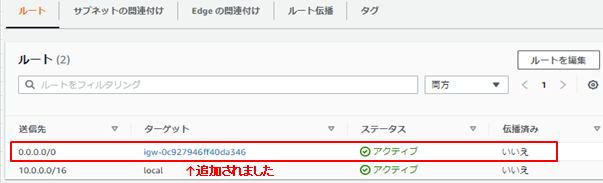
サブネットの関連付けの方も設定します。
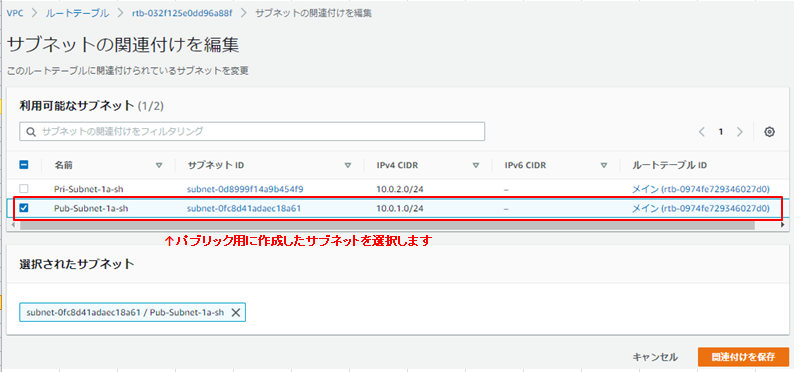
パブリックサブネットができました。
セキュリティグループ作成
セキュリティグループ(以下SG)を①EC2用、②RDS用でそれぞれ設定をしていきます。
| No | セキュリティグループ名 | タイプ | プロトコル | ポート範囲 | ソース種類 | ソース | 備考 |
|---|---|---|---|---|---|---|---|
| ① | SG-EC2-sh | SSH | TCP | 22 | マイIP | 自身のIPアドレス | IPアドレスはAWSより自動割り当て |
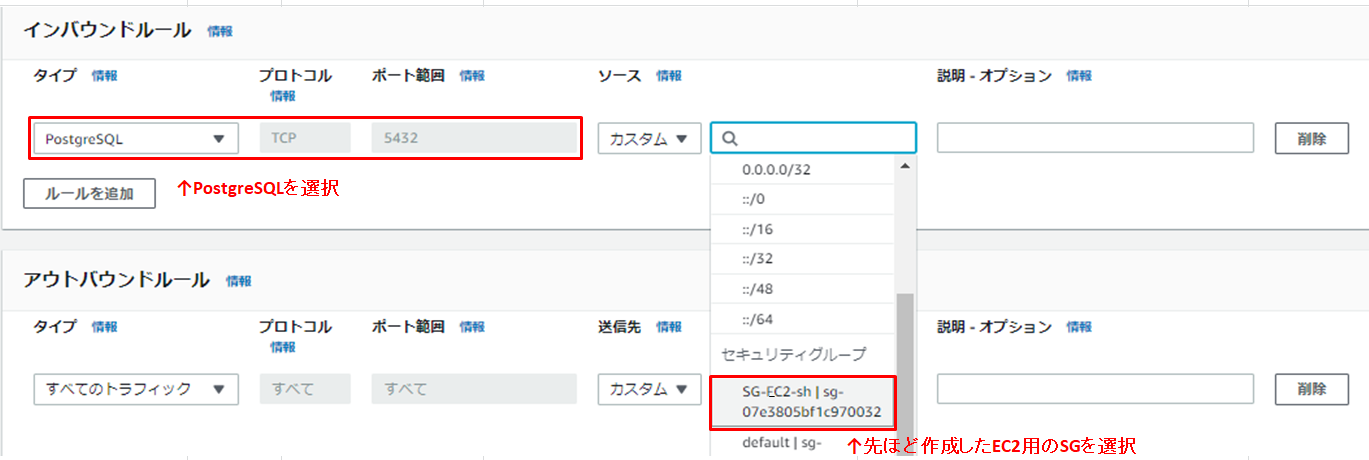
| ② | SG-RDS-sh | PostgreSQL | TCP | 5432 | カスタム | SG-EC2-sh | 作成したEC2用のSGを選択 |
①EC2用SGの作成
EC2へはSSHアクセスをするのみのため、その設定をします。

作成したSGを送信先として設定しておくと、インスタンスの終了・再起動でIPアドレスが変わってもそのままアクセスすることができます。
②RDS用SGの作成
RDS用のSGはAurora PostgreSQLへのポートのみ開く設定をします。
EC2インスタンス作成
EC2インスタンスを作成していきます。
(EC2>インスタンス>インスタンスを起動)
| 設定項目 | 設定値 | 備考 |
|---|---|---|
| 名前 | EC2-test-sh | 任意で設定 |
| アプリケーションおよび OS イメージ | AmazonLinux2 AMI | 無料枠のものを使用 |
| インスタンスタイプ | t2.micro | 無料枠のものを使用 |
| Key pair | "Key-test-sh"を選択 | 作成したものを選択 |
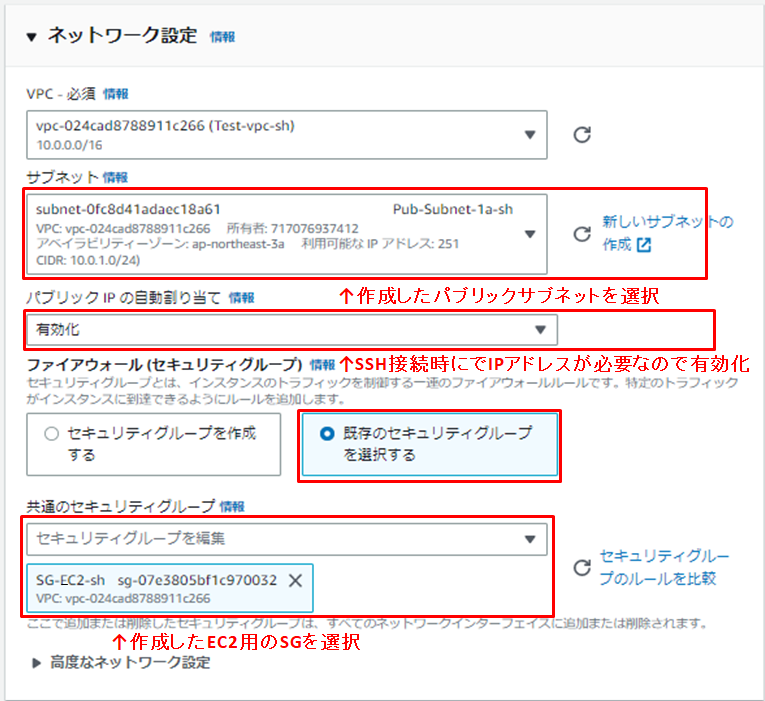
| VPC | "Test-vpc-sh" | 作成したものを選択 |
| サブネット | "Pub-Subnet-1a-sh" | 作成したものを選択 |
| パブリック IP の自動割り当て | 有効化 | VPCの外からSSHで接続するため |
| セキュリティグループ | "SG-EC2-sh" | 作成したものを選択 |
| ボリュームタイプ | gp3 | 同じ無料枠のgp2より安価なため |
上記で記載のない部分はデフォルト値で設定していきます。
Key Pair作成のところは、"Create new key pair"より作成します。
作成したものはSSHアクセス時に必要になるので、保管しておきます。
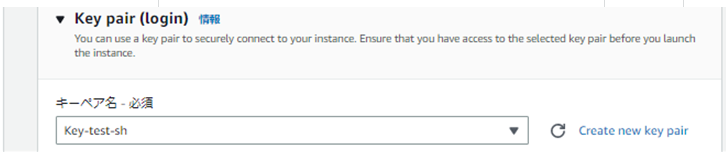
キーペアは以下の設定で作成しました。
| 項目 | 設定値 | 備考 |
|---|---|---|
| キーペア名 | "Key-test-sh" | 任意の値を入力 |
| キーペアのタイプ | RSA | デフォルト値 |
| プライベートキーファイル形式 | .pem | デフォルト値 |
ネットワーク設定のところは、以下のように設定します。
EC2インスタンスへSSH接続確認
インスタンスの作成ができたら、RDSを作成する前にTeraTermでSSH接続確認をしていきます。
TeraTermを立ち上げると、↓のような画面になるので、ホストに起動したEC2インスタンスのパブリックIPアドレスを入力します。
パブリックIPアドレスは以下のところで確認ができます。
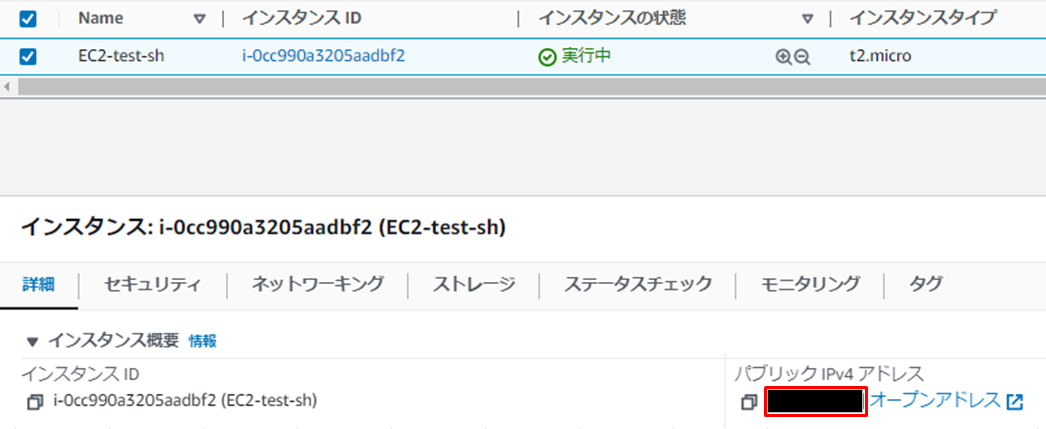
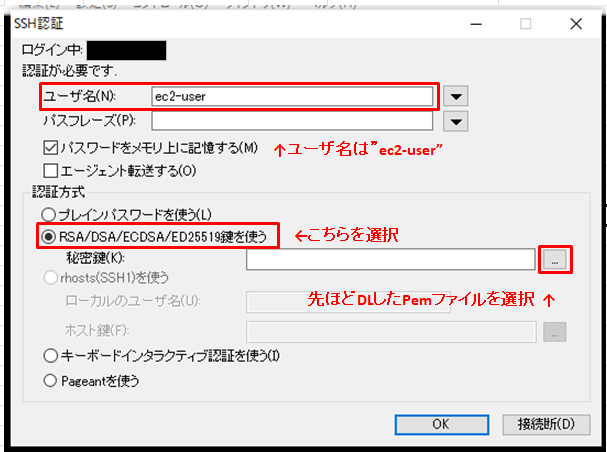
正しいIPを入力し[OK]を押すと、セキュリティ警告の画面が表示されます。そのまま[続行]をクリックし、接続できると以下の画面となります。
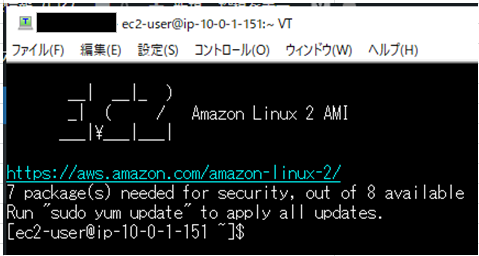
問題なく接続できたので、以下の接続画面が表示されました。
RDS
DBサブネットグループ作成
さて、RDSからAurora PostgreSQLを作成していきます。先にDBのサブネットグループを以下の設定で作成していきます。
(RDS>サブネットグループ>DBサブネットグループを作成)
DBサブネットグループの設定
| 設定項目 | 設定値 | 理由 |
|---|---|---|
| 名前 | "DB-Subnet-GRP-test-sh" | 任意で設定 |
| 説明 | "Subnet GRP for DB" | 分かる内容で記載 |
| VPC | "Test-vpc-sh" | 任意で設定 |
| アベイラビリティーゾーン | "ap-northeast-3a"と"ap-northeast-3b" | サブネットを作成したゾーンを選択 |
| サブネット | "10.0.2.0/24"と"10.0.3.0/24" | 作成したプライベートサブネットを選択 |
RDSを利用してわかったのですが、RDSインスタンスを利用する場合は、シングルAZ構成で環境構築をする場合でも、サブネットグループの利用(2つ以上のサブネットの用意)が必要となります。
1つのサブネットだけで作成しようとすると、↓のように注意されます。

RDSユーザガイドのVPC 内のDB インスタンスの使用でしっかりと記載されていました。
VPC では、少なくとも 2 つのサブネットを指定する必要があります。これらのサブネットは、DB インスタンスをデプロイする AWS リージョン 内の 2 つの異なるアベイラビリティーゾーンに存在している必要があります。
今回はプライベートサブネットを2つ作成していたので、DBサブネットグループを作成することができました。

RDS(Aurora PostgreSQL)作成
DBサブネットグループが作成できたので、データベースを作成していきます。
(RDS>データベースの作成)
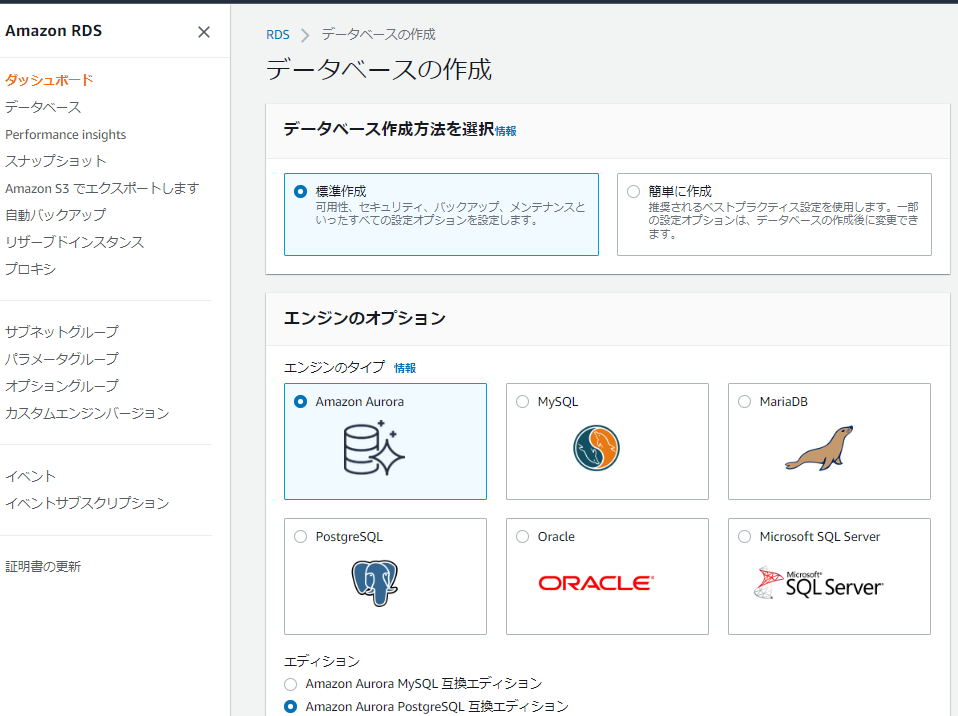
Amazon Auroraの設定
| 設定項目 | 設定値 | 理由 |
|---|---|---|
| エディション | Amazon Aurora PostgreSQL 互換エディション | デフォルト値(MySQL互換エディション)から変更 |
| テンプレート | 開発/テスト | デフォルト値(本番稼働用)から変更 |
| DBクラスター識別子 | "db-test-sh" | 任意で設定 |
| マスターユーザー名 | "postgresSH" | 任意で設定 |
| マスターパスワード | "postgresSH" | 任意で設定 |
| DBインスタンスクラス | バースト可能クラス(db.t3.mediumを選択) | ハンズオンのため(安いものを選択) |
| マルチAZ配置 | Auroraレプリカを作成しない | ハンズオンのため |
| VPC | "Test-vpc-sh" | 作成したVPCを利用 |
| データベース名 | DBTestSh | 任意で設定 |
↑の部分でマスターユーザ名やパスワードは、作成後は表示されず、PostgreSQLログインや操作の際に必要になるので、忘れないようにします。データベース名もログイン時に必要なので追加設定の項目から設定します。その他、記載していない設定値については、今回はAurora PostgreSQLへのログインと簡単な操作が目的のため、デフォルト値で作成しました。
Aurora(postgreSQL)へ接続
DBを作成したので、TeraTermからEC2へログインし接続していきます。
psqlのインストール
まず、psql(PostgreSQLクライアント)のコマンドインストールが必要なので、amazon-Linux-extrasのパッケージからインストールします。
"amazon-linux-extras"と入力すると下のようにパッケージ一覧が表示されるので、その中にあるpostgreSQLパッケージをインストールします(今回はDB作成時に選んだバージョンと同じ"postgresql13"をインストール)
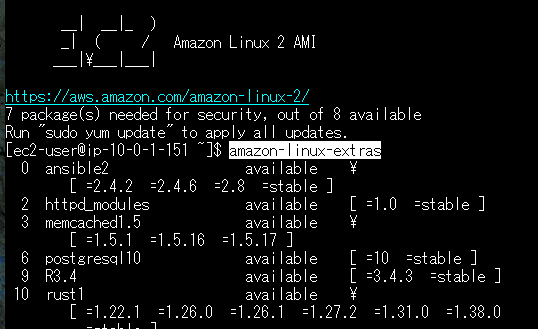
sudo amazon-linux-extras install -y postgresql13
と入力すると、インストールが始まり完了後にパッケージがハイライトされました。

postgreSQLサーバへログイン
構築したpostgreSQLサーバへは、
sudo psql -h ホスト -U ユーザ名 -d データベース名
(その後)
パスワード入力
でログインします。ホストは、AWSコンソールから作成したDBの[接続とセキュリティ]タブで確認できるエンドポイントを入れます。
ログインできると以下のような画面になります。
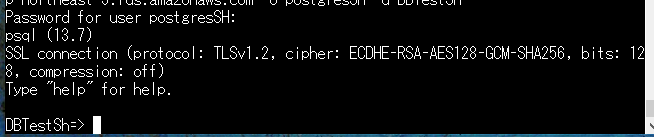
ログインが出来たら以下、サっと試せそうなコマンドになります。
| 操作 | コマンド |
|---|---|
| PostgreSQLから切断・ログアウト | "\q" |
| DBの一覧を表示 | "\l" |
| テーブル一覧を表示 | "\dt" |
データベースはtemplateがあるようですが、テーブルまだ何もないので、以下のコマンドでテーブルを作成してみます。
テーブル作成
CREATE TABLE [テーブル名]([カラム名1 データ型1], [カラム名2 データ型2])
例)CREATE TABLE Fruits(id INT, name VARCHAR(20));
例は、(整数型)INT型のカラムidと、(最大20字までの文字が挿入できる可変長型)VARCHAR型のカラムnameでFruitsという名前のテーブルを作成します。
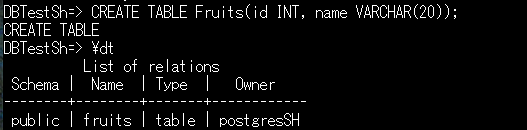
"CREATE TABLE"となり、その後\dtでテーブルが作成されていることが確認できます。

データ挿入
データを複数入力してみます。
INSERT INTO [Table name]([Column1], [Column2],...) VALUES([Data1], [Data2],...),([Data1],[Data2],...);
例)INSERT INTO fruits(id, name) VALUES(001,’Apple’),(002,’Banana’),(003,’Melon’);

挿入できたので、↑のような表示となりました。
データ表示
以下のようにテーブル名と確認したいカラム名を指定して、挿入されたデータを確認します。
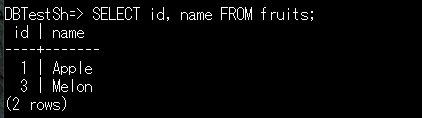
SELECT カラム名のリスト FROM テーブル名;
例)SELECT id, name FROM fruits;

↑のように入力されたデータが確認できました。
レコードの削除
特定のレコード(Row)を削除したい時は、↓のように書きます。
DELETE FROM テーブル名 WHERE 条件;
例)DELETE FROM fruits WHERE id = ‘002’;

↑DELETE 1と表示され、SELECTでテーブルデータを表示すると、id=2のBananaが削除されていました。
WHEREで条件を付けない場合は、全レコードの削除となります。
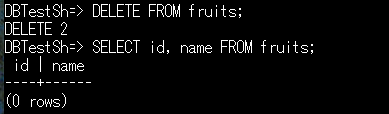
↑の通り、条件を綱内DELETEコマンドで全てのレコードが削除されました。
ログアウト
postgreSQLからログアウトします。

終わりに
SAAの試験勉強をしていた時は、「Auroraは、標準のMySQLと比べて5倍、標準のPostgreSQLと比べて3倍性能がいい」って何となく暗記していたのですが、Auroraのバージョンとして「MySQL互換版」と「PostgreSQL互換版」があることや、DBのサブネットグループの作成条件、お金の話など、実際に触ってみることで学べることが多く理解も深めることができました。PostgreSQLについてはまだまだ勉強時間が足りないので、OJTと併せて、学習を進めていきます。
参考文献・URL
・『PostgreSQL全機能バイブル』
・Amazon Aurora with PostgreSQL Compatibility における運用設計のファーストステップ | AWS Summit Tokyo 2019
・AWS公式ホームページ